Quick note: I received a free license for NDepend to try it out and share my experience. All opinions in this blog post are on my own.
From O2DES.Net to Ea
In 2019, I had the honour of working closely with the team behind the O2DES.NET during my time working at the C4NGP research center in NUS, where I spent around two and a half years. After I left the team in 2022, O2DES.NET has not been actively updated on their GitHub public repository and it is still targeting at .NET Standard 2.1.
While .NET Standard 2.1 is not as old as the .NET Framework, it is considered somewhat outdated compared to the latest .NET versions. In the article “The Future of .NET Standard” written by Immo Landwerth, .NET Standard has been largely superseded by .NET 5 (and later versions), which unify these platforms into a single runtime. Hence, moving to .NET 8 is a forward-looking decision that aligns with current and future software development trends.

Hence, in this article, I will walk you through the process of migrating O2DES.NET from targeting .NET Standard 2.1 to supporting .NET 8. To prevent any confusion, I’ve renamed the project to ‘Ea’ because I am no longer the active developer of O2DES.NET. Throughout this article, ‘Ea’ will refer to the version of the project updated to .NET 8.
In this migration journey, I will be relying on NDepend, a static code analysis tool for .NET developers.
Show Me the Code!
The complete source code of my project after migrating O2DES.NET to target at .NET 8 can be found on GitHub at https://github.com/gcl-team/Ea.
About NDepend: Why Do We Need a Static Code Analysis?
Why do we need NDepend, a static code analysis tool?
Static code analysis is a way of automatically checking our code for potential issues without actually running our apps. Think of it like a spell-checker, but for programming, scanning our codebase to find bugs, performance issues, and security vulnerabilities early in the development process.
During the migration of an older library, such as moving O2DES.NET from .NET Standard 2.1 to .NET 8, the challenges can add up. We are expected to run into outdated code patterns, performance bottlenecks, or even compatibility issues.

NDepend is designed to help with this by performing a deep static analysis of the entire codebase. It gives us detailed reports on code quality, shows where our dependencies are, and highlights areas that need attention. We can then focus on modernising the code with confidence, knowing that we are not likely introducing new bugs or performance issues as we are updating the codebase.
NDepend also helps enforce good coding practices by pointing out issues like overly complex methods, dead code, or potential security vulnerabilities. With features like code metrics, dependency maps, and rule enforcement, it acts as a guide to help us write better, more maintainable code.
Bringing Down Debt from 6.22% to 0.35%
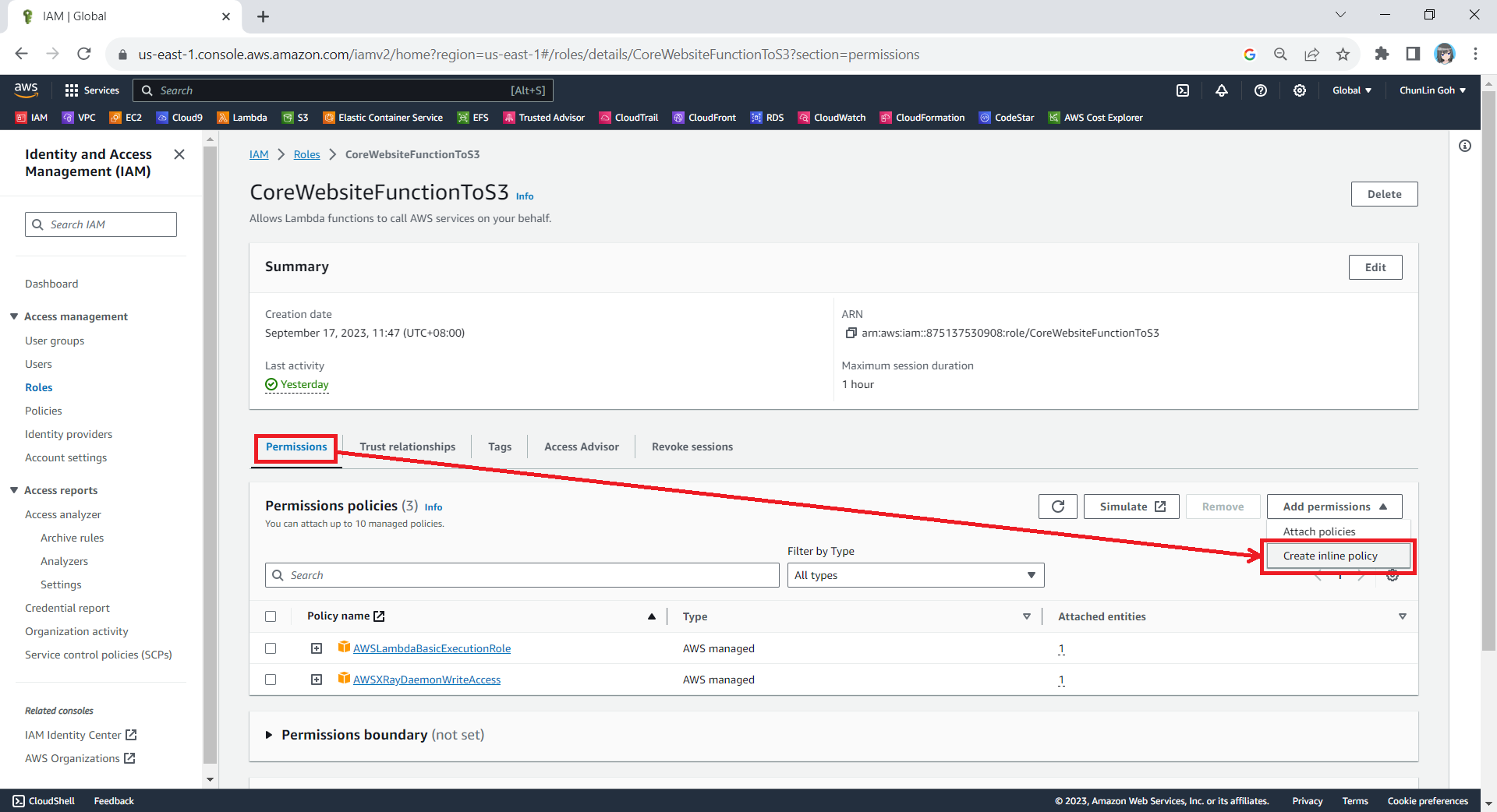
One of the standout features of NDepend is its comprehensive dashboard, which I heavily rely on to get an overview of the entire O2DES.NET codebase.

From code quality metrics to technical debt, the dashboard presents critical insights in a visual and easy-to-understand format. Having all this information in one place is indeed invaluable to us during the migration project.
To help us better understand how much effort is needed to fix or improve the codebase, NDepend uses the Debt Ratio and Debt Rating, both of which are part of the SQALE method.

In the book, the SQALE method for Managing Technical Debt written by Jean-Louis Letouzey, SQALE stands for Software Quality Assessment based on Life Expectations. SQALE is a method used to assess and manage technical debt in software projects. In the context of NDepend, the SQALE method is used to calculate the Debt Ratio and Debt Rating:
Debt Ratio: The percentage of effort needed to fix the technical debt compared to rewriting the code from scratch.
Debt Rating: A letter-based rating (A to E) derived from the Debt Ratio to give a quick overview of the severity of technical debt.
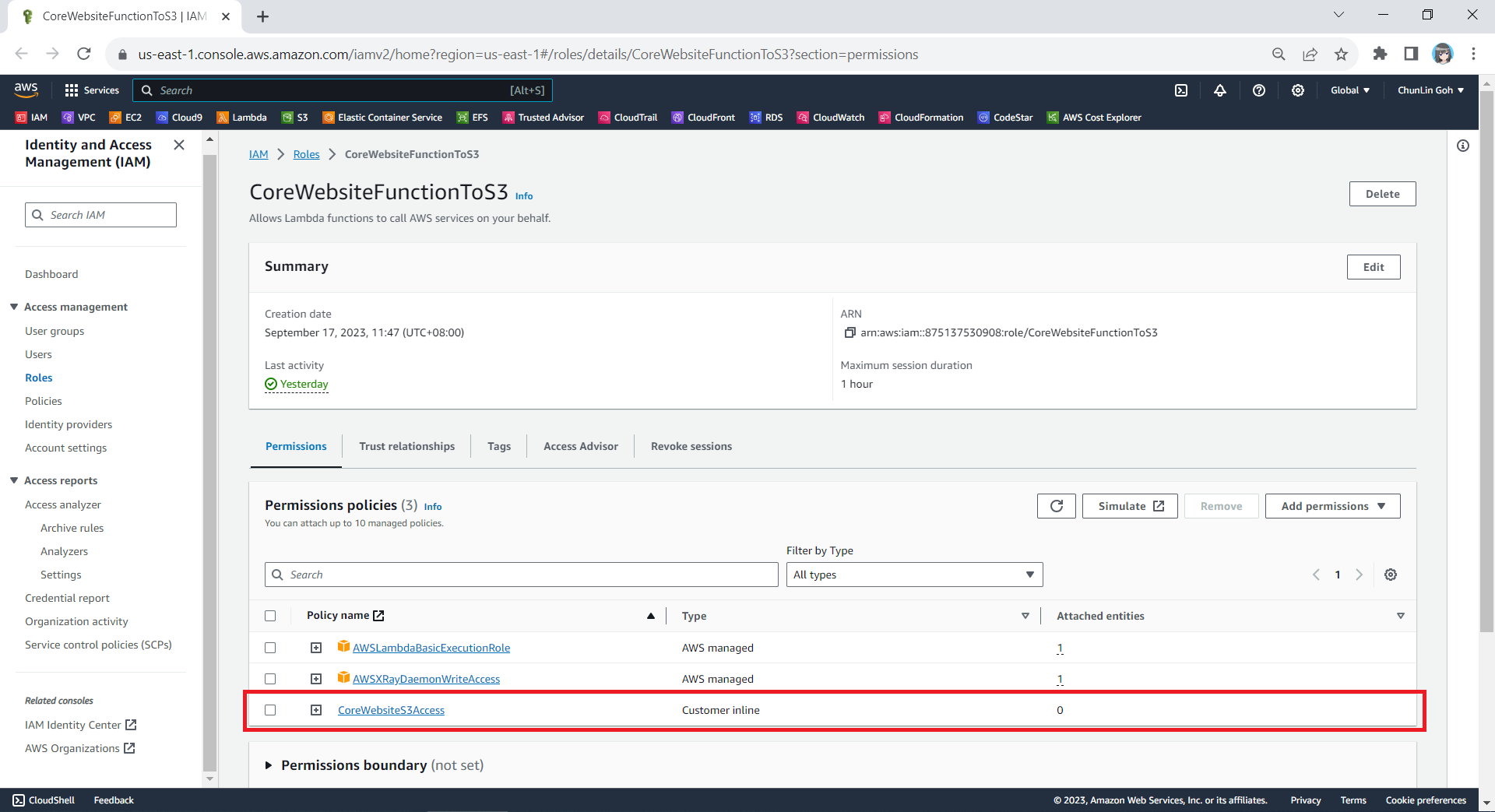
As shown in one of the earlier screenshots, Ea has a Debt Ratio of 6.22% and a B rating. This means that its technical debt is considered moderate and manageable. Nevertheless, it is a signal that it is now time we should start addressing the identified issues before they accumulate.
After just two weeks of code cleanup, we successfully reduced Ea’s Debt Ratio from 6.22% to an impressive 0.35%, elevating its rating to an A. This significant improvement not only enhances the overall quality of the codebase but also positions Ea for better maintainability.

Issues and Trends
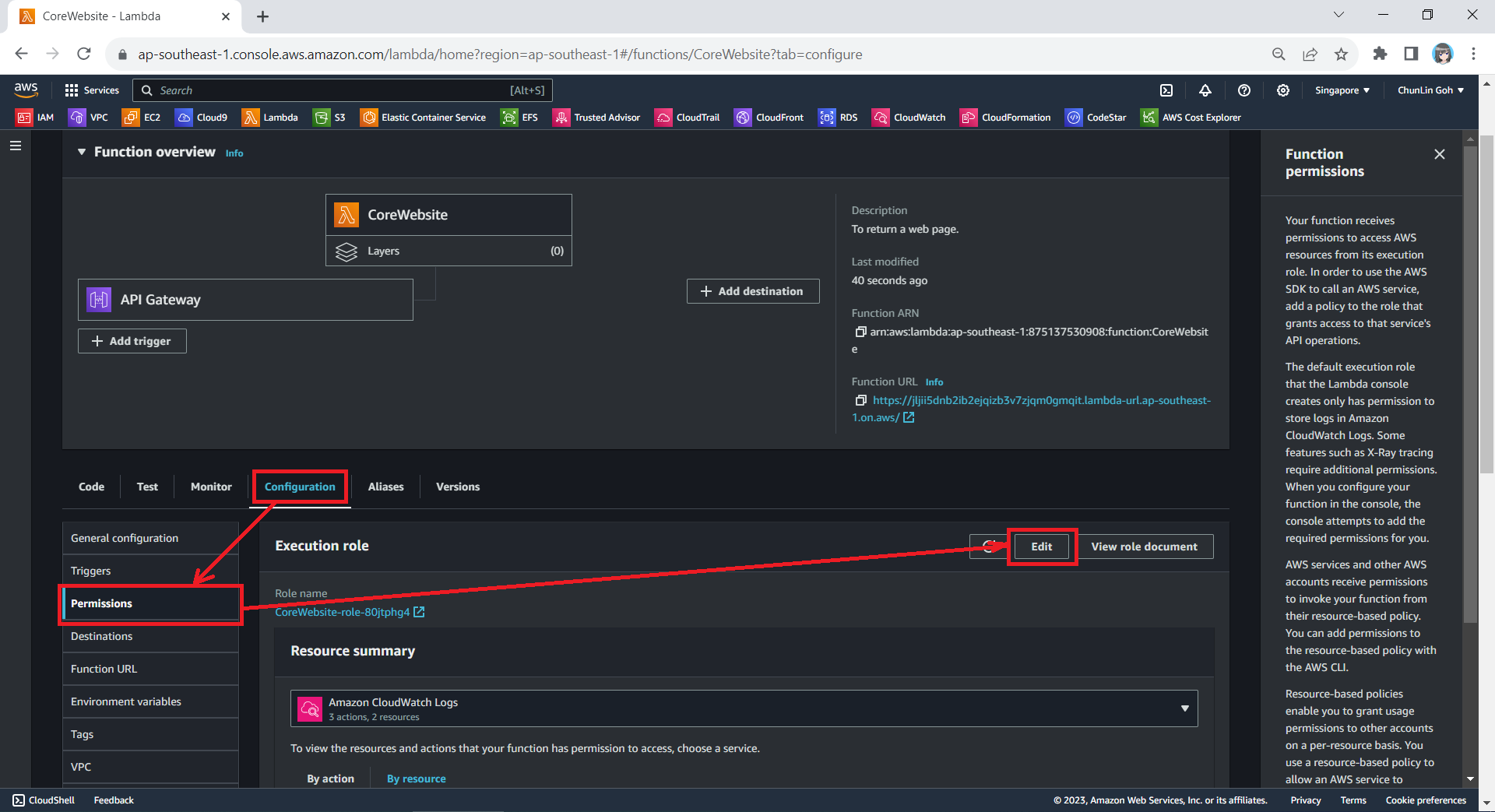
In Visual Studio, NDepend also provides interactive UI which indicates the number of critical rules violated and critical issues to solve. Unlike most of the static code analysis tools that show overwhelming number of issues, NDepend has this concept of baseline.
When we first set up an NDepend project, the very first analysis of our code becomes the “baseline.” This baseline serves as a starting point, capturing the current state of our code. As we continue to work on the project, future analyses will be compared against this baseline. The idea is to track how our code changes over time so that we can focus on knowing whether we are improving or introducing more issues to the codebase while we are changing it.

As shown in the screenshot above, those new issues added since the baseline need to be our priority to fix. This is to make sure the newly written code and refactored code will remain clean.
In fact, when fixing the issues, I get to learn from the NDepend rules. When we click on the numbers, we will be shown the corresponding issues. Then clicking on each of the issue will show us the detailed information about it. For example, as shown in the screenshot below, when we click on one of the green numbers, it shows us a list of issues that have been fixed by us.

When we click on the red numbers, as shown in the following screenshot, we will get to see the new issues that we need to fix. The following example shows how the original O2DES.NET has some methods declared with high visibility unnecessarily.

By default, the dashboard also comes with some helpful trend charts. These charts give us a visual overview of how our codebase is evolving over time.

These charts give us a visual overview of how our codebase is evolving over time. For those new to static code analysis, think of these charts as the “health check” of the project. During the migration, they help us to track important metrics, like code coverage, issues, or technical debt, and show how they change with each analysis.
Code Dependency Graphs
NDepend offers a Dependency Graph. It is used to visually represent the relationships between different components such as namespaces and classes within our codebase. The graph helps us understand how tightly coupled our code is and how different parts of our codebase depend on each other.
When we are refactoring Ea during the migration, we depend on the Dependency Graph to visually shows us how the different parts of the codebase are connected. We use the insight provided by Dependency Graph to plan how to split components, which will then make the code easier to manage.

As shown in the diagram above, we can see a graph made of some entangled classes which are connected with a red bi-directional arrow. This is because in the original O2DES.NET library, there are some classes having circular dependency. This thus makes parts of the code heavily reliant on each other, reducing modularity and making it harder to unit test the code independently.
To further investigate the classes, we can double click the edge between those two classes. Doing so will generate a graph made of methods and fields involved in the dependency between the two classes, as shown in the screenshot below.

This coupling graph is a powerful tool for us as it offers detailed insights into how the two classes interact. This level of detail allows us to focus on the exact code causing the coupling, making it easier to assess whether the dependency is necessary or can be refactored. For instance, if multiple methods are too intertwined, it might be time to extract common logic into a new class or interface.
In addition, the Dependency Matrix is another way to visualise the dependencies between namespaces, classes, or methods. A number in a cell at the intersection of two elements indicates how many times the element in the row depends on the element in the column. This gives us an overview of the dependencies within our codebase.

From the Dependency Matrix above, we first should look for cells with large numbers. This is because having large numbers indicating the two methods are highly dependent on each other. We should review those methods to understand why there is so much interaction and to make sure they are not tightly coupled.
If there is a cycle in the codebase, there will be a red square shown on the Dependency Matrix. We then can refactor by breaking the cycle, possibly by introducing new interfaces or decoupling responsibilities between the methods.
Code Metrics View
In the Code Metric View, each rectangle represents a method. The area of a rectangle is proportional to metrics such as the # lines of codes (LOC), cyclomatic complexity (CC), of the corresponding method, field, type, namespace, or assembly.

During the migration, the tree view format enables us to navigate our codebase and prioritise areas that require refactoring by spotting those methods that are too big and too complex. In addition, to help quickly identify problem areas, NDepend uses colour coding in the tree view. For example, red may indicate high complexity or large size, while green might indicate simpler, more maintainable code.
The tree view is interactive. Right-clicking on the rectangles provides options such as opening the source code declaration for the selected element, allowing us to navigate directly to the method.

Integrating with GitHub Actions
NDepend integrate well with several CI/CD pipelines, making it a valuable tool for maintaining code quality throughout the development lifecycle. It can automatically analyse our code after each build. This ensures that every change in our codebase adheres to defined quality standards before the merge to main branch.
NDepend comes with Quality Gates that enforce standards such as unfixed critical issues. If the code fails to meet the required thresholds, the build can fail in the pipelines.
In NDepend, Quality Gates are predefined sets of code quality criteria that our project must meet before it is considered acceptable for deployment. They serve as automated checkpoints to help ensure that our code maintains a certain standard of quality, reducing technical debt and promoting maintainability.

As shown in the screenshot above, NDepend provides detailed reports on issues and violations after each build. We can also download the detailed report from the CI servers, such as GitHub Actions. These reports help us quickly identify where issues exist in our code.

The NDepend report is divided into seven sections, each providing detailed insights into various aspects of your codebase:
- Overview: It gives a high-level view of the overall code quality and metrics, similar to what is displayed in the NDepend Dashboard within Visual Studio.
- Issues: A list of source files with unresolved issues. Along with the number of issues, it also shows the “Debt” for each file, which represents the estimated man-time required to resolve the issues.
- Projects: Similar to the Issues section but focuses on projects instead of individual files. It displays the total issues and associated debt at the project level.
- Rules: This section highlights the violated rules, showing the issues and debt in terms of the rules that have been broken. It’s another way to assess code quality by focusing on adherence to coding standards.
- Quality Gates: This section mirrors the Quality Gates you might have seen earlier in the CI/CD pipelines, such as in GitHub Actions.
- Trend: The Trend section provides a visualisation of trends over time, similar to the trend charts found in the NDepend Dashboard in Visual Studio.
- Logs: This section contains the logs generated during NDepend analysis.

As described in the NDpend documentation, it has complete support for Azure DevOps, meaning it can be seamlessly integrated into the CI/CD pipelines without a lot of manual setup. We thus can easily configure NDepend to run as part of our Azure Pipelines, generating code quality reports after each build.
For our Ea project, since it is an open-source project hosted on GitHub, we can also integrate NDepend with our GitHub Actions instead.
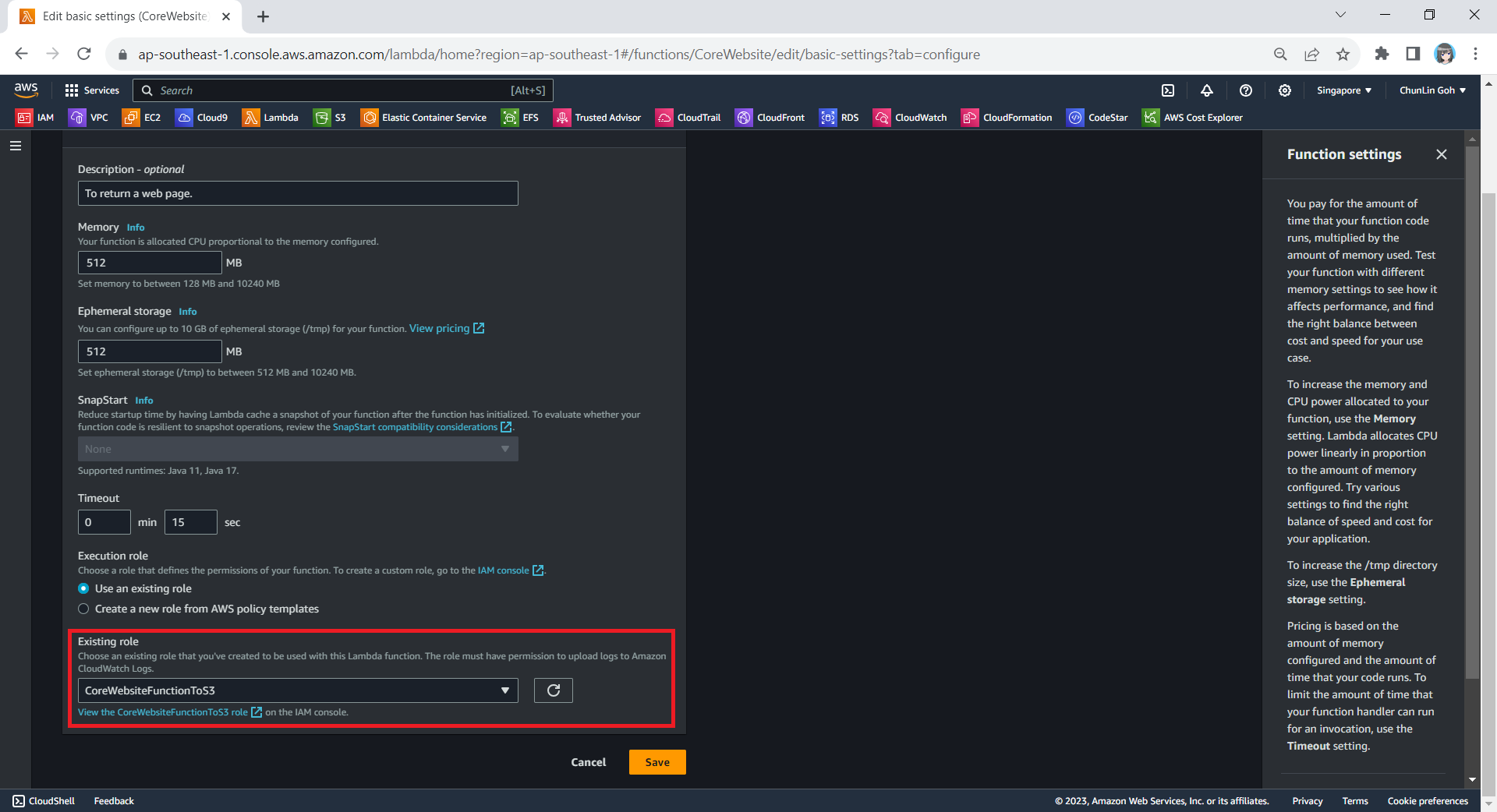
To integrate with GitHub Actions, firstly, we need to get associate our NDepend license with our GitHub account (or a copy of 28-day trial activation data). To link the NDepend license (eg. ABC012345) with our GitHub account, we will need to visit the link: “https://www.ndepend.com/activation_githubaction?license=ABC012345”, as demonstrated in the screenshot below.

To introduce NDepend to our GitHub Actions workflow, the very least configuration that we need to add is as follows.
- name: NDepend
uses: ndepend/ndepend-action@ndependv1.0
with:
license: ${{ secrets.NDependLicense }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
Read More: Complete Build YAML of Ea
Wrap-Up
In conclusion, NDepend has proven to be an invaluable tool in our journey to modernise and maintain the Ea library.
By offering comprehensive static code analysis, insightful metrics, and seamless integration with CI/CD pipelines like GitHub Actions, it empowers us to catch issues early, reduce technical debt, and ensure a high standard of code quality.
NDepend provides the guidance and clarity needed to ensure our code remains clean, efficient, and maintainable. For any .NET individual or development team serious about improving code quality, NDepend is definitely a must-have in the toolkit.