Pinecone worked well, but as the project grew, I wanted more control, something open-source, and a cheaper option. That is when I found pgvector, a tool that adds vector search to PostgreSQL and gives the flexibility of an open-source database.
About HSR and Relic Recommendation System
Honkai: Star Rail (HSR) is a popular RPG that has captured the attention of players worldwide. One of the key features of the game is its relic system, where players equip their characters with relics like hats, gloves, or boots to boost stats and unlock special abilities. Each relic has unique attributes, and selecting the right sets of relics for a character can make a huge difference in gameplay.
As a casual player, I often found myself overwhelmed by the number of options and the subtle synergies between different relic sets. Finding the good relic combination for each character was time-consuming.
This is where LLMs like Gemini come into play. With the ability to process and analyse complex data, Gemini can help players make smarter decisions.
In November 2024, I started a project to develop a Gemini-powered HSR relic recommendation system which can analyse a player’s current characters to suggest the best options for them. In the project, I have been storing embeddings in Pinecone.
Embeddings and Vector Database
An embedding is a way to turn data, like text or images, into a list of numbers called a vector. These vectors make it easier for a computer to compare and understand the relationships between different pieces of data.
For example, in the HSR relic recommendation system, we use embeddings to represent descriptions of relic sets. The numbers in the vector capture the meaning behind the words, so similar relics and characters have embeddings that are closer together in a mathematical sense.
This is where vector databases like Pinecone or pgvector come in. Vector databases are designed for performing fast similarity searches on large collections of embeddings. This is essential for building systems that need to recommend, match, or classify data.
pgvector is an open-source extension for PostgreSQL that allows us to store and search for vectors directly in our database. It adds specialised functionality for handling vector data, like embeddings in our HSR project, making it easier to perform similarity searches without needing a separate system.
Unlike managed services like Pinecone, pgvector is open source. This meant we could use it freely and avoid vendor lock-in. This is a huge advantage for developers.
Finally, since pgvector runs on PostgreSQL, there is no need for additional managed service fees. This makes it a budget-friendly option, especially for projects that need to scale without breaking the bank.
Choosing the Right Model
While the choice of the vector database is important, it is not the key factor in achieving great results. The quality of our embeddings actually is determined by the model we choose.
For my HSR relic recommendation system, when our embeddings were stored in Pinecone, I started by using the multilingual-e5-large model from Microsoft Research offered in Pinecone.
When I migrated to pgvector, I had the freedom to explore other options. For this migration, I chose the all-MiniLM-L6-v2 model hosted on Hugging Face, which is a lightweight sentence-transformer designed for semantic similarity tasks. Switching to this model allowed me to quickly generate embeddings for relic sets and integrate them into pgvector, giving me a solid starting point while leaving room for future experimentation.
The all-MiniLM-L6-v2 model hosted on Hugging Face.
Using all-MiniLM-L6-v2 Model
Once we have decided to use the all-MiniLM-L6-v2 model, the next step is to generate vector embeddings for the relic descriptions. This model is from the sentence-transformers library, so we first need to install the library.
pip install sentence-transformers
The library offers SentenceTransformer class to load pre-trained models.
from sentence_transformers import SentenceTransformer
model_name = 'all-MiniLM-L6-v2' model = SentenceTransformer(model_name)
At this point, the model is ready to encode text into embeddings.
The SentenceTransformer model takes care of tokenisation and other preprocessing steps internally, so we can directly pass text to it.
# Function to generate embedding for a single text def generate_embedding(text): # No need to tokenise separately, it's done internally # No need to average the token embeddings embeddings = model.encode(text)
return embeddings
In this function, when we call model.encode(text), the model processes the text through its transformer layers, generating an embedding that captures its semantic meaning. The output is already optimised for tasks like similarity search.
Setting up the Database
After generating embeddings for each relic sets using the all-MiniLM-L6-v2 model, the next step is to store them in the PostgreSQL database with the pgvector extension.
Here, a dimension refers to one of the “features” that helps describe something. When we talk about vectors and embeddings, each dimension is just one of the many characteristics used to represent a piece of text. These features could be things like the type of words used, their relationships, and even the overall meaning of the text.
Updating the Database
After the table is created, we can proceed to create INSERT INTO SQL statements to insert the embeddings and their associated text into the database.
In this step, I load the relic information from a JSON file and process it.
import json
# Load your relic set data from a JSON file with open('/content/hsr-relics.json', 'r') as f: relic_data = json.load(f)
# Prepare data relic_info_data = [ {"id": relic['name'], "text": relic['two_piece'] + " " + relic['four_piece']} # Combine descriptions for relic in relic_data ]
The relic_info_data will then be passed to the following function to generate the INSERT INTO statements.
# Function to generate INSERT INTO statements with vectors def generate_insert_statements(data): # Initialise list to store SQL statements insert_statements = []
for record in data: # Extracting text and id from the record id = record.get('id') text = record.get('text')
# Generate the embedding for the text embedding = generate_embedding(text)
# Convert the embedding to a list embedding_list = embedding.tolist()
# Create the SQL INSERT INTO statement sql_statement = f""" INSERT INTO embeddings (id, vector, text) VALUES ( '{id.replace("'", "''")}', ARRAY{embedding_list}, '{text.replace("'", "''")}') ON CONFLICT (id) DO UPDATE SET vector = EXCLUDED.vector, text = EXCLUDED.text; """
# Append the statement to the list insert_statements.append(sql_statement)
return insert_statements
The embeddings of the relic sets are successfully inserted to the database.
How It All Fits Together: Query the Database
Once we have stored the vector embeddings of all the relic sets in our PostgreSQL database, the next step is to find the relic sets that are most similar to a given character’s relic needs.
Just like what we have done for storing relic set embeddings, we need to generate an embedding for the query describing the character’s relic needs. This is done by passing the query through the model as demonstrated in the following code.
The generated embedding is an array of 384 numbers. We simply use this array in our SQL query below.
SELECT id, text, vector <=> '[<embedding here>]' AS distance FROM embeddings ORDER BY distance LIMIT 3;
The key part of the query is the <=> operator. This operator calculates the “distance” between two vectors based on cosine similarity. In our case, it measures how similar the query embedding is to each stored embedding. The smaller the distance, the more similar the embeddings are.
We use LIMIT 3 to get the top 3 most similar relic sets.
Test Case: Finding Relic Sets for Gallagher
Gallagher is a Fire and Abundance character in HSR. He is a sustain unit that can heal allies by inflicting a debuff on the enemy.
According to the official announcement, Gallagher is a healer. (Image Source: Honkai: Star Rail YouTube)
The following screenshot shows the top 3 relic sets which are closely related to a HSR character called Gallagher using the query “Suggest the best relic sets for this character: Gallagher is a Fire and Abundance character in Honkai: Star Rail. He can heal allies.”
The returned top 3 relic sets are indeed recommended for Gallagher.
One of the returned relic sets is called the “Thief of Shooting Meteor”. It is the official recommended relic set in-game, as shown in the screenshot below.
Gallagher’s official recommended relic set.
Future Work
In our project, we will not be implementing indexing because currently in HSR, there are only a small number of relic sets. Without an index, PostgreSQL will still perform vector similarity searches efficiently because the dataset is small enough that searching through it directly will not take much time. For small-scale apps like ours, querying the vector data directly is both simple and fast.
However, when our dataset grows larger in the future, it is a good idea to explore indexing options, such as the ivfflat index, to speed up similarity searches.
On a chilly November morning, I attended the Google DevFest 2024 in Singapore. Together with my friends, we attended a workshop titled “Gemini Masterclass: How to Unlock Its Power with Prompting, Functions, and Agents.” The session was led by two incredible speakers, Martin Andrews and Sam Witteveen.
Martin, who holds a PhD in Machine Learning and has been an Open Source advocate since 1999. Sam is a Google Developer Expert in Machine Learning. Both of them are also organisers of the Machine Learning Singapore Meetup group. Together, they delivered an engaging and hands-on workshop about Gemini, the advanced LLM from Google.
Thanks to their engaging Gemini Masterclass, I have taken my first steps into the world of LLMs. This blog post captures what I learned and my journey into the fascinating world of Gemini.
Martin Andrews presenting in Google DevFest 2024 in Singapore.
About LLM and Gemini
LLM stands for Large Language Model. To most people, an LLM is like a smart friend who can answer almost all our questions with responses that are often accurate and helpful.
As a LLM, Gemini is trained on large amount of text data and can perform a wide range of tasks: answering questions, writing stories, summarising long documents, or even helping to debug code. What makes them special is their ability to “understand” and generate language in a way that feels natural to us.
Many of my developer friends have started using Gemini as a coding assistant in their IDEs. While it is good at that, Gemini is much more than just a coding tool.
Gemini is designed to not only respond to prompts but also act as an assistant with an extra set of tools. To make the most of Gemini, it is important to understand how it works and what it can (and cannot) do. With the knowledge gained from the DevFest workshop, I decided to explore how Gemini could assist with optimising relic choices in a game called Honkai: Star Rail.
Honkai: Star Rail and Gemini for Its Relic Recommendations
Honkai: Star Rail (HSR) is a popular RPG that has captured the attention of players worldwide. One of the key features of the game is its relic system, where players equip their characters with relics like hats, gloves, or boots to boost stats and unlock special abilities. Each relic has unique attributes, and selecting the right sets of relics for a character can make a huge difference in gameplay.
As a casual player, I often found myself overwhelmed by the number of options and the subtle synergies between different relic sets. Finding the good relic combination for each character was time-consuming.
This is where LLMs like Gemini come into play. With the ability to process and analyse complex data, Gemini can help players make smarter decisions.
In this blog post, I will briefly show how this Gemini-powered relic recommendation system can analyse a player’s current characters to suggest the best options for them. Then it will also explain the logic behind its recommendations, helping us to understand why certain relics are ideal.
Setup the Project
To make my project code available to everyone, I used Google Colab, a hosted Jupyter Notebook service that requires no setup to use and provides free access to computing resources, including GPUs and TPUs. You can access my code by clicking on the button below.
In my project, I used the google-generativeai Python library, which is pre-installed in Colab. This library serves as a user-friendly API for interacting with Google LLMs, including Gemini. It makes it easy for us to integrate Gemini capabilities directly into our code.
Next, we will need to import the necessary libraries.
Importing the libraries and setup Gemini client.
The first library to import is definitely the google.generativeai. Without it, we cannot interact with Gemini easily. Then we have google.colab.userdata which securely retrieves sensitive data, like our API key, directly from the Colab notebook environment.
We will also use IPython.display for displaying results in a readable format, such as Markdown.
HONKAI_STAR_RAIL_PLAYER_ID: Your HSR player UID. It is used later to personalise relic recommendations.
GOOGLE_API_KEY: The API key that we can get from Google AI Studio to authenticate with Gemini.
Creating and retrieving our API keys in Google AI Studio.
Once we have initialised the google.generativeai library with the GOOGLE_API_KEY, we can proceed to specify the Gemini model we will be using.
The choice of model is crucial in LLM projects. Google AI Studio offers several options, each representing a trade-off between accuracy and cost. For my project, I choose models/gemini-1.5-flash-8b-001, which provided a good balance for this experiment. Larger models might offer slightly better accuracy but at a significant cost increase.
Google AI Studio offers a range of models, from smaller, faster models suitable for quick tasks to larger, more powerful models capable of more complex processing.
Hallucination and Knowledge Limitation
We often think of LLMs like Gemini as our smart friends who can answer any question. But just like even our smartest friend can sometimes make mistakes, LLMs have their limits too.
Gemini knowledge is based on the data it was trained on, which means it doesn’t actually know everything. Sometimes, it might hallucinate, i.e. model invents information that sounds plausible but not actually true.
Kiana is not a character from Honkai: Star Rail but she is from another game called Honkai Impact 3rd.
While Gemini is trained on a massive dataset, its knowledge is not unlimited. As a responsible AI, it acknowledges its limitations. So, when it cannot find the answer, it will tell us that it lacks the necessary information rather than fabricating a response. This is how Google builds safer AI systems, as part of its Secure AI Framework (SAIF).
Knowledge cutoff in action.
To overcome these constraints, we need to employ strategies to augment the capabilities of LLMs. Techniques such as integrating Retrieval-Augmented Generation (RAG) and leveraging external APIs can help bridge the gap between what the model knows and what it needs to know to perform effectively.
System Instructions
Leveraging System Instructions is a way to improve the accuracy and reliability of Gemini responses.
System instructions are prompts given before the main query in order to guide Gemini. These instructions provide crucial context and constraints, significantly enhancing the accuracy and reliability of the generated output.
System Instruction with contextual information about HSR characters ensures Gemini has the necessary background knowledge.
The specific design and phrasing of the system instructions provided to the Gemini is crucial. Effective system instructions provide Gemini with the necessary context and constraints to generate accurate and relevant responses. Without carefully crafted system instructions, even the most well-designed prompt can yield poor results.
Context Framing
As we can see from the example above, writing clear and effective system instructions requires careful thought and a lot of testing.
This is just one part of a much bigger picture called Context Framing, which includes preparing data, creating embeddings, and deciding how the system retrieves and uses that data. Each of these steps needs expertise and planning to make sure the solution works well in real-world scenarios.
You might have heard the term “Prompt Engineering,” and it sounds kind of technical, but it is really about figuring out how to ask the LLM the right questions in the right way to get the best answers from an LLM.
While context framing and prompt engineering are closely related and often overlap, they emphasise different aspects of the interaction with the LLM.
Stochasticity
While experimenting with Gemini, I noticed that even if I use the exact same prompt, the output can vary slightly each time. This happens because LLMs like Gemini have a built-in element of randomness , known as Stochasticity.
Lingsha, an HSR character released in 2024. (Image Credit: Game8)
For example, when querying for DPS characters, Lingsha was inconsistently included in the results. While this might seem like a minor variation, it underscores the probabilistic nature of LLM outputs and suggests that running multiple queries might be needed to obtain a more reliable consensus.
Lingsha was inconsistently included in the response to the query about multi-target DPS characters.
According to the official announcement, even though Lingsha is a healer, she can cause significant damage to all enemies too. (Image Source: Honkai: Star Rail YouTube)
Hence, it is important to treat writing efficient system instruction and prompt as iterative processes. so that we can experiment with different phrasings to find what works best and yields the most consistent results.
Temperature Tuning
We can also reduce the stochasticity of Gemini response through adjusting parameters like temperature. Lower temperatures typically reduce randomness, leading to more consistent outputs, but also may reduce creativity and diversity.
Temperature is an important parameter for balancing predictability and diversity in the output. Temperature, a number in the range of 0.0 to 2.0 with default to be 1.0 in gemini-1.5-flash model, indicates the probability distribution over the vocabulary in the model when generating text. Hence, a lower temperature makes the model more likely to select words with higher probabilities, resulting in more predictable and focused text.
Having Temperature=0 means that the model will always select the most likely word at each step. The output will be highly deterministic and repetitive.
Function Calls
A major limitation of using system instructions alone is their static nature.
For example, my initial system instructions included a list of HSR characters, but this list is static. The list does not include newly released characters or characters specific to the player’s account. In order to dynamically access a player’s character database and provide personalised recommendations, I integrated Function Calls to retrieve real-time data.
For fetching the player’s HSR character data, I leveraged the open-source Python library mihomo. This library provides an interface for accessing game data, enabling dynamic retrieval of a player’s characters and their attributes. This dynamic data retrieval is crucial for generating truly personalised relic recommendations.
Using the mihomo library, I retrieve five of my Starfaring Companions.
Defining the functions in my Python code was only the first step. To use function calls, Gemini needed to know which functions were available. We can provide this information to Gemini as shown below.
model = genai.GenerativeModel('models/gemini-1.5-flash-8b-001', tools=[get_player_name, get_player_starfaring_companions])
The correct function call is picked up by Gemini based on the prompt.
Using descriptive function names is essential for successful function calling with LLMs because the accuracy of function calls depends heavily on well-designed function names in our Python code. Inaccurate naming can directly impact the reliability of the entire system.
If our Python function is named incorrectly, for example, calling a function get_age but it returns the name of the person, Gemini might select that function wrongly when the prompt is asking for age.
After Gemini telling us which function to call, our code needs to call the function to get the result.
Grounding with Google Search
Function calls are a powerful way to access external data, but they require pre-defined functions and APIs.
To go beyond these limits and gather information from many online sources, we can use Gemini grounding feature with Google Search. This feature allows Gemini to google and include what it finds in its answers. This makes it easier to get up-to-date information and handle questions that need real-time data.
If you are getting the HTTP 429 errors when using the Google Search feature, please make sure you have setup a billing account here with enough quota.
With this feature enabled, we thus can ask Gemini to get some real-time data from the Internet, as shown below.
The upcoming v2.7 patch of HSR is indeed scheduled to be released on 4th December.
Building a Semantic Knowledge Base with Pinecone
System instructions and Google search grounding provide valuable context, but a structured knowledge base is needed to handle the extensive data about HSR relics.
Having explored system instructions and Google search grounding, the next challenge is to manage the extensive data about HSR relics. We need a way to store and quickly retrieve this information, enabling the system to generate timely and accurate relic recommendations. Thus we will need to use a vector database ideally suited for managing the vast dataset of relic information.
Vector databases, unlike traditional databases that rely on keyword matching, store information as vectors enabling efficient similarity searches. This allows for retrieving relevant relic sets based on the semantic meaning of a query, rather than relying solely on keywords.
There are many options for vector database, but I choose Pinecone. Pinecone, a managed service, offered the scalability needed to handle the HSR relic dataset and the robust API essential for reliable data access. Its availability of a free tier is also a significant factor because it allows me to keep costs low during the development of my project.
API keys in Pinecone dashboard.
Pinecone’s well-documented API and straightforward SDK make integration surprisingly easy. To get started, simply follow the Pinecone documentation to install the SDK in our code and retrieve the API key.
# Import the Pinecone library from pinecone.grpc import PineconeGRPC as Pinecone from pinecone import ServerlessSpec import time
# Initialize a Pinecone client with your API key pc = Pinecone(api_key=userdata.get('PINECONE_API_KEY'))
I prepare my Honkai: Star Rail relic data, which I have previously organised into a JSON structure. This data includes information on each relic set’s two-piece and four-piece effects. Here’s a snippet to illustrate the format:
[ { "name": "Sacerdos' Relived Ordeal", "two_piece": "Increases SPD by 6%", "four_piece": "When using Skill or Ultimate on one ally target, increases the ability-using target's CRIT DMG by 18%, lasting for 2 turn(s). This effect can stack up to 2 time(s)." }, { "name": "Scholar Lost in Erudition", "two_piece": "Increases CRIT Rate by 8%", "four_piece": "Increases DMG dealt by Ultimate and Skill by 20%. After using Ultimate, additionally increases the DMG dealt by the next Skill by 25%." }, ... ]
With the relic data organised in Pinecone, the next challenge is to enable similarity searches with vector embedding. Vector embedding captures the semantic meaning of the text, allowing Pinecone to identify similar relic sets based on their inherent properties and characteristics.
Now, we can generate vector embeddings for the HSR relic data using Pinecone. The following code snippet illustrates this process which is to convert textual descriptions of relic sets into numerical vector embeddings. These embeddings capture the semantic meaning of the relic set descriptions, enabling efficient similarity searches later.
# Load relic set data from the JSON file with open('/content/hsr-relics.json', 'r') as f: relic_data = json.load(f)
# Prepare data for Pinecone relic_info_data = [ {"id": relic['name'], "text": relic['two_piece'] + " " + relic['four_piece']} # Combine relic set descriptions for relic in relic_data ]
# Generate embeddings using Pinecone embeddings = pc.inference.embed( model="multilingual-e5-large", inputs=[d['text'] for d in relic_info_data], parameters={"input_type": "passage", "truncate": "END"} )
Pinecone ability to perform fast similarity searches relies on its indexing mechanism. Without an index, searching for similar relic sets would require comparing each relic set’s embedding vector to every other one, which would be extremely slow, especially with a large dataset. I choose Pinecone serverless index hosted on AWS for its automatic scaling and reduced infrastructure management.
# Create a serverless index index_name = "hsr-relics-index"
if not pc.has_index(index_name): pc.create_index( name=index_name, dimension=1024, metric="cosine", spec=ServerlessSpec( cloud='aws', region='us-east-1' ) )
# Wait for the index to be ready while not pc.describe_index(index_name).status['ready']: time.sleep(1)
The dimension parameter specifies the dimensionality of the vector embeddings. Higher dimensionality generally allows for capturing more nuanced relationships between data points. For example, two relic sets might both increase ATK, but one might also increase SPD while the other increases Crit DMG. A higher-dimensional embedding allows the system to capture these subtle distinctions, leading to more relevant recommendations.
For the metric parameter which measures the similarity between two vectors (representing relic sets), we use the cosine metric which is suitable for measuring the similarity between vector embeddings generated from text. This is crucial for understanding how similar two relic descriptions are.
With the vector embeddings generated, the next step was to upload them into my Pinecone index. Pinecone uses the upsert function to add or update vectors in the index. The following code snippet shows how we can upsert the generated embeddings into the Pinecone index.
# Target the index where you'll store the vector embeddings index = pc.Index("hsr-relics-index")
# Prepare the records for upsert # Each contains an 'id', the embedding 'values', and the original text as 'metadata' records = [] for r, e in zip(relic_info_data, embeddings): records.append({ "id": r['id'], "values": e['values'], "metadata": {'text': r['text']} })
# Upsert the records into the index index.upsert( vectors=records, namespace="hsr-relics-namespace" )
The code uses the zip function to iterate through both the list of prepared relic data and the list of generated embeddings simultaneously. For each pair, it creates a record for Pinecone with the following attributes.
id: Name of the relic set to ensure uniqueness;
values: The vector representing the semantic meaning of the relic set effects;
metadata: The original description of the relic effects, which will be used later for providing context to the user’s recommendations.
Implementing Similarity Search in Pinecone
With the relic data stored in Pinecone now, we can proceed to implement the similarity search functionality.
def query_pinecone(query: str) -> dict:
# Convert the query into a numerical vector that Pinecone can search with query_embedding = pc.inference.embed( model="multilingual-e5-large", inputs=[query], parameters={ "input_type": "query" } )
# Search the index for the three most similar vectors results = index.query( namespace="hsr-relics-namespace", vector=query_embedding[0].values, top_k=3, include_values=False, include_metadata=True )
return results
The function above takes a user’s query as input, converts it into a vector embedding using Pinecone’s inference endpoint, and then uses that embedding to search the index, returning the top three most similar relic sets along with their metadata.
Relic Recommendations with Pinecone and Gemini
With the integration with Pinecode, we design the initial prompt to pick relevant relic sets from Pinecone. After that, we take the results from Pinecone and combine them with the initial prompt to create a richer, more informative prompt for Gemini, as shown in the following code.
from google.generativeai.generative_models import GenerativeModel
for character_name, (character_avatar_image_url, character_description) in character_relics_mapping.items(): print(f"Processing Character: {character_name}")
prompt = f"User Query: {character_query}\n\nRelevant Relic Sets:\n" for match in pinecone_response['matches']: prompt += f"* {match['id']}: {match['metadata']['text']}\n" # Extract relevant data prompt += "\nBased on the above information, recommend two best relic sets and explain your reasoning. Each character can only equip with either one 4-piece relic or one 2-piece relic with another 2-piece relic. You cannot recommend a combination of 4-piece and 2-piece together. Consider the user's query and the characteristics of each relic set."
The code shows that we are doing both prompt engineering (designing the initial query to get relevant relics) and context framing (combining the initial query with the retrieved relic information to get a better overall recommendation from Gemini).
First the code retrieves data about the player’s characters, including their descriptions, images, and relics the characters currently are wearing. The code then gathers potentially relevant data about each character from a separate data source character_profile which has more information, such as gameplay mechanic about the characters that we got from the Game8 Character List. With the character data, the query will find similar relic sets in the Pinecone database.
After Pinecone returns matches, the code constructs a detailed prompt for the Gemini model. This prompt includes the character’s description, relevant relic sets found by Pinecone, and crucial instructions for the model. The instructions emphasise the constraints of choosing relic sets: either a 4-piece set, or two 2-piece sets, not a mix. Importantly, it also tells Gemini to consider the character’s existing profile and to prioritise fitting relic sets.
Finally, the code sends this detailed prompt to Gemini, receiving back the recommended relic sets.
Knight of Purity Palace, is indeed a great option for Gepard!
Using LLMs like Gemini is sure exciting, but figuring out what is happening “under the hood” can be tricky.
If you are a web developer, you are probably familiar with Grafana dashboards. They show you how your web app is performing, highlighting areas that need improvement.
Langtrace is like Grafana, but specifically for LLMs. It gives us a similar visual overview, tracking our LLM calls, showing us where they are slow or failing, and helping us optimise the performance of our AI app.
Traces for the Gemini calls are displayed individually.
Langtrace is not only useful for tracing our LLM calls, it also offers metrics on token counts and costs, as shown in the following screenshot.
Building this Honkai: Star Rail (HSR) relic recommendation system is a rewarding journey into the world of Gemini and LLMs.
I am incredibly grateful to Martin Andrews and Sam Witteveen for their inspiring Gemini Masterclass at Google DevFest in Singapore. Their guidance helped me navigate the complexities of LLM development, and I learned firsthand the importance of careful prompt engineering, the power of system instructions, and the need for dynamic data access through function calls. These lessons underscore the complexities of developing robust LLM apps and will undoubtedly inform my future AI projects.
Building this project is an enjoyable journey of learning and discovery. I encountered many challenges along the way, but overcoming them deepened my understanding of Gemini. If you’re interested in exploring the code and learning from my experiences, you can access my Colab notebook through the button below. I welcome any feedback you might have!
We use Amazon S3 to store data for easy sharing among various applications. However, each application has its unique requirements and might require a different perspective on the data. To solve this problem, at times, we store additional customised datasets of the same data, ensuring that each application has its own unique dataset. This sometimes creates another set of problems because we now need to maintain additional datasets.
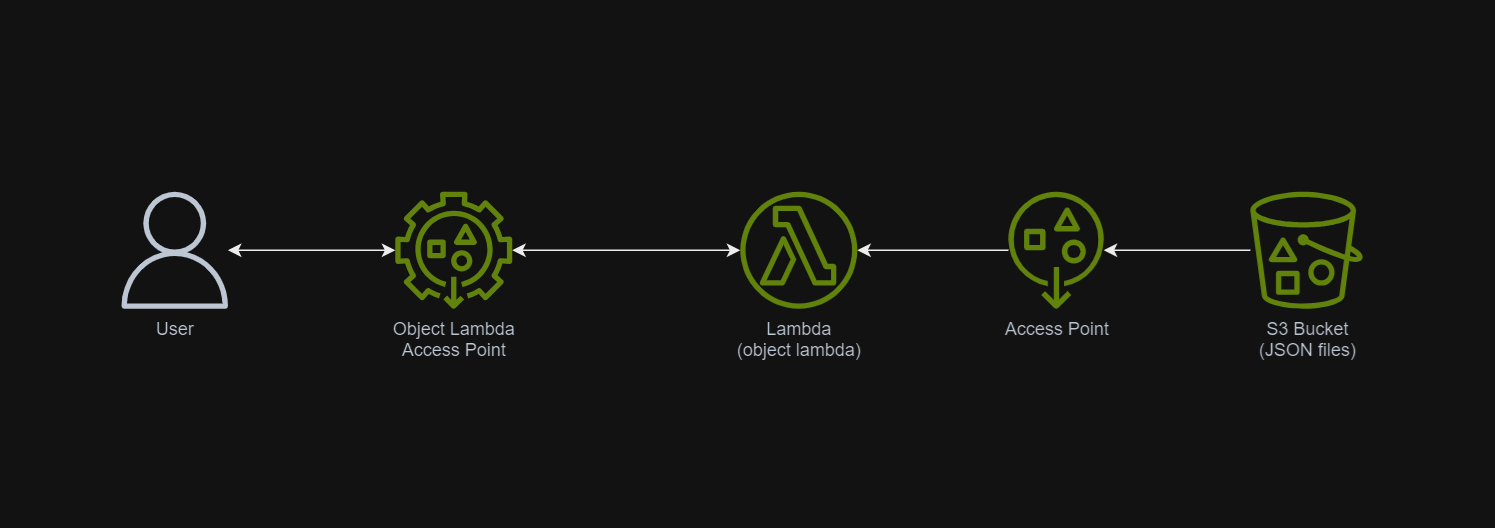
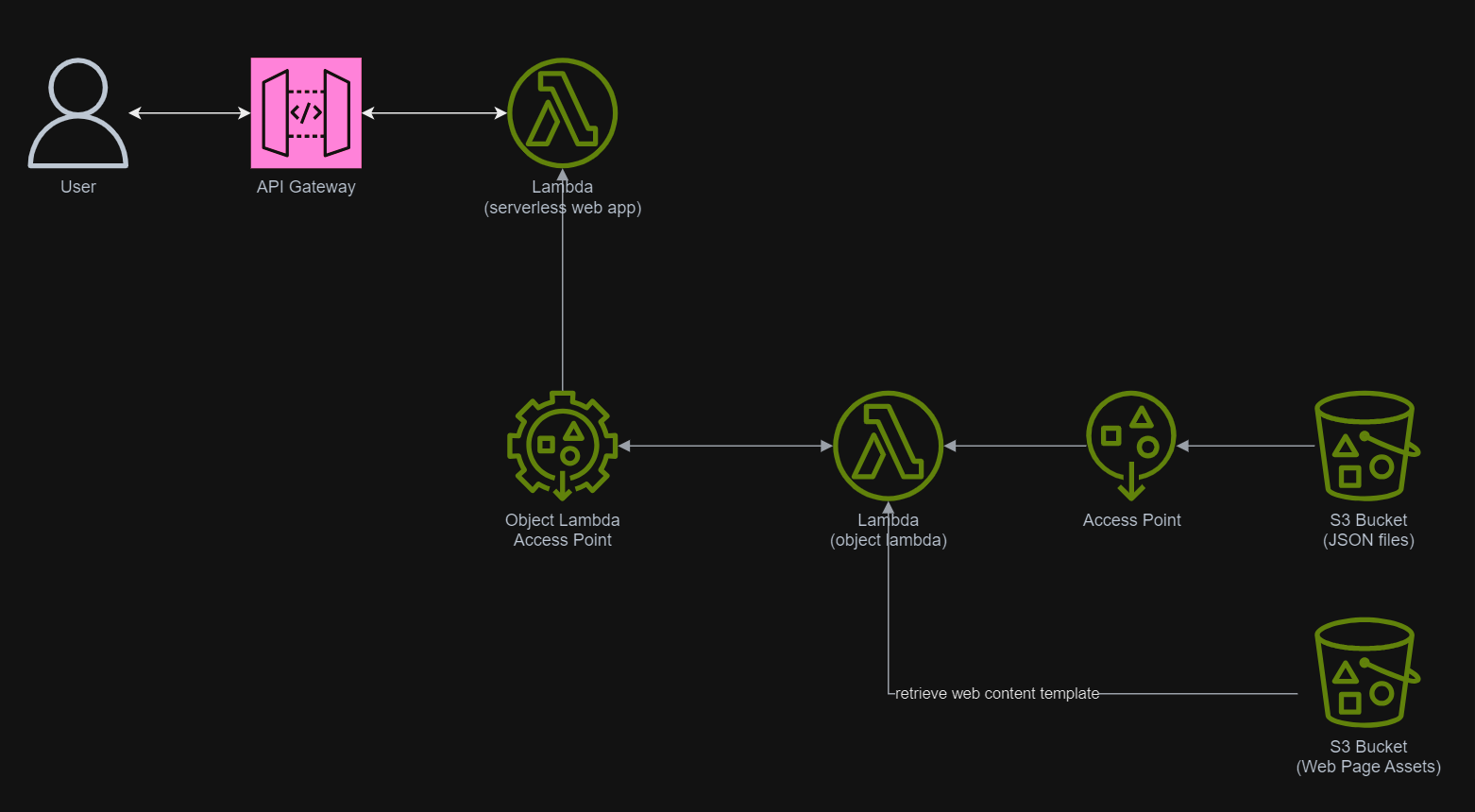
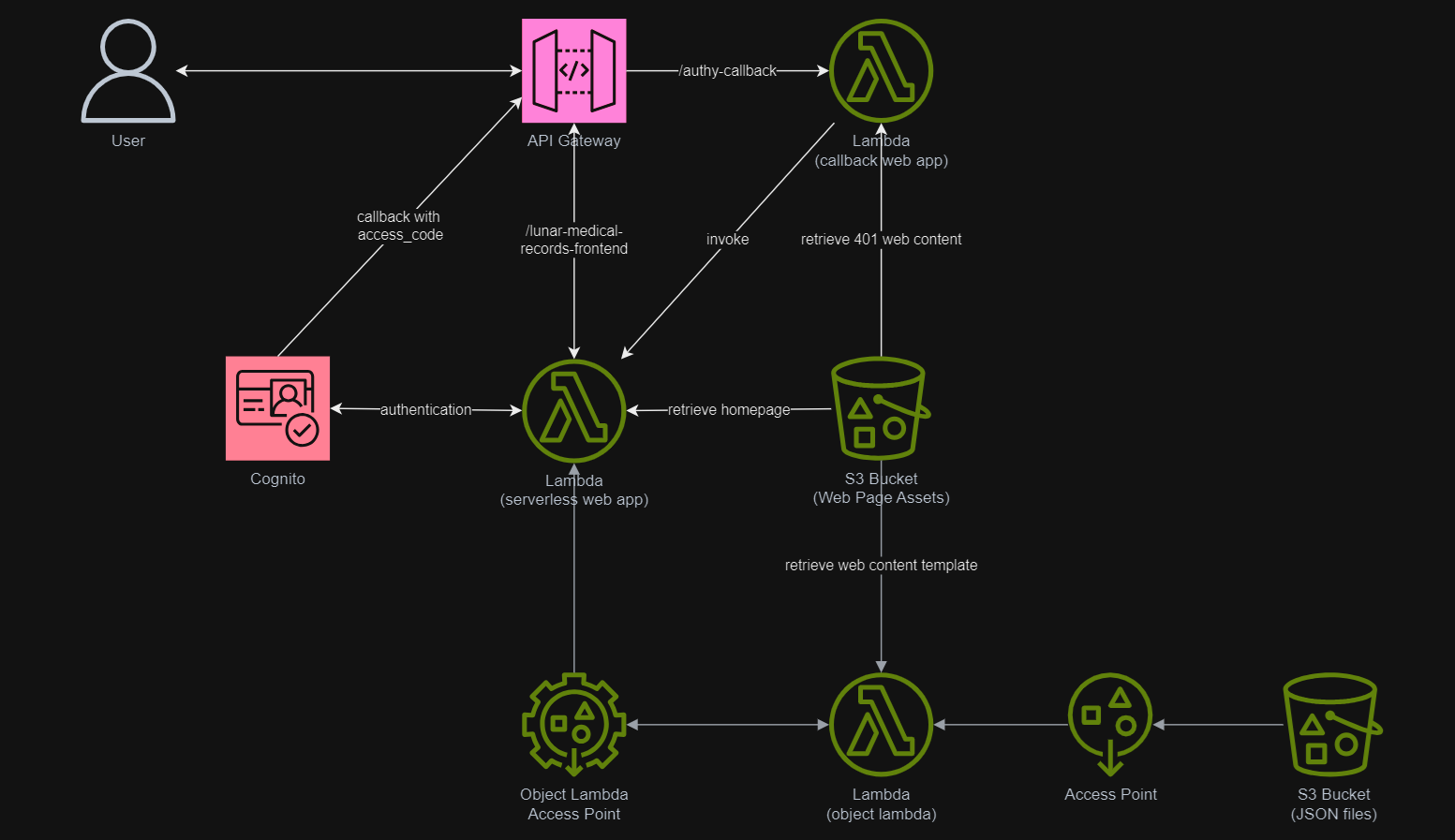
In March 2021, a new feature known as S3 Object Lambda was introduced. Similar to the idea of setting up a proxy layer in front of S3 to intercept and process data as it is requested, Object Lambda uses AWS Lambda functions to automatically process and transform your data as it is being retrieved from S3. With Object Lambda, we only need to change our apps to use the new S3 Object Lambda Access Point instead of the actual bucket name to retrieve data from S3.
Simplified architecture diagram showing how S3 Object Lambda works.
Example: Turning JSON to Web Page with S3 Object Lambda
I have been keeping details of my visits to medical centres as well as the treatments and medicines I received in a JSON file. So, I would like to take this opportunity to show how S3 Object Lambda can help in doing data processing.
We need a Lambda Function to do the data format transformation from JSON to HTML. To keep things simple, we will be developing the Function using Python 3.12.
Object Lambda does not need any API Gateway since it should be accessed via the S3 Object Lambda Access Point.
In the beginning, we can have the code as follows. The code basically does two things. Firstly, it performs some logging. Secondly, it reads the JSON file from S3 Bucket.
import json import os import logging import boto3 from urllib import request from urllib.error import HTTPError from types import SimpleNamespace
def lambda_handler(event, context): object_context = event["getObjectContext"] # Get the presigned URL to fetch the requested original object from S3 s3_url = object_context["inputS3Url"] # Extract the route and request token from the input context request_route = object_context["outputRoute"] request_token = object_context["outputToken"]
# Get the original S3 object using the presigned URL req = request.Request(s3_url) try: response = request.urlopen(req) responded_json = response.read().decode() except Exception as err: logger.error(f'Exception reading S3 content: {err}') return {'status_code': 500}
Step 1.1: Getting the JSON File with Presigned URL
In the event that an Object Lambda receives, there is a property known as the getObjectContext, which contains useful information for us to figure out the inputS3Url, which is the presigned URL of the object in S3.
By default, all S3 objects are private and thus for a Lambda Function to access the S3 objects, we need to configure the Function to have S3 read permissions to retrieve the objects. However, with the presigned URL, the Function can get the object without the S3 read permissions.
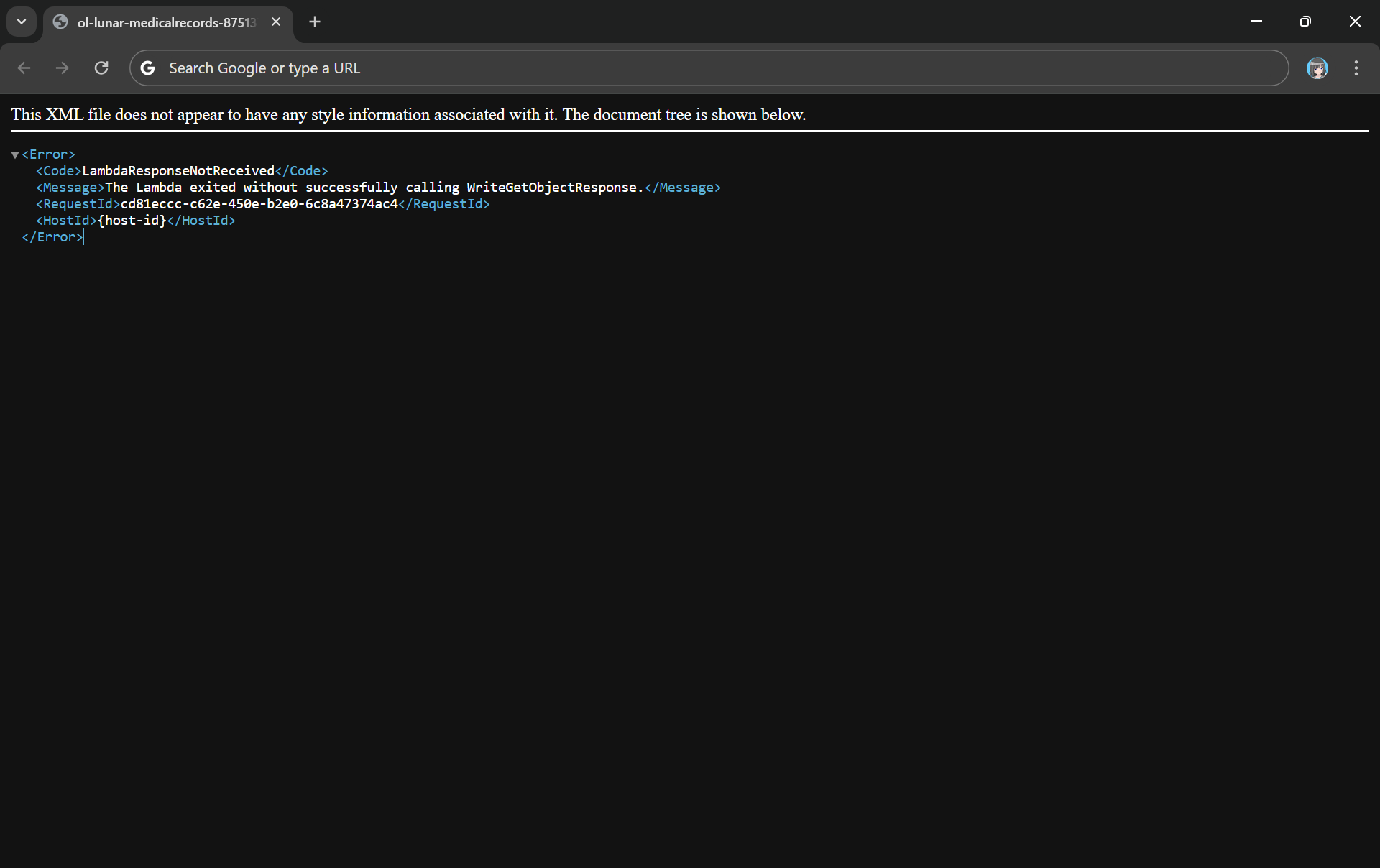
Since the purpose of Object Lambda is to process and transform our data as it is being retrieved from S3, we need to pass transformed object to a GetObject operation in the Function via the method write_get_object_response. Without this method, there will be an error from the Lambda complaining that it is missing.
Error: The Lambda exited without successfully calling WriteGetObjectResponse.
html = template_content.replace('{{DYNAMIC_TABLE}}', dynamic_table)
Step 2: Give Lambda Function Necessary Permissions
With the setup we have gone through above, we understand that our Lambda Function needs to have the following permissions.
s3-object-lambda:WriteGetObjectResponse
s3:GetObject
Step 3: Create S3 Access Point
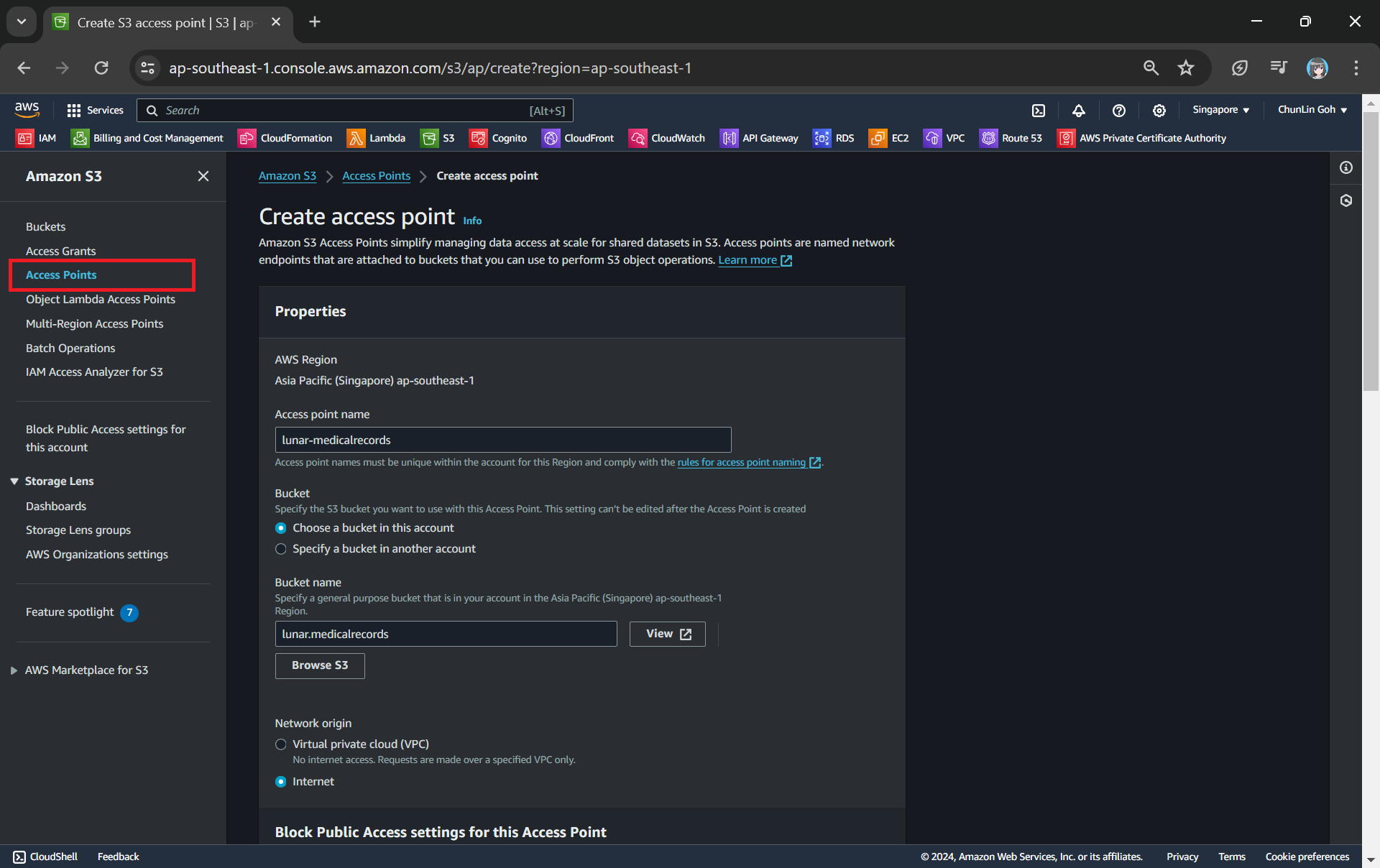
Next, we will need to create a S3 Access Point. It will be used to support the creation of the S3 Object Lambda Access Point later.
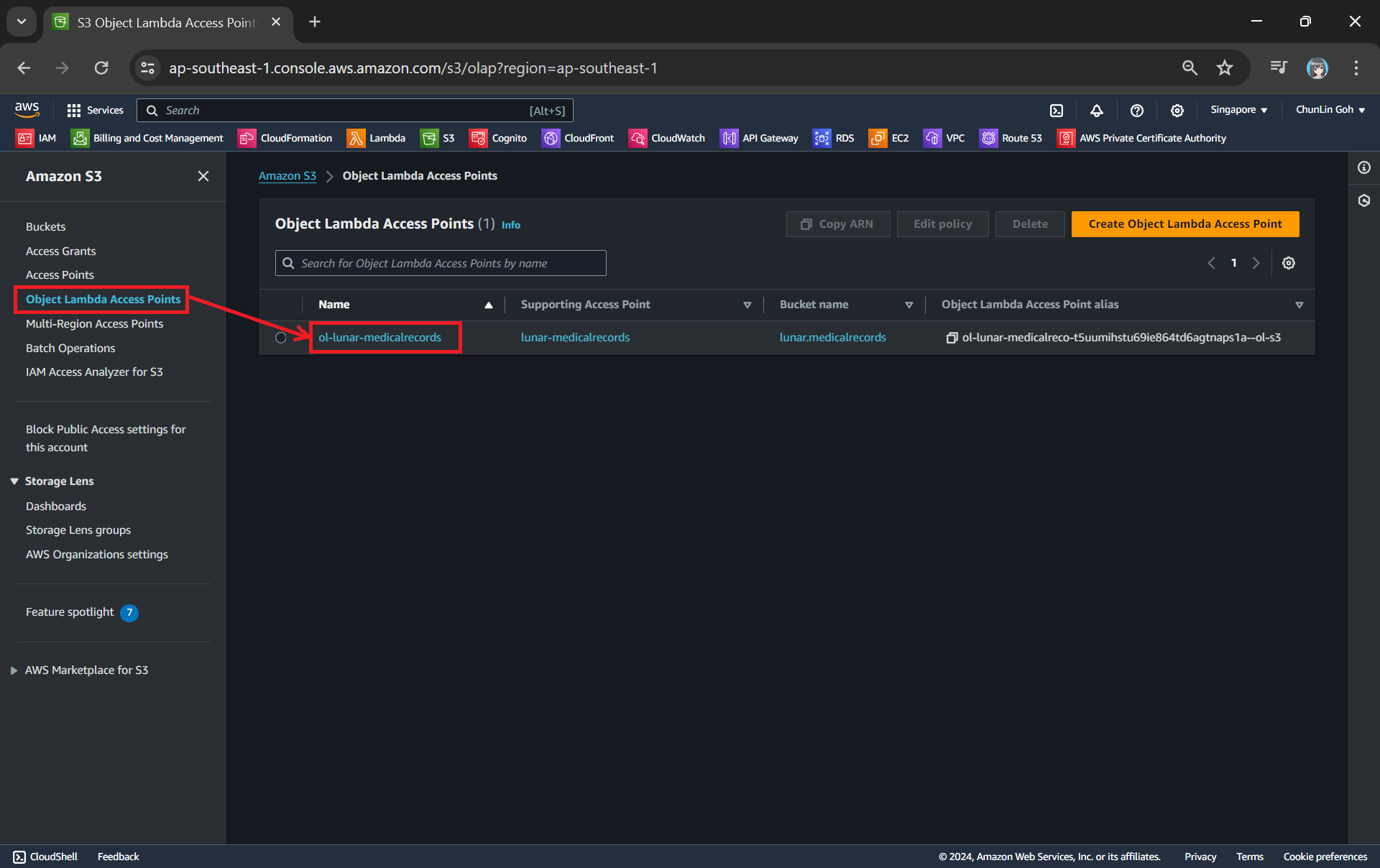
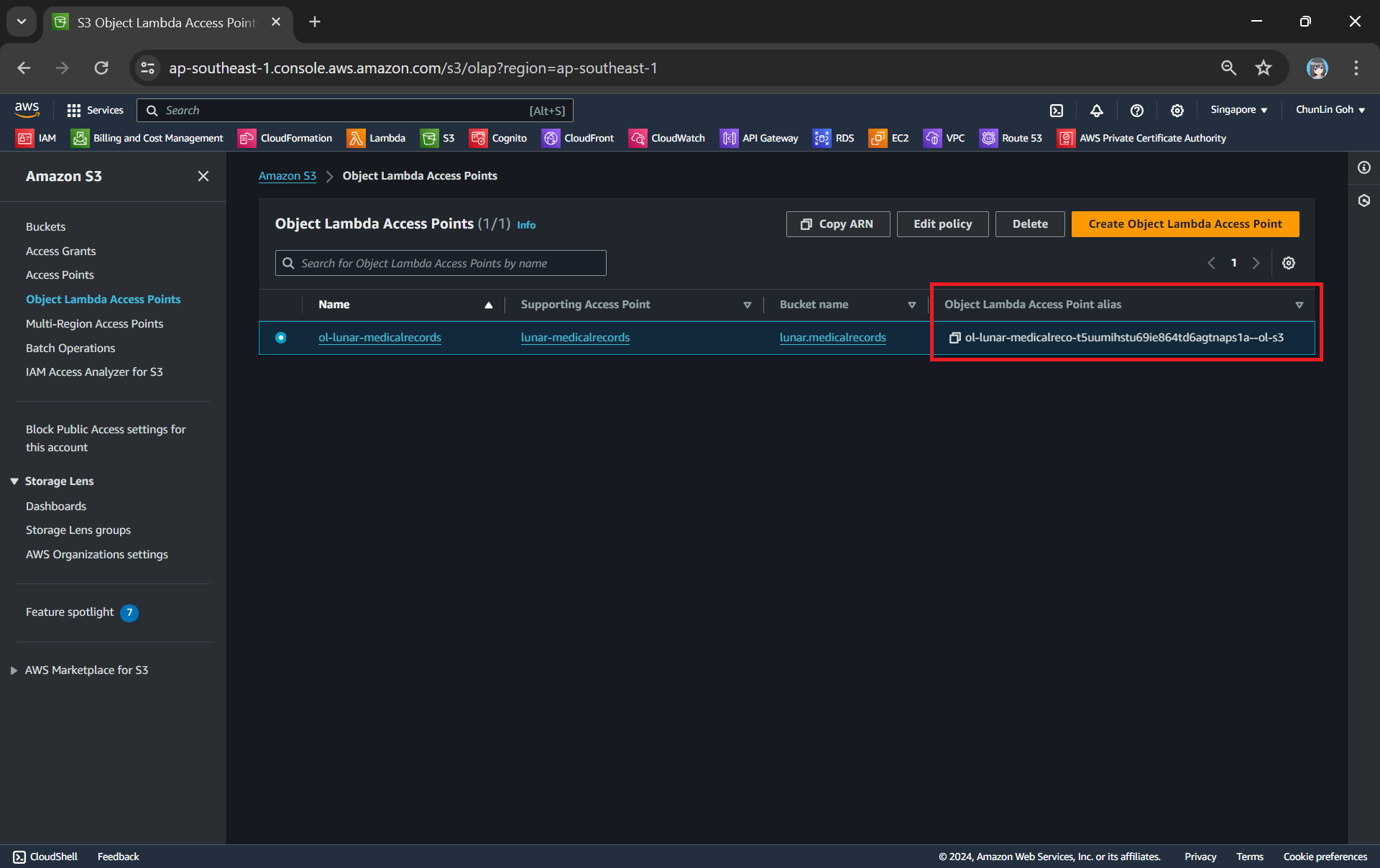
One of the features that S3 Access Point offers is that we can specify any name that is unique within the account and region. For example, as shown in the screenshot below, we can actually have a “lunar-medicalrecords” access point in every account and region.
Creating an access point from the navigation pane of S3.
When we are creating the access point, we need to specify the bucket which resides in the same region that we want to use with this Access Point. In addition, since we are not restricting the access of it to only a specific VPC in our case, we will be choosing “Internet” for the “Network origin” field.
After that, we keep all other defaults as is. We can directly proceed to choose the “Create access point” button.
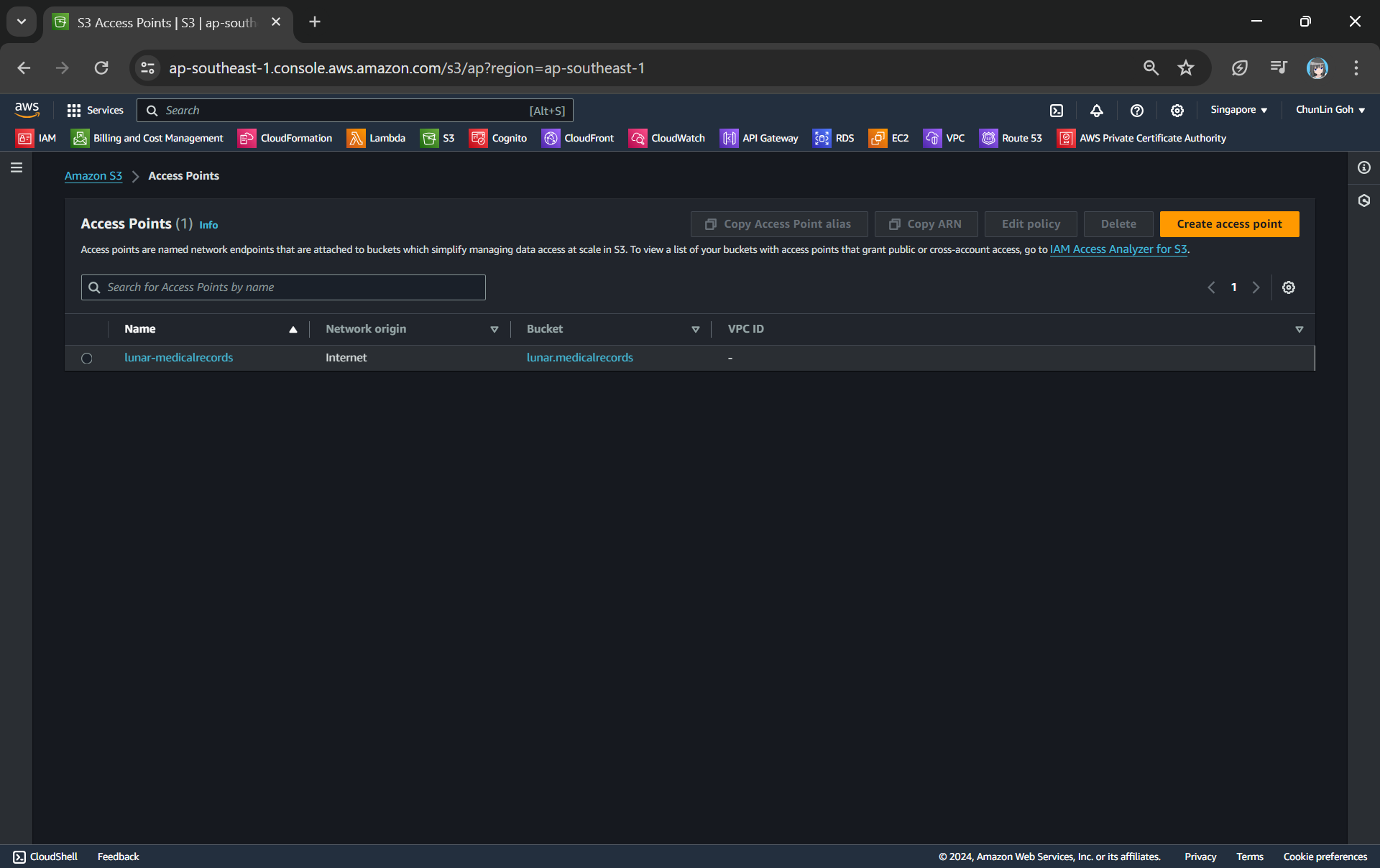
Our S3 Access Point is successfully created.
Step 4: Create S3 Object Lambda Access Point
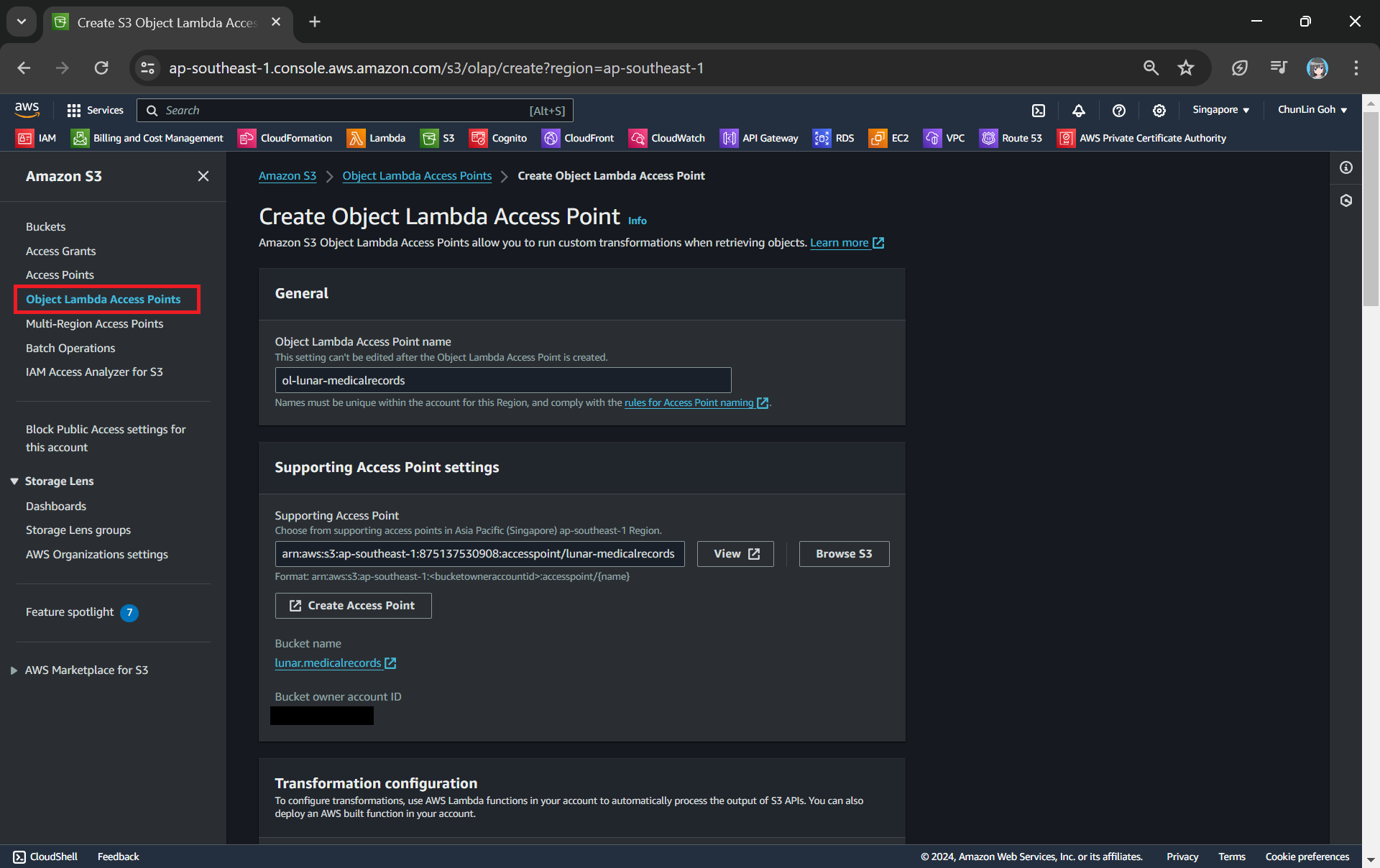
After getting our S3 Access Point set up, we can then move on to create our S3 Object Lambda Access Point. This is the actual access point that our app will be using to access the JSON file in our S3 bucket. It then should return a HTML document generated by the Object Lambda that we built in Step 1.
Creating an object lambda access point from the navigation pane of S3.
In the Object Lambda Access Point creation page, after we give it a name, we need to provide the Supporting Access Point. This access point is the Amazon Resource Name (ARN) of the S3 Access Point that we created in Step 3. Please take note that both the Object Lambda Access Point and Supporting Access Point must be in the same region.
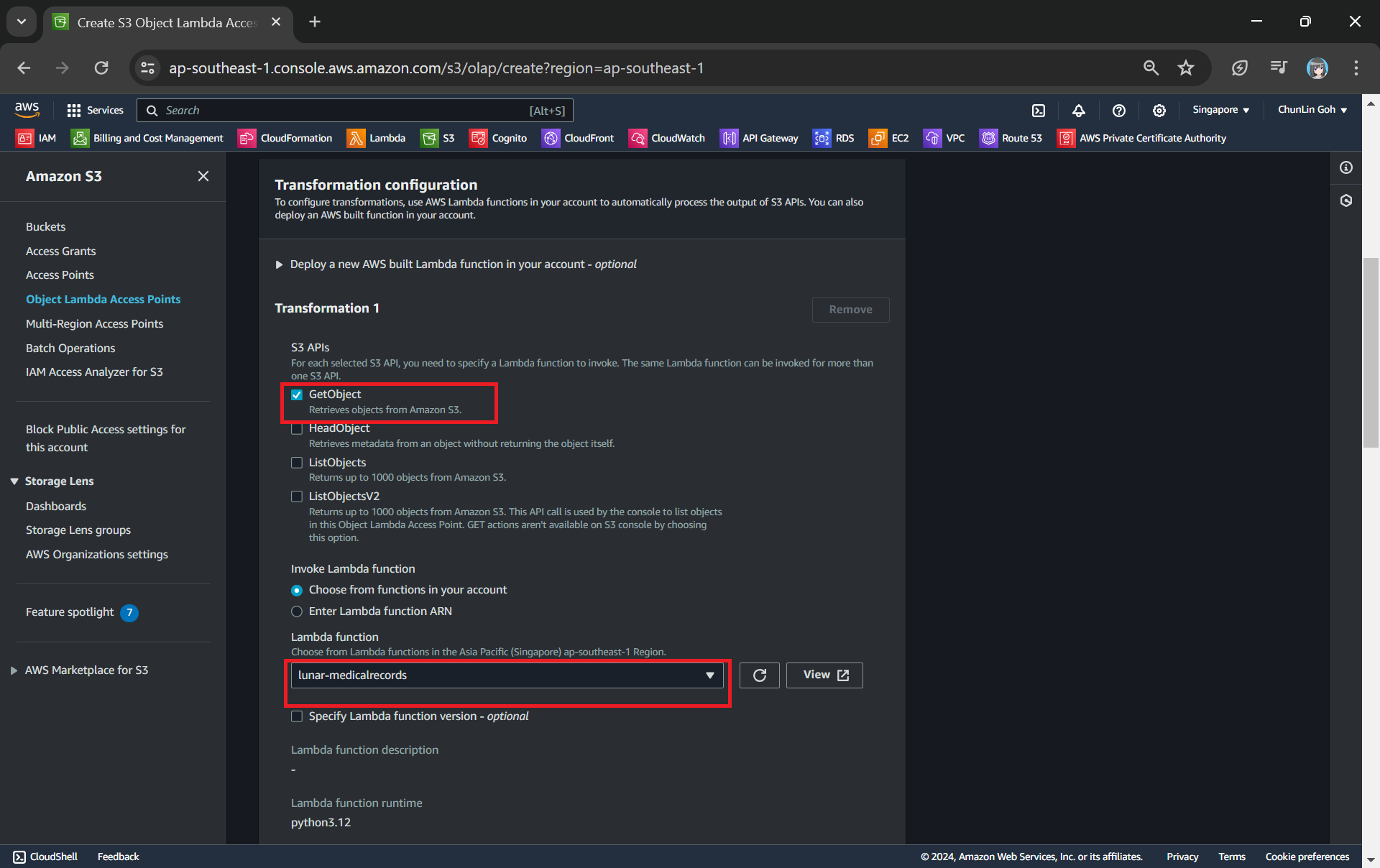
Next we need to setup the transformation configuration. In our case, we will be retrieving the JSON file from the S3 bucket to perform the data transformation via our Lambda Function, so we will be choosing GetObject as the S3 API we will be using, as shown in the screenshot below.
Configuring the S3 API that will be used in the data transformation and the Lambda Function to invoke.
Once all these fields are keyed in, we can proceed to create the Object Lambda Access Point.
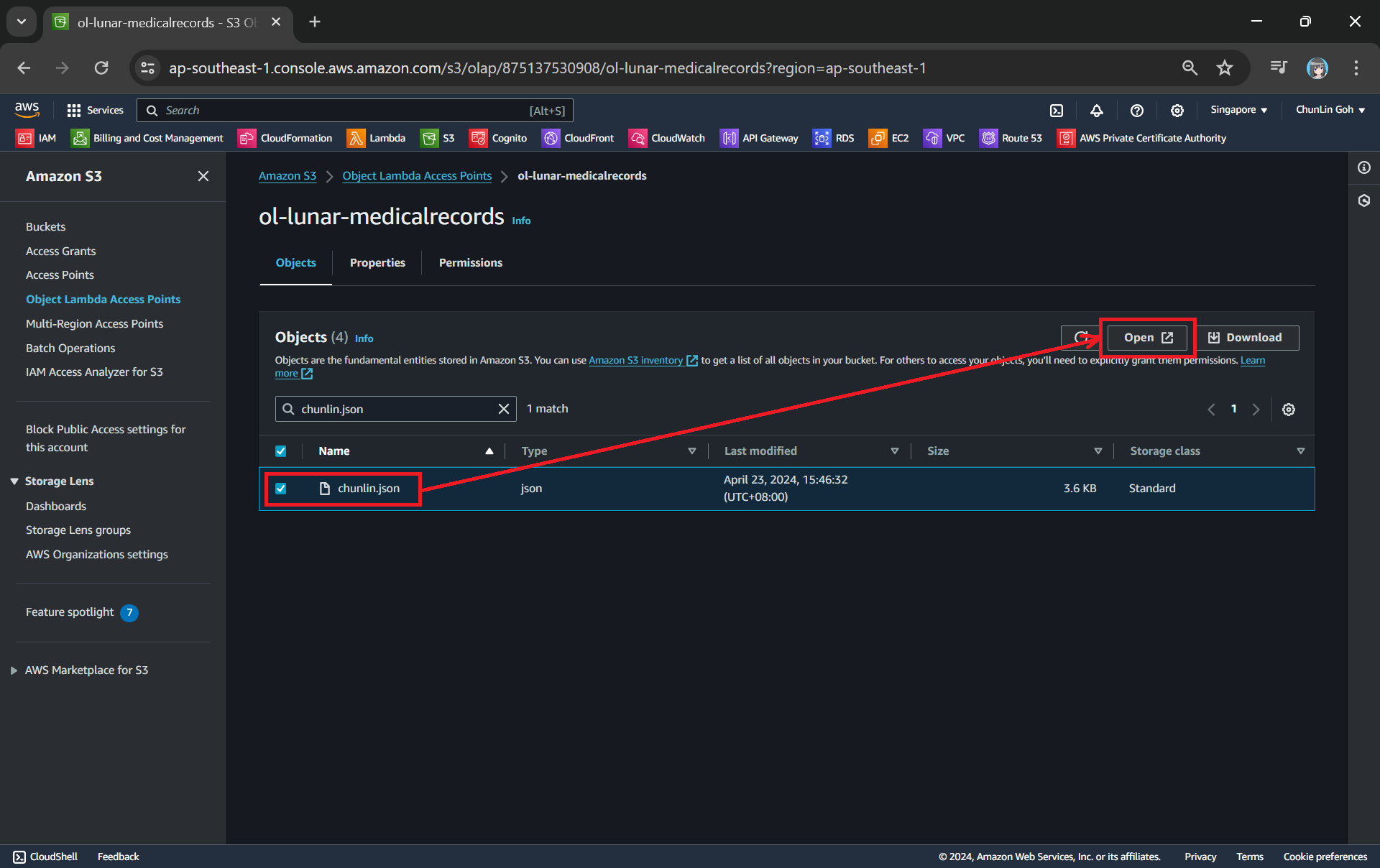
Now, we will access the JSON file via the Object Lambda Access Point to verify that the file is really transformed into a web page during the request. To do so, firstly, we need to select the newly create Object Lambda Access Point as shown in the following screenshot.
Locate the Object Lambda Access Point we just created in the S3 console.
Secondly, we will be searching for our JSON file, for example chunlin.json in my case. Then, we will click on the “Open” button to view it. The reason why I name the JSON file containing my medical records is because later I will be adding authentication and authorisation to only allow users retrieving their own JSON file based on their login user name.
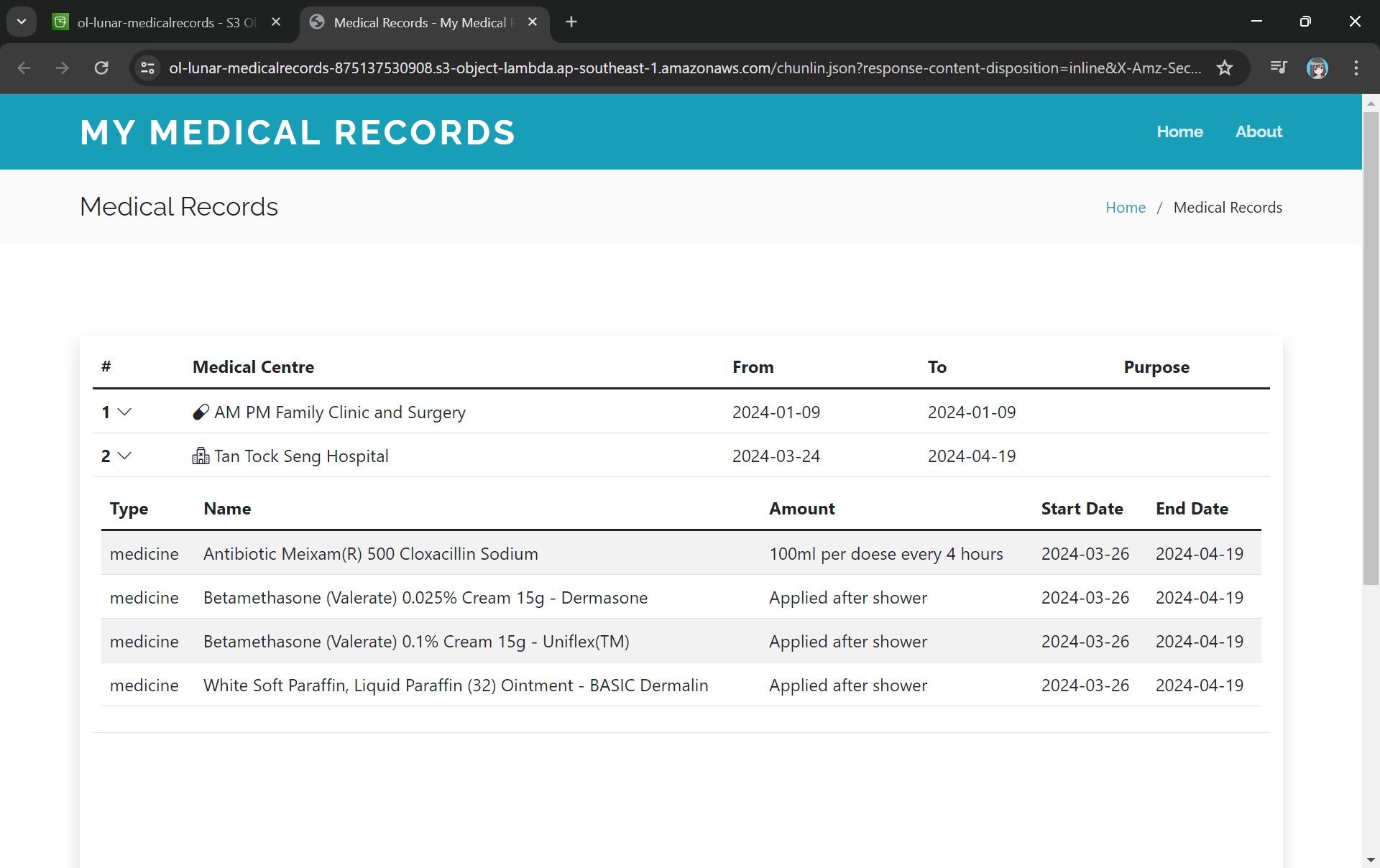
This page looks very similar to the usual S3 objects listing page. So please make sure you are doing this under the “Object Lambda Access Point”.
There will be new tab opened showing the web page as demonstrated in the screenshot below. As you have noticed in the URL, it is still pointing to the JSON file but the returned content is a HTML web page.
The domain name is actually no longer the usual S3 domain name but it is our Object Lambda Access Point.
Using the Object Lambda Access Point from Our App
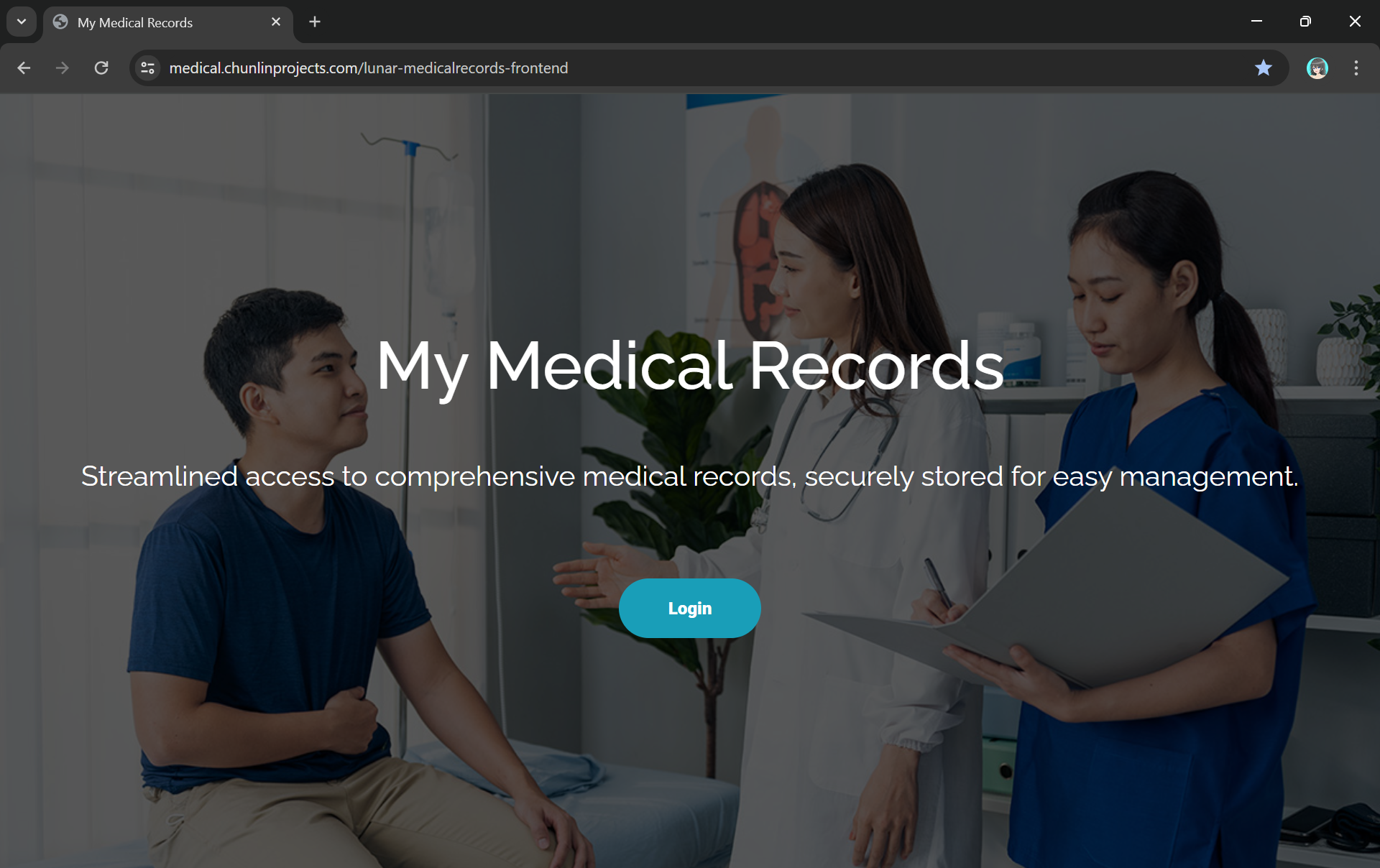
With the Object Lambda Access Point successfully setup, we will show how we can use it. To not overcomplicate things, for the purposes of this article, I will host a serverless web app on Lambda which will be serving the medical record website above.
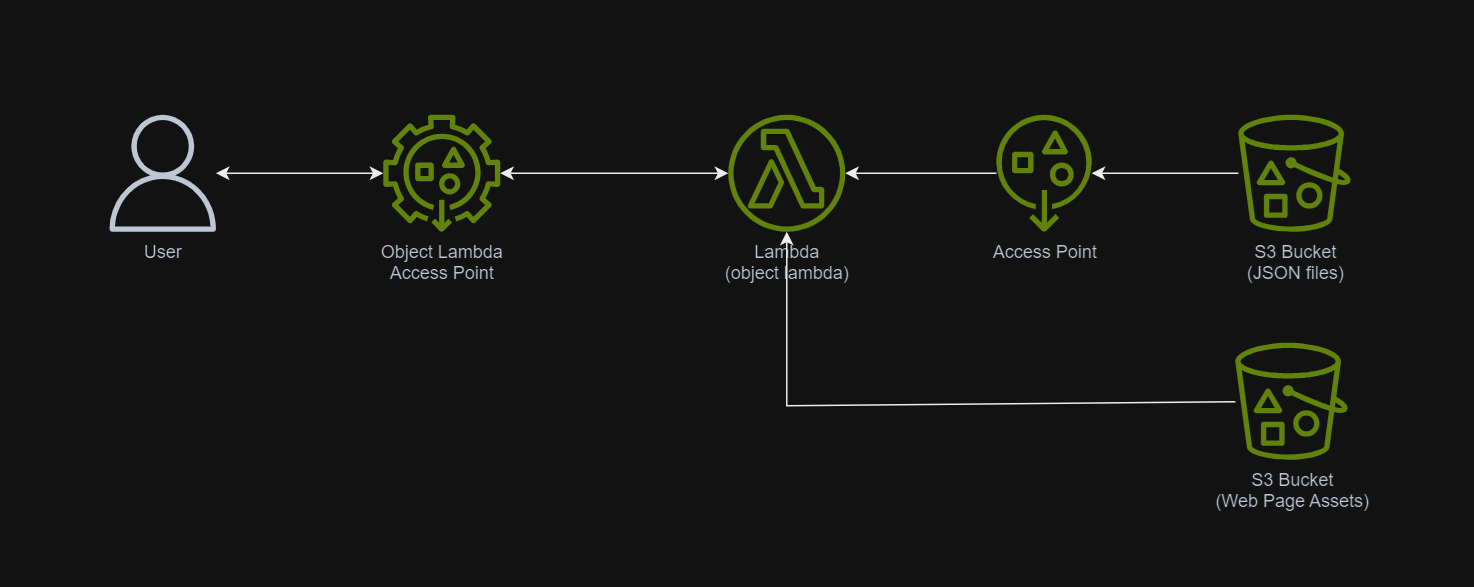
In addition, since Lambda Functions are by default not accessible from the Internet, we will be using API Gateway so that we can have a custom REST endpoint in the AWS and thus we can map this endpoint to the invokation of our Lambda Function. Technically speaking, the architecture diagram now looks as follows.
This architecture allows public to view the medical record website which is hosted as a serverless web app.
In the newly created Lambda, we will still be developing it with Python 3.12. We name this Lambda lunar-medicalrecords-frontend. We will be using the following code which will retrieve the HTML content from the Object Lambda Access Point.
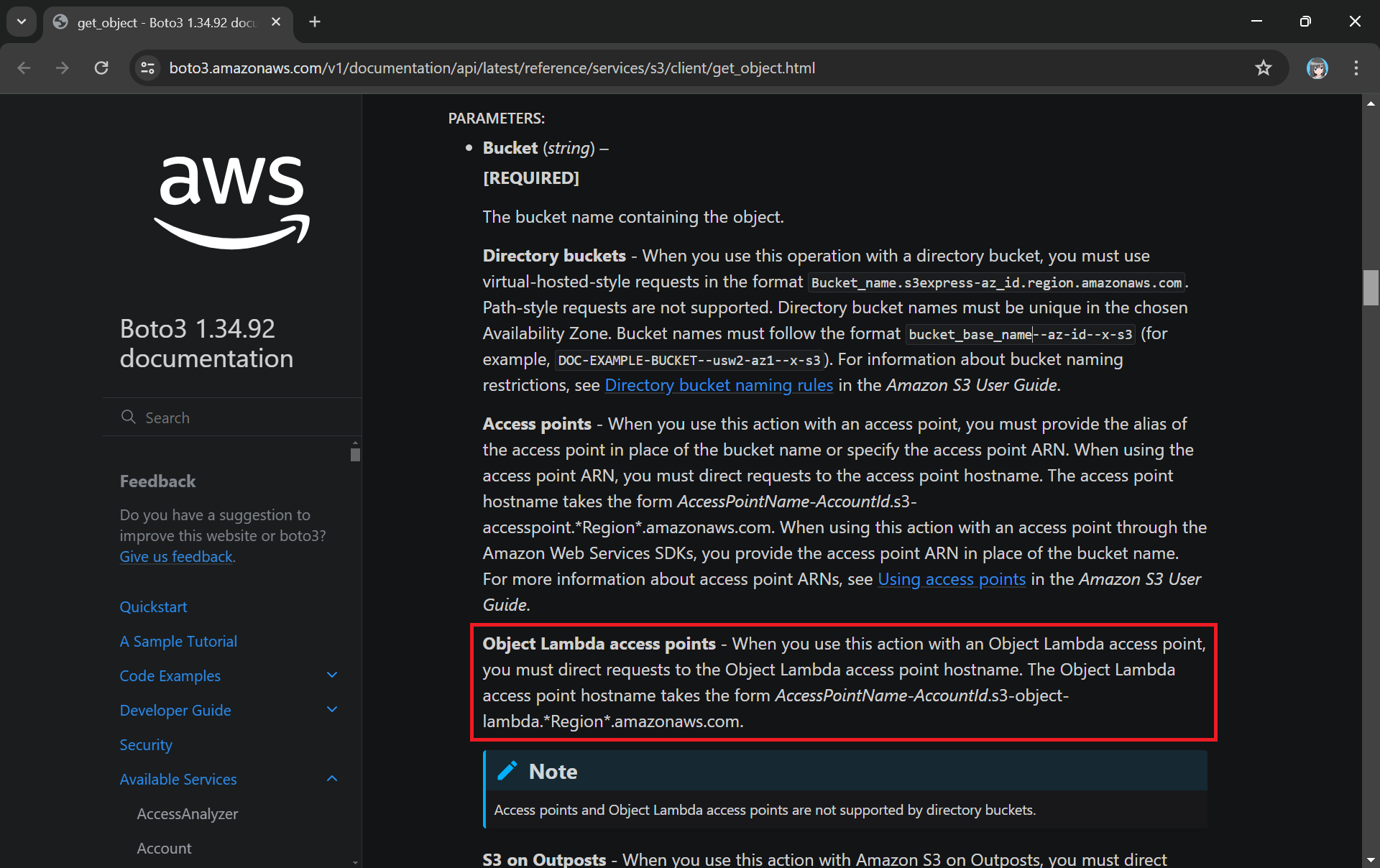
The Boto3 documentation highlights the use of Object Lambda Access Point in get_object.
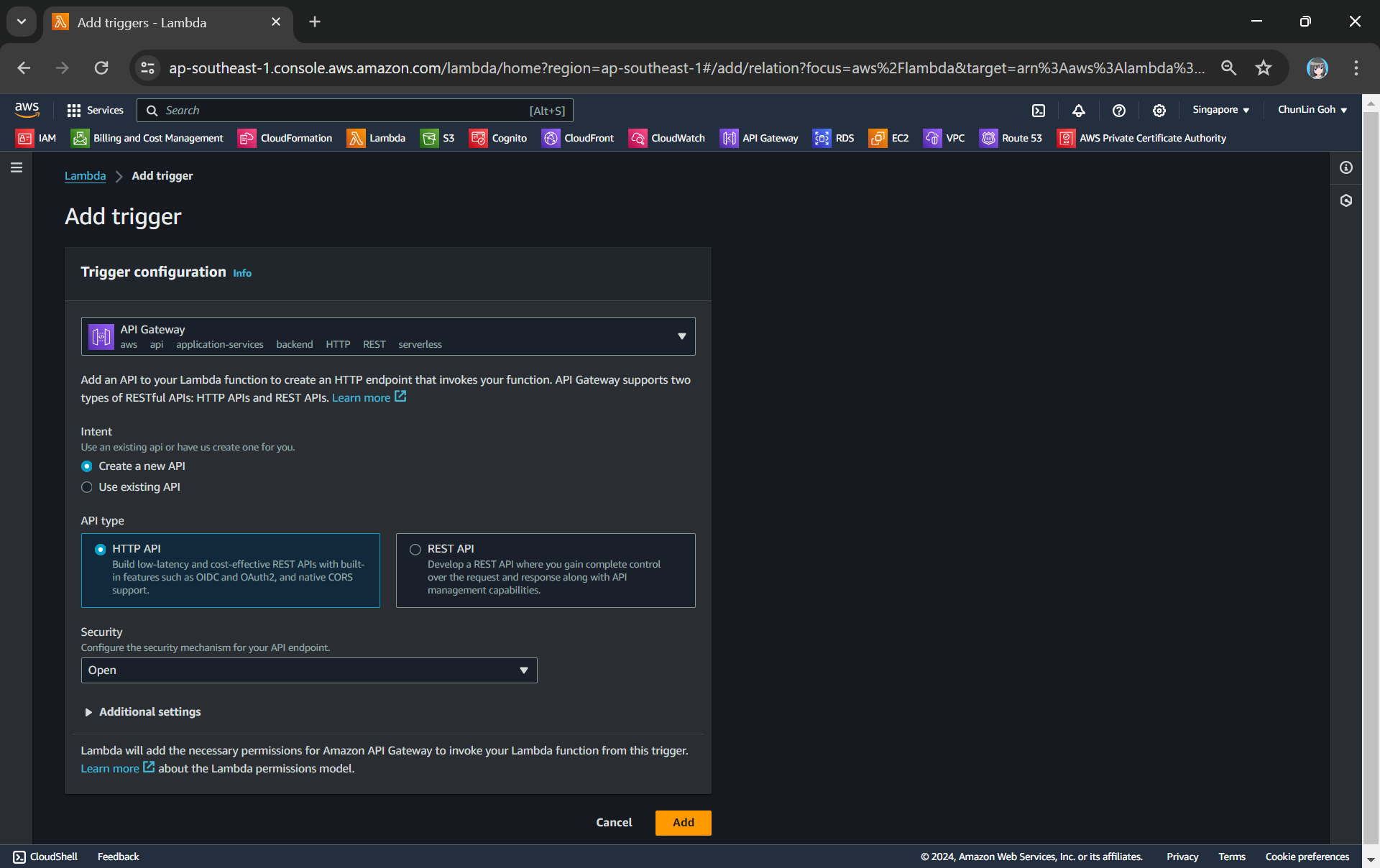
The API Gateway for the Lambda Function is created with HTTP API through the “Add Trigger” function (which is located at the Function overview page). For the Security field, we will be choosing “Open” for now. We will add the login functionality later.
Adding API Gateway as a trigger to our Lambda.
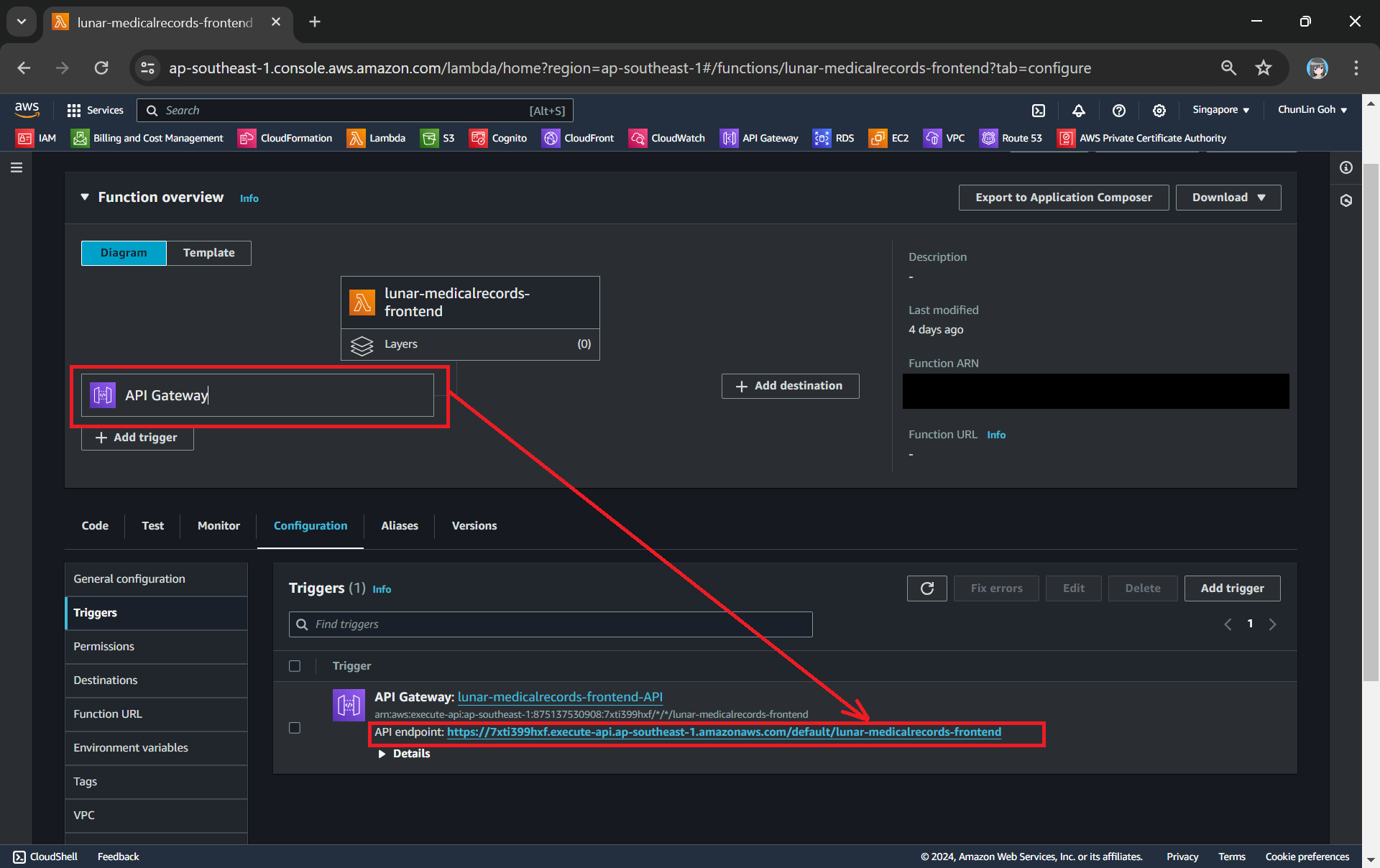
Once this is done, we will be provided an API Gateway endpoint, as shown in the screenshot below. Visiting the endpoint should be rendering the same web page listing the medical records as we have seen above.
Getting the API endpoint of the API Gateway.
Finally, for the Lambda Function permission, we only need to grand it the following.
s3:GetObject.
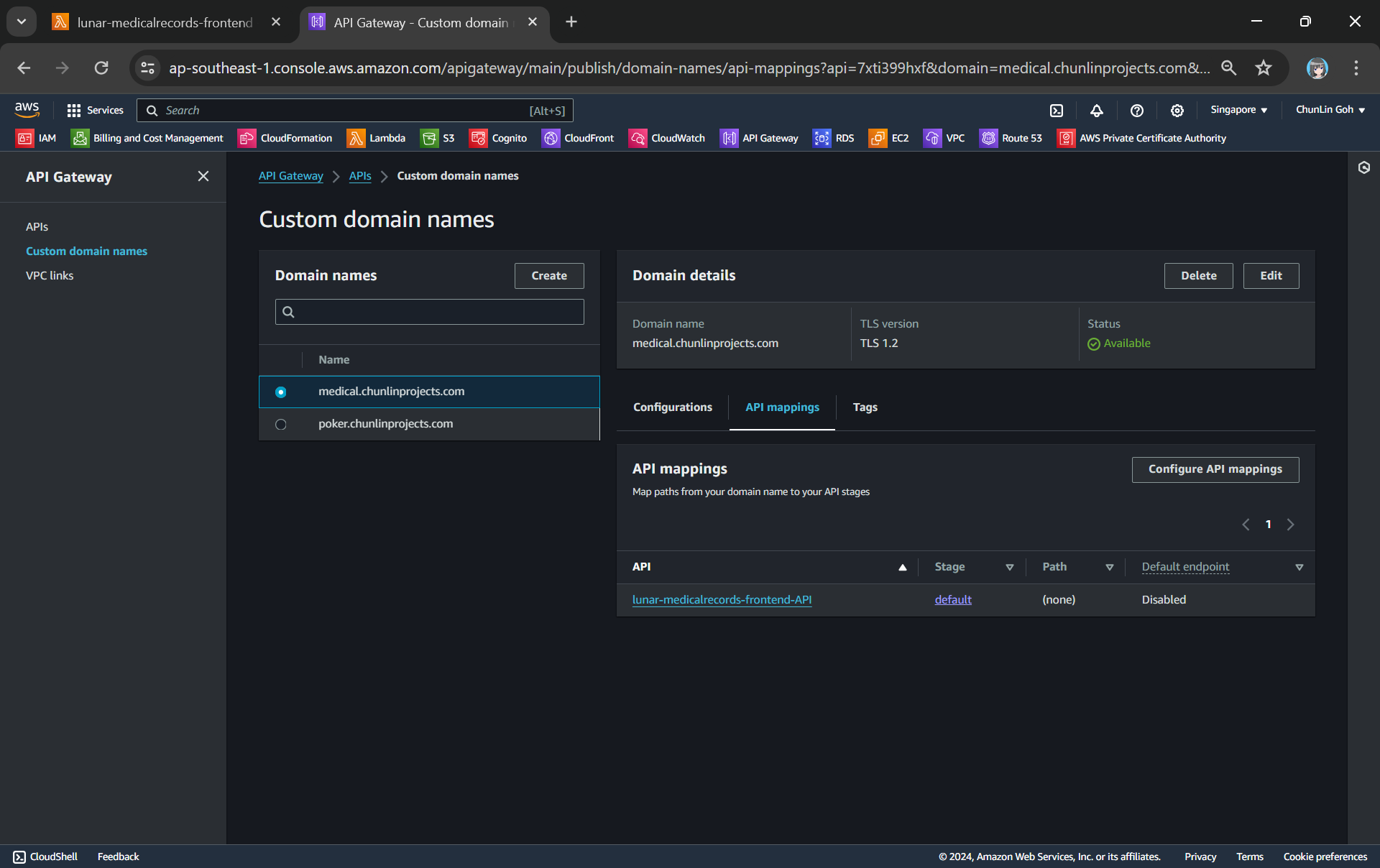
To make the API Gateway endpoint looks more user friendly, we can also introduce Custom Domain to the API Gateway, following the guide in one of our earlier posts.
Assigned medical.chunlinprojects.com to our API Gateway.
Protecting Data with Cognito
In order to ensure that only authenticated and authorised users can access their own medical records, we need to securely control access to our the app with the help from Amazon Cognito. Cognito is a service that enables us to add user sign-in and access control to our apps quickly and easily. Hence it helps authenticate and authorise users before they can access the medical records.
Step 1: Setup Amazon Cognito
To setup Cognito, firstly, we need to configure the User Pool by specifying sign-in options. User pool is a managed user directory service that provides authentication and user management capabilities for our apps. It enables us to offload the complexity of user authentication and management to AWS.
Configuring sign-in options and user name requirements.
Please take note that Cognito user pool sign-in options cannot be changed after the user pool has been created. Hence, kindly think carefully during the configuration.
Configuring password policy.
Secondly, we need to configure password policy and choose whether to enable Multi-Factor Authentication (MFA).
By default, Cognito comes with a password policy that ensures our users maintain a password with a minimum length and complexity. For password reset, it will also generate a temporary password to the user which will expire in 7 days, by default.
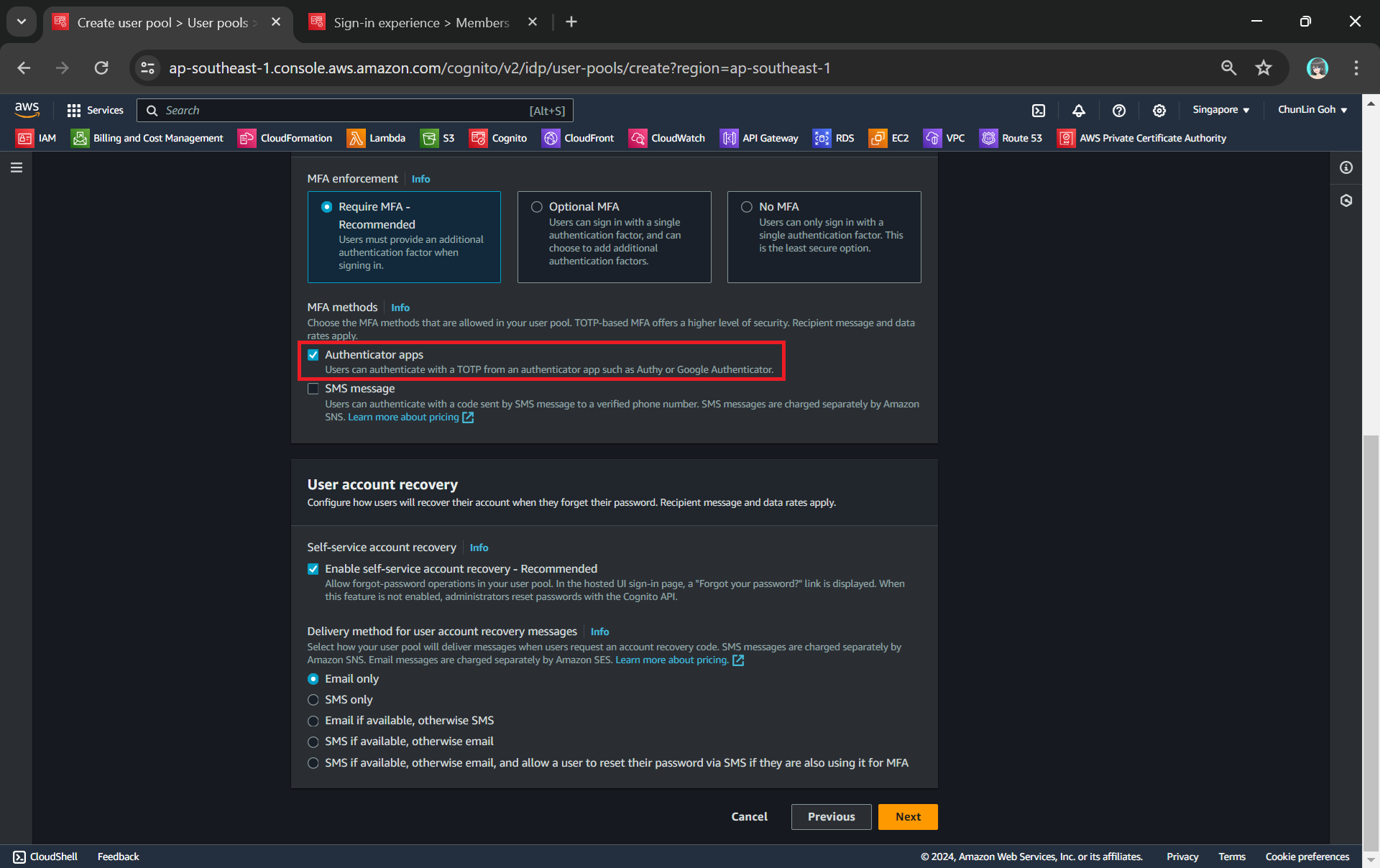
MFA adds an extra layer of security to the authentication process by requiring users to provide additional verification factors to gain access to their accounts. This reduces the risk of unauthorised access due to compromised passwords.
Enabling MFA in our Cognito user pool.
As shown in the screenshot above, one of the methods is called TOTP. TOTP stands for Time-Based One-Time Password. It is a form of multi-factor authentication (MFA) where a temporary passcode is generated by the authenticator app, adding a layer of security beyond the typical username and password.
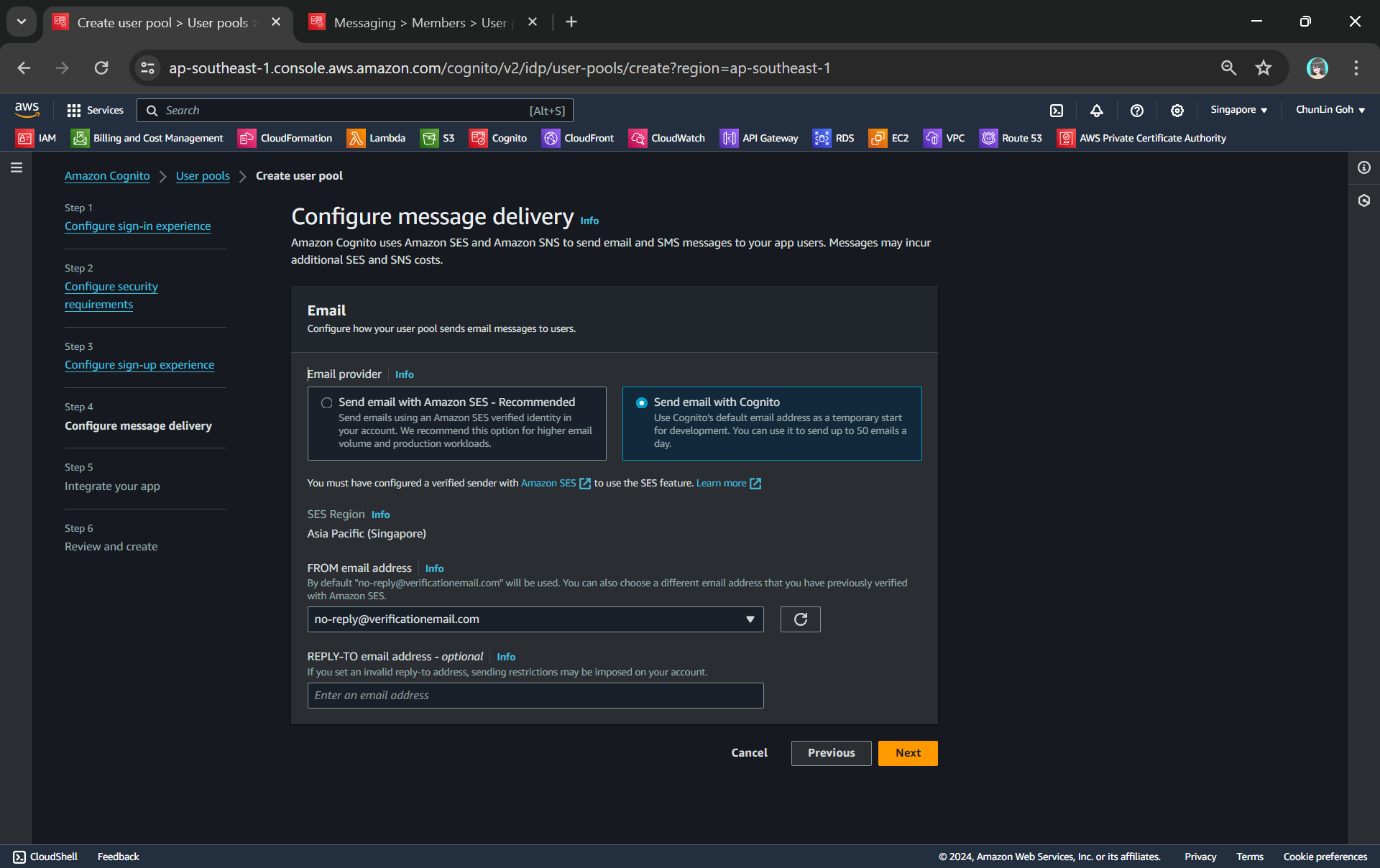
Thirdly, we will be configuring Cognito to allow user account recovery as well as new user registration. Both of these by default require email delivery. For example, when users request an account recovery code, an email with the code should be sent to the user. Also, when there is a new user signing up, there should be emails sent to verify and confirm the new account of the user. So, how do we handle the email delivery?
We can choose to send email with Cognito in our development environment.
Ideally, we should be setting up another service known as Amazon SES (Simple Email Service), an email sending service provided by AWS, to deliver the emails. However, for testing purpose, we can choose to use Cognito default email address as well. This approach is normally only suitable for development purpose because we can only use it to send up to 50 emails a day.
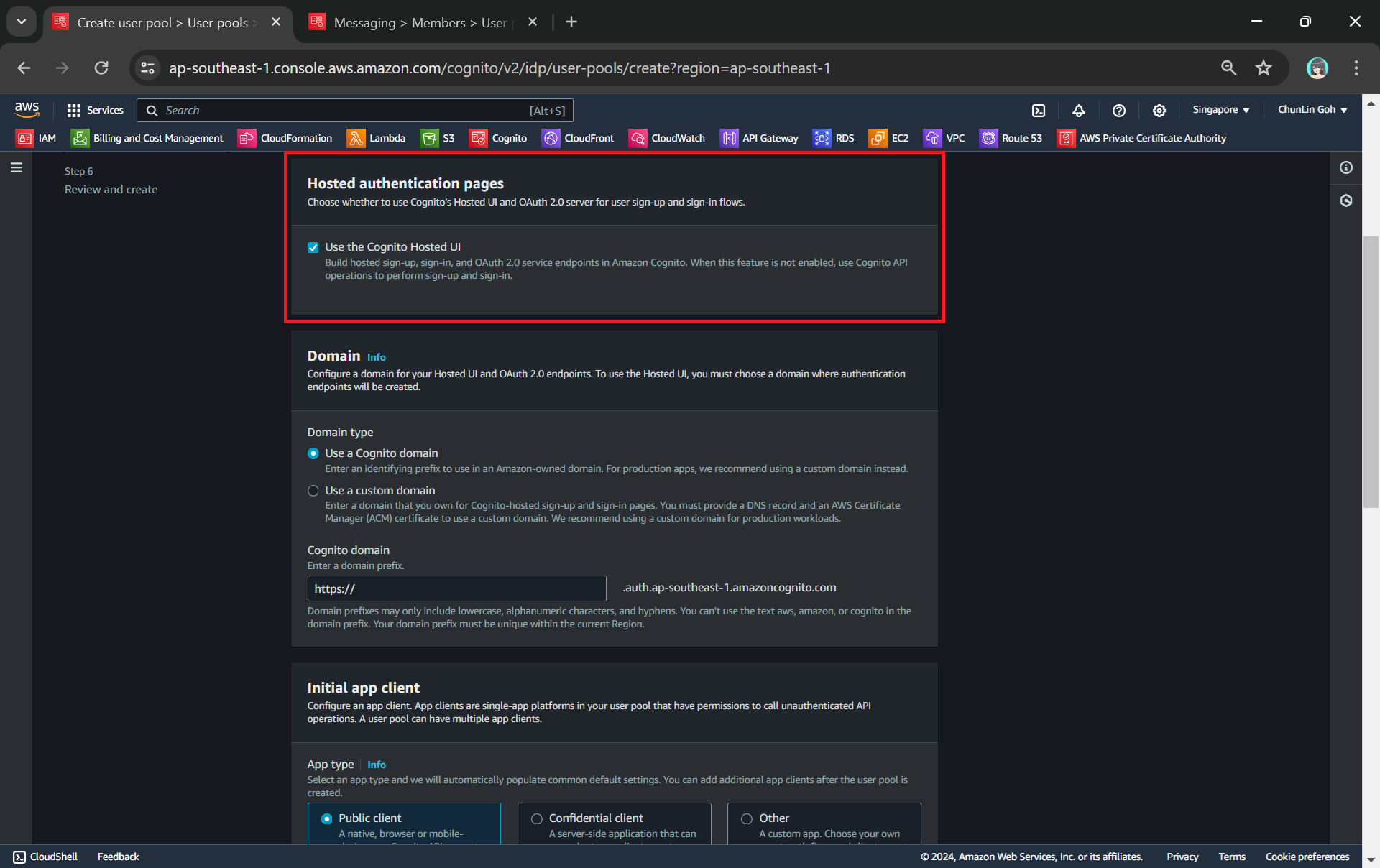
Finally, we will be using the hosted authentication pages for user sign-in and sign-up, as demonstrated below.
Using hosted UI so that we can have a simple frontend ready for sign-in and sign-up.
Step 2: Register Our Web App in Cognito
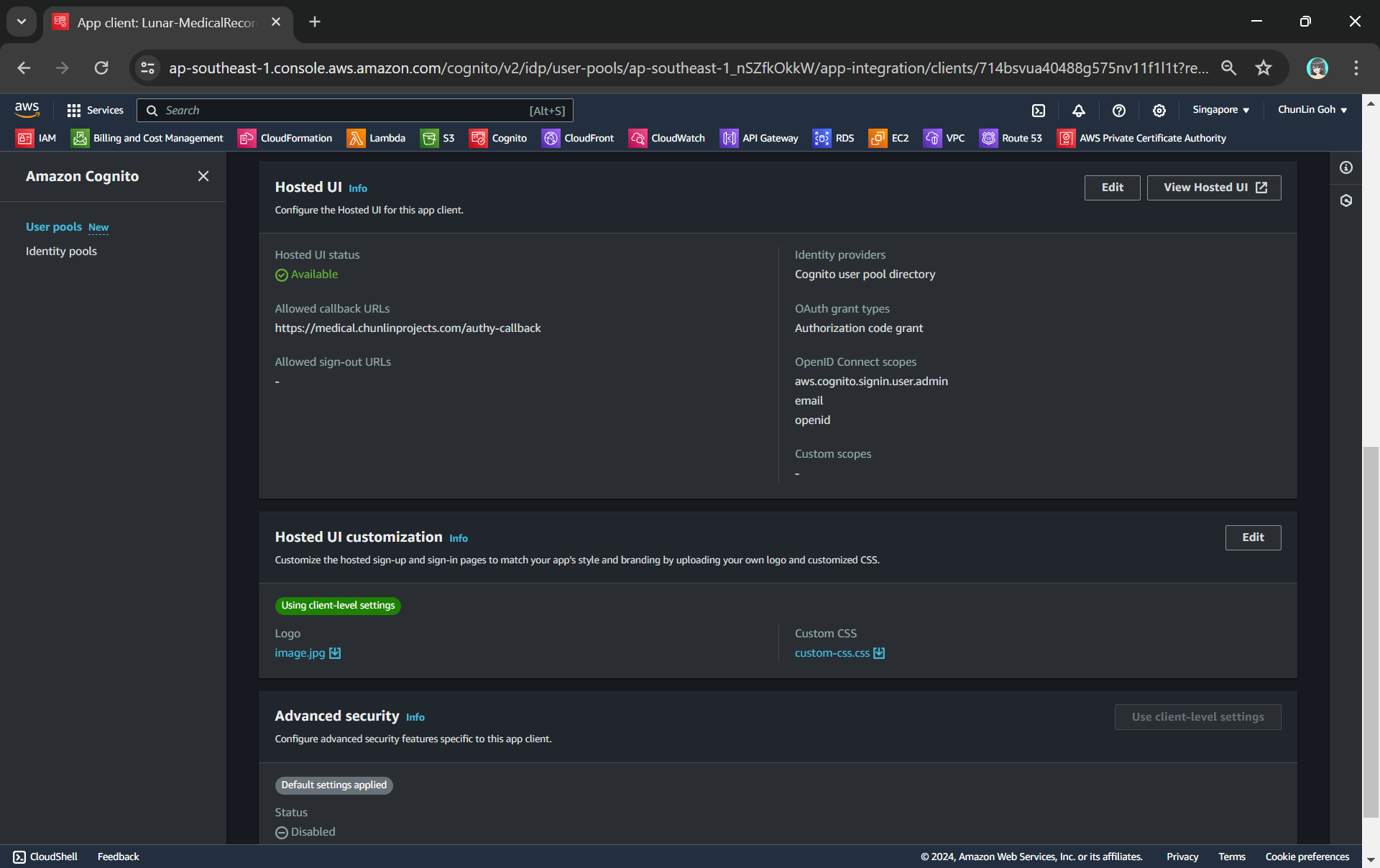
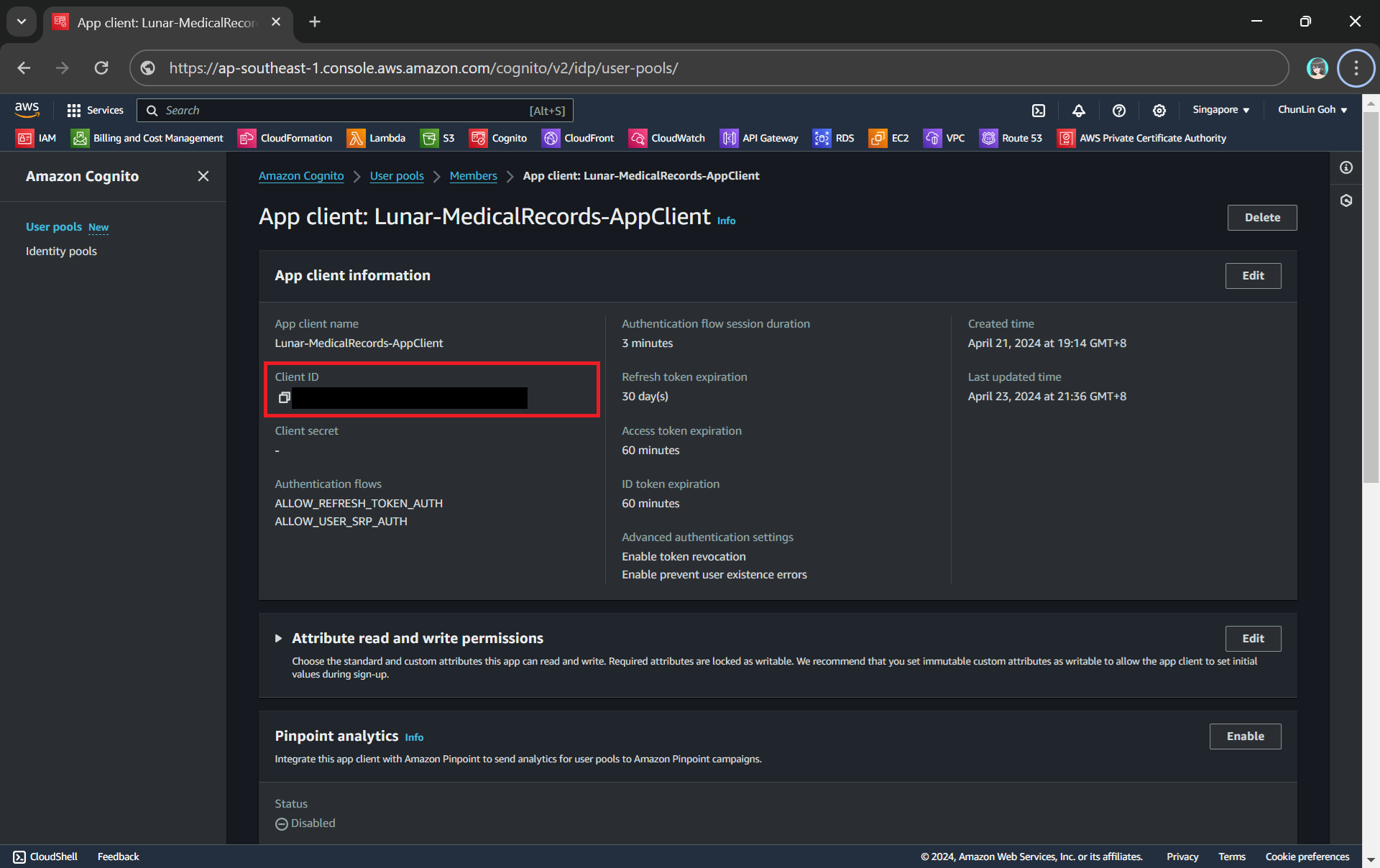
To integrate our app with Cognito, we still need to setup the app client. An App Client is a configuration entity that allows our app to interact with the user pool. It is essentially an application-specific configuration that defines how users will authenticate and interact with our user pool. For example, we have setup a new app client for our medical records app as shown in the following screenshot.
We customise the hosetd UI with our logo and CSS.
As shown in the screenshot above, we are able to to specify customisation settings for the built-in hosted UI experience. Please take note that we are only able to customise the look-and-feel of the default “login box”, so we cannot modify the layout of the entire hosted UI web page, as demonstrated below.
The part with gray background cannot be customised with the CSS.
In the setup of the app client above, we have configured the callback URL to /authy-callback. So where does this lead to? It actually points to a new Lambda function which is in charge of the authentication.
Step 3: Retrieve Access Token from Cognito Token Endpoint
Here, Cognito uses the OAuth 2.0 authorization code grant flow. Hence, after successful authentication, Cognito redirects the user back to the specified callback URL with an authorisation code included in the query string with the name code. Our authentication Lambda function thus needs to makes a back-end request to the Cognito token endpoint, including the authorisation code, client ID, and redirect URI to exchange the authorisation code for an access token, refresh token, and ID token.
Client ID can be found under the “App client information” section.
token_url = "https://lunar-corewebsite.auth.ap-southeast-1.amazoncognito.com/oauth2/token" client_id = "<client ID to be found in AWS Console>" callback_url = "https://medical.chunlinprojects.com/authy-callback"
A successful response from the token endpoint typically is a JSON object which includes:
access_token: Used to access protected resources;
id_token: Contains identity information about the user;
refresh_token: Used to obtain new access tokens;
expires_in: Lifetime of the access token in seconds.
Hence we can retrieve the medical records if there is an access_token but return an “HTTP 401 Unauthorized” response if there is no access_token returned.
if 'access_token' not in tokens: return { 'statusCode': 401, 'body': get_401_web_content(), 'headers': { 'Content-Type': 'text/html' } }
The function get_401_web_content is responsible to retrieve a static web page showing 401 error message from the S3 bucket and return it to the frontend, as shown in the code below.
For the get_web_content function, we will be passing the access token to the Lambda that we developed earlier to retrieve the HTML content from the Object Lambda Access Point. As shown in the following code, we invoke the Lambda function synchronously and wait for the response.
In the Lambda function lunar-medicalrecords-frontend, we will no longer need to hardcode the object key as chunlin.json. Instead, we can just retrieve the user name from the Cognito using the access token, as highlighted in bold in the code below.
... import boto3
cognito_idp_client = boto3.client('cognito-idp')
def lambda_handler(event, context): if 'access_token' not in event: return { 'statusCode': 200, 'body': get_homepage_web_content(), 'headers': { 'Content-Type': 'text/html' } }
The get_homepage_web_content function above basically is to retrieve a static homepage from the S3 bucket. It is similar to how the get_401_web_content function above works.
The homepage comes with a Login button redirecting users to Hosted UI of our Cognito app client.
Step 5: Store Access Token in Cookies
We need to take note that the auth_code above in the OAuth 2.0 authorisation code grant flow can only be used once. This is because single-use auth_code prevents replay attacks where an attacker could intercept the authorisation code and try to use it multiple times to obtain tokens. Hence, our implementation above will break if we refresh our web page after logging in.
To solve this issue, we will be saving the access token in a cookie when the user first signs in. After that, as long as we detect that there is a valid access token in the cookie, we will not use the auth_code.
In order to save an access token in a cookie, there are several important considerations to ensure security and proper functionality:
Set the Secure attribute to ensure the cookie is only sent over HTTPS connections. This helps protect the token from being intercepted during transmission;
Use the HttpOnly attribute to prevent client-side scripts from accessing the cookie. This helps mitigate the risk of cross-site scripting (XSS) attacks;
Set an appropriate expiration time for the cookie. Since access tokens typically have a short lifespan, ensure the cookie does not outlive the token’s validity.
Thus the code at Step 3 above can be improved as follows.
def lambda_handler(event, context): now = datetime.now(timezone.utc)
if 'cookies' in event: for cookie in event['cookies']: if cookie.startswith('access_token='): access_token = cookie.replace("access_token=", "") break
After we have developed a GUI desktop application using PyQt5, we need to distribute it to the users to use it. Normally the users are not developers, so giving them the source code of our application is not a good idea. Hence, in this article, we will discuss how we can use PyInstaller to package the application into an exe file on Windows.
Step 0: Setup Hello World Project
Our life will be easy if we start packaging our application in the very beginning. This is because as we add more features and dependencies to the application, we can easily confirm the packaging is still working. If there is anything wrong during the packaging, we can easily debug by just checking the newly added codes instead of debugging the entire app.
So, let’s start with a PyQt5 desktop application which has a label showing “Hello World”.
Currently PyInstaller works only up to Python 3.8. So, I will first create a virtual environment which uses Python 3.8 with the following command. Since I have many versions of Python installed on my machine, I simply use the path to the Python 3.8 in the command.
C:\Users\...\Python38\python.exe -m venv venv
After that, we can activate the virtual environment in VS Code by choosing the interpreter, as shown in the following screenshot.
VS Code will prompt us the recommended interpreter to choose for the project.
After that, we will install PyQt5 5.15.4 and Qt-Material 2.8.8 packages for the GUI. Once the two packages are installed in the virtual environment, we can proceed to design our Hello World app with the following codes in a file called main.py.
Hence, running the command above will generate two new folders, i.e. build and dist, as well as a main.spec file in the project directory.
A new file main.spec and two new folders, build and dist, will be generated by PyInstaller.
It is important to take note that the PyInstaller output is specific to the active OS and the active version of Python. In this case, our distribution is for Windows under Python 3.8.
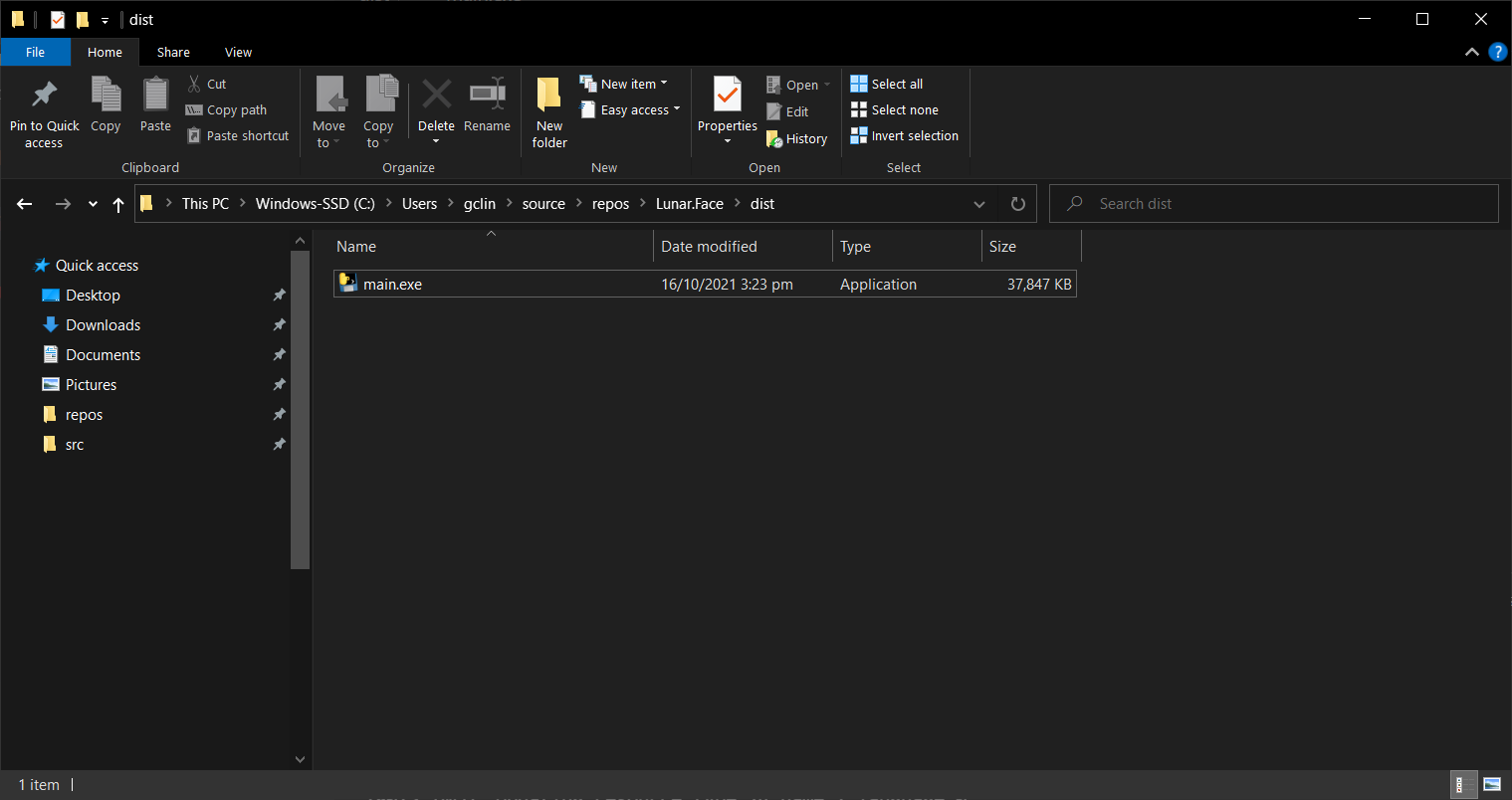
The dist folder will be the folder we can distribute to end users to use our app. The folder has our application, i.e. main.exe, together with other dlls.
End users of our app just need to run the main.exe in the dist/main folder to use our app.
Finally, the main.spec is a SPEC file which contains the PyInstaller packaging configuration and instructions. Hence, for future packaging operations, we shall execute the following command instead.
pyinstaller main.spec
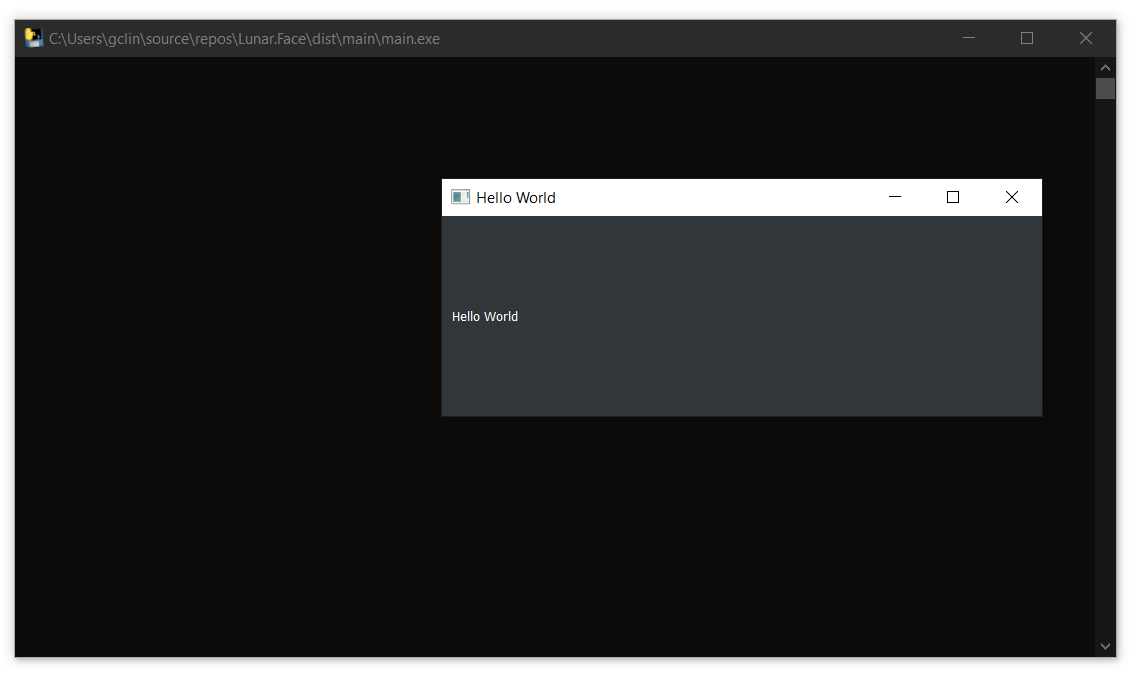
Now, when we run the main.exe, we will be able to see our Hello World application. However, at the same time, there would be a console window shown together by default, as demonstrated below.
A console window will be shown together with our desktop application.
The console window by right should be hidden from the end users. So, in the following step, we will see how we can configure the PyInstaller packaging to hide the console window.
The SPEC file is actually a Python code. It contains the following classes.
Analysis: Takes a list of script file names as input and analyses the dependencies;
PYZ: PYZ stands for Python Zipped Executable, contains all the Python modules needed by the script(s);
EXE: Creates the executable file, i.e. main.exe in our example, based on Analysis and PYZ;
COLLECT: Creates the output folder from all the other parts. This class is removed in the one-file mode.
Step 2.1 Setup one-file Build
As we can see earlier, the dist folder does not only contain the executable file, main.exe, but also a long list of DLLs. It’s normally not a good idea to give the end users a huge folder like this as the users may have a hard time figuring out how to launch our app. So, we can create a one-file build for our app instead.
To do so, we can execute the following command. To make things clearer, we can also choose to delete the dist folder generated earlier before running the command.
pyinstaller --onefile main.py
After it is executed successfully, in the dist folder, we can see that there is only one executable file, as shown in the following screenshot. Now, we can just send the end users only this one executable file to run our app.
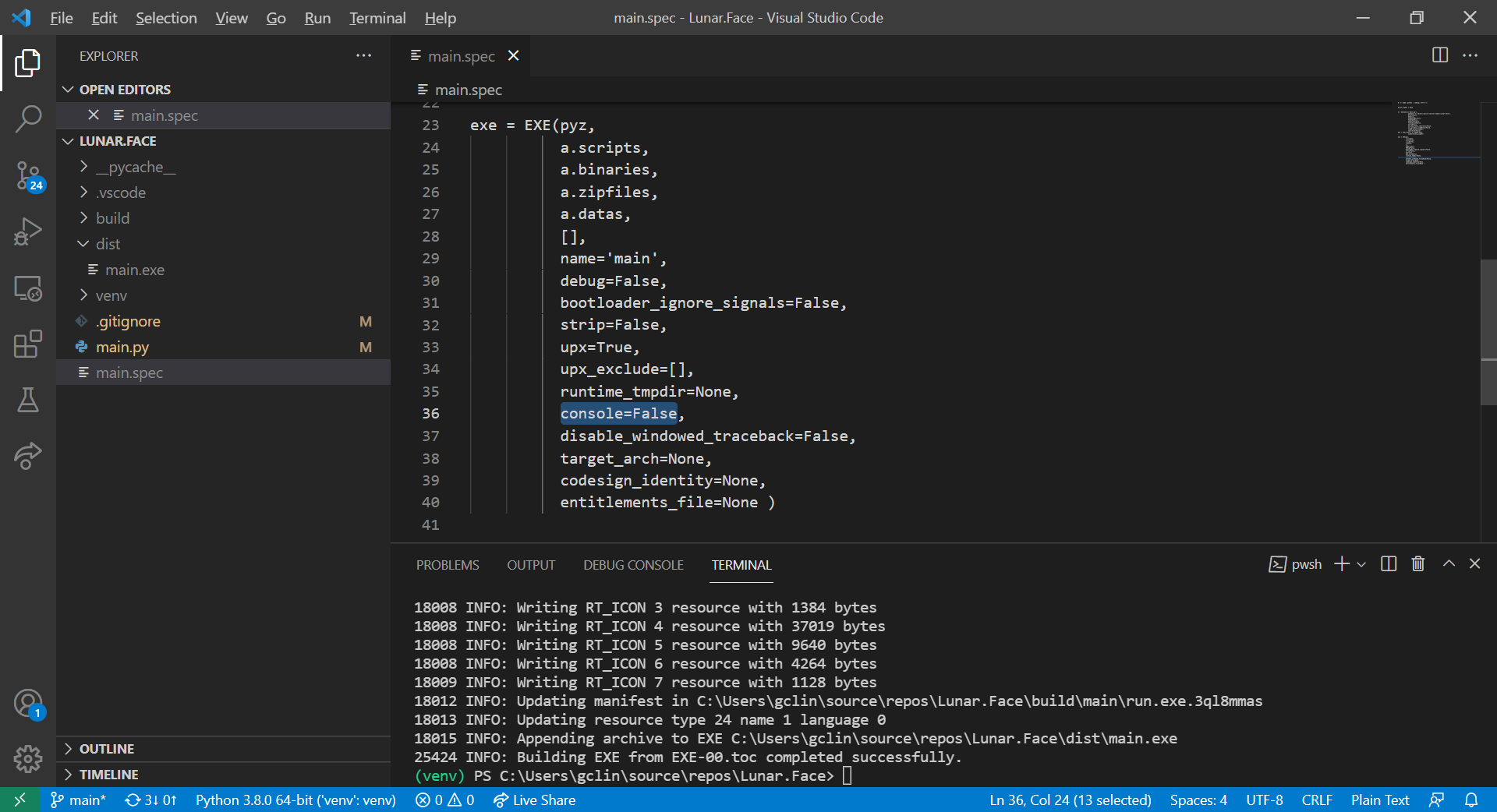
The first change that we can make to the SPEC file is to remove the default console window. To do so, we simply need to set console=False in the EXE, as shown in the screenshot below.
Hid the default console window.
With this being set, the app will not be launched with a console window showing together.
Step 2.3 Bundle Data Files
Let’s say we would like to have an app icon for our app, we can have the following line added in our main.py.
This will load the image file logo.png from the resources/images directory. In this scenario, we thus need to find a way to bundle image files in the build. To do so, we can first update our SPEC files as follows.
Telling PyInstaller to copy the resources folder.
The list of data files is a list of tuples where each tuple has two strings.
The first string specifies the file or files as they are in this system now;
The second specifies the name of the folder to contain the files at run-time.
If we’re not using the one-file build, we will find out that the data files will be copied to the dist folder accordingly. However, if we are app is built with one-file mode, then we shall change our code accordingly to locate the data files at runtime.
def resource_path(relative_path):
""" Get absolute path to resource, works for dev and for PyInstaller """
if getattr(sys, 'frozen', False) and hasattr(sys, '_MEIPASS'):
base_path = sys._MEIPASS
else:
base_path = os.path.abspath(".")
return os.path.join(base_path, relative_path)
Secondly, we need to update the code getting the QIcon path to be something as follows.
Finally, we will be able to see our app icon displayed correctly, as shown in the following screenshot.
Yay, the app icon is updated!
Step 2.4 Setup EXECUTABLE App Icon
Even though the app icon has been updated, however, the icon of our executable is still not yet updated.
Before we can proceed to update the exe icon, we need to know that, on Windows, only .ico file can be used as icon image. Since our logo is a png file, we shall convert it to an ico file first. To do the conversion, I’m using ICO Convert which is available online for free and mentioned in one of the PyInstaller GitHub issues.
After getting the ICO file, we shall put it in the same directory as the SPEC file. Next, we can customise the SPEC file by adding icon parameter to the EXE as shown below.
Setting app icon for our app executable file.
Once the build is successful, we can refresh our dist folder and will find that our main.exe now has a customised icon, as shown below.
Yay, our exe file has customised icon as well now!
Step 2.5 Name Our App
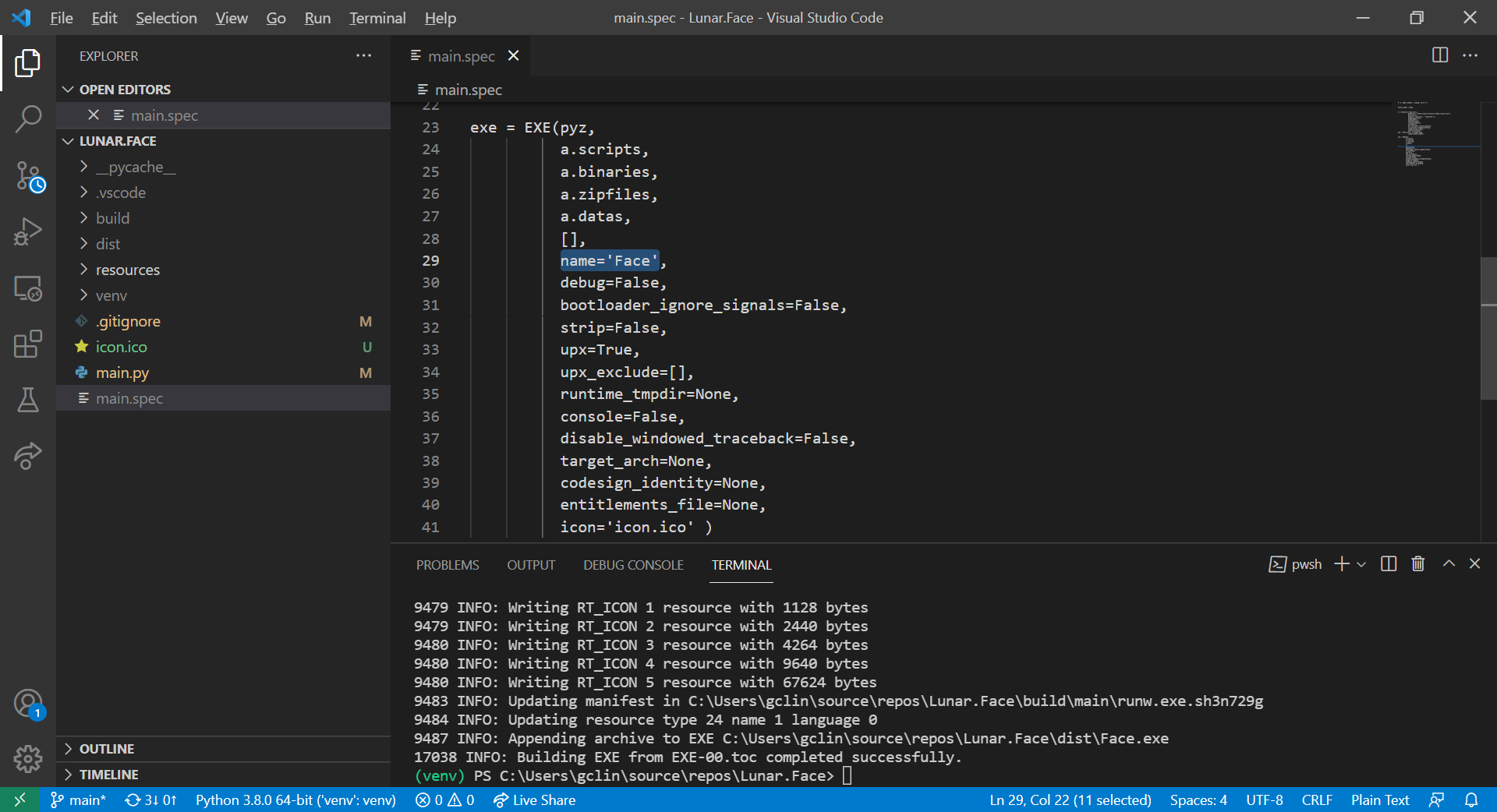
By default, the executable file generated has the name of our source file. Hence, in this example, the executable file is named as main.exe. By updating our SPEC file, we can also name the executable file with a more user friendly name.
What we need to do is just editing the name of EXE, as shown in the following screenshot.
We will now get the executable file of our app as Face.exe.
Conclusion
That’s all for the quickstart steps to package our PyQt5 desktop GUI application with PyInstaller on Windows 10.