
We have a static website for marketing purpose hosting on Amazon S3 buckets. S3 offers a pay-as-you-go model, which means we only pay for the storage and bandwidth used. This can be significantly cheaper than traditional web hosting providers, especially for websites with low traffic.
However, S3 is designed as a storage service, not a web server. Hence, it lacks many features found in common web hosting providers. We thus decide to use AWS Lambda to power our website.
AWS Lambda and .NET 6
AWS Lambda is a serverless service that runs code for backend service without the need to provision or manage servers. Building serverless apps means that we can focus on our web app business logic instead of worrying about managing and operating servers. Similar to S3, Lambda helps to reduce overhead and lets us reclaim time and energy that we can spent on developing our products and services.
Lambda natively supports several programming languages such as Node.js, Go, and Python. In February 2022, the AWS team announced that .NET 6 runtime can be officially used to build Lambda functions. That means now Lambda also supports C#10 natively.
So as the beginning, we will setup the following simple architecture to retrieve website content from S3 via Lambda.

API Gateway
When we are creating a new Lambda service, we have the option to enable the function URL so that a HTTP(S) endpoint will be assigned to our Lambda function. With the URL, we can then use it to invoke our function through, for example, an Internet browser directly.
The Function URL feature is an excellent choice when we seek rapid exposure of our Lambda function to the wider public on the Internet. However, if we are in search of a more comprehensive solution, then opting for API Gateway in conjunction with Lambda may prove to be the better choice.
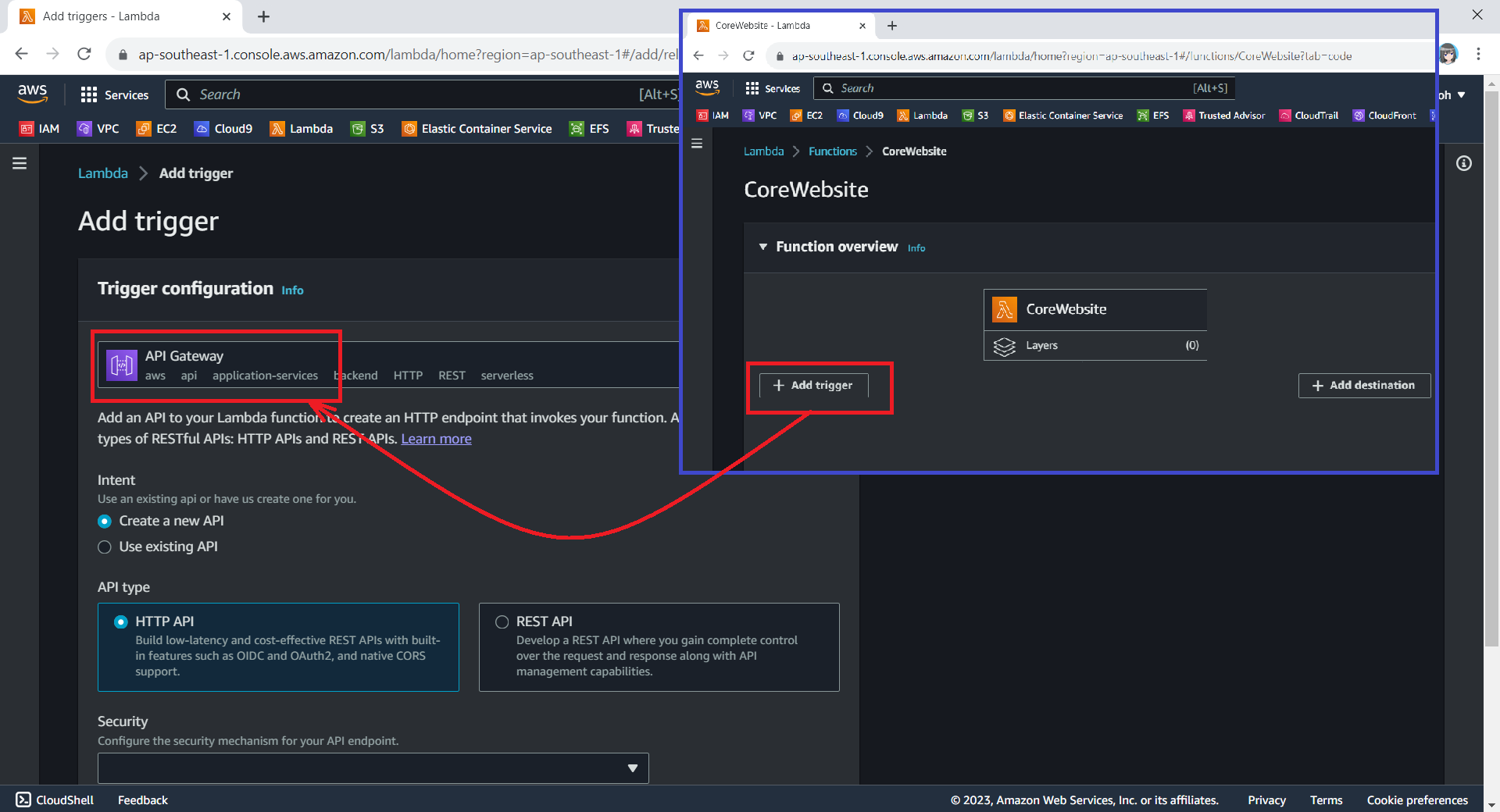
Using API Gateway also enables us to invoke our Lambda function with a secure HTTP endpoint. In addition, it can do a bit more, such as managing large volumes of calls to our function by throttling traffic and automatically validating and authorising API calls.
Keeping Web Content in S3
Now, we will create a new S3 bucket called “corewebsitehtml” to store our web content files.
We then can upload our HTML file for our website homepage to the S3 bucket.

Retrieving Web Content from S3 with C# in Lambda
With our web content in S3, the next issue will be retrieving the content from S3 and returning it as response via the API Gateway.
According to performance evaluation, even though C# is the slowest on a cold start, it is one of the fastest languages if few invocations go one by one.
The code editor on AWS console does not support the .NET 6 runtime. Thus, we have to install the AWS Toolkit for Visual Studio, so that we can easily develop, debug, and deploy .NET applications using AWS, including the AWS Lambda.
Here, we will use the AWS SDK for reading the file from S3 as shown below.
public async Task<APIGatewayProxyResponse> FunctionHandler(APIGatewayProxyRequest request, ILambdaContext context)
{
try
{
RegionEndpoint bucketRegion = RegionEndpoint.APSoutheast1;
AmazonS3Client client = new(bucketRegion);
GetObjectRequest s3Request = new()
{
BucketName = "corewebsitehtml",
Key = "index.html"
};
GetObjectResponse s3Response = await client.GetObjectAsync(s3Request);
StreamReader reader = new(s3Response.ResponseStream);
string content = reader.ReadToEnd();
APIGatewayProxyResponse response = new()
{
StatusCode = (int)HttpStatusCode.OK,
Body = content,
Headers = new Dictionary<string, string> { { "Content-Type", "text/html" } }
};
return response;
}
catch (Exception ex)
{
context.Logger.LogWarning($"{ex.Message} - {ex.InnerException?.Message} - {ex.StackTrace}");
throw;
}
}
As shown in the code above, we first need to specify the region of our S3 Bucket, which is Asia Pacific (Singapore). After that, we also need to specify our bucket name “corewebsitehtml” and the key of the file which we are going to retrieve the web content from, i.e. “index.html”, as shown in the screenshot below.

Deploy from Visual Studio
After ew have done the coding of the function, we can right click on our project in the Visual Studio and then choose “Publish to AWS Lambda…” to deploy our C# code to Lambda function, as shown in the screenshot below.

After that, we will be prompted to key in the name of the Lambda function as well as the handler in the format of <assembly>::<type>::<method>.
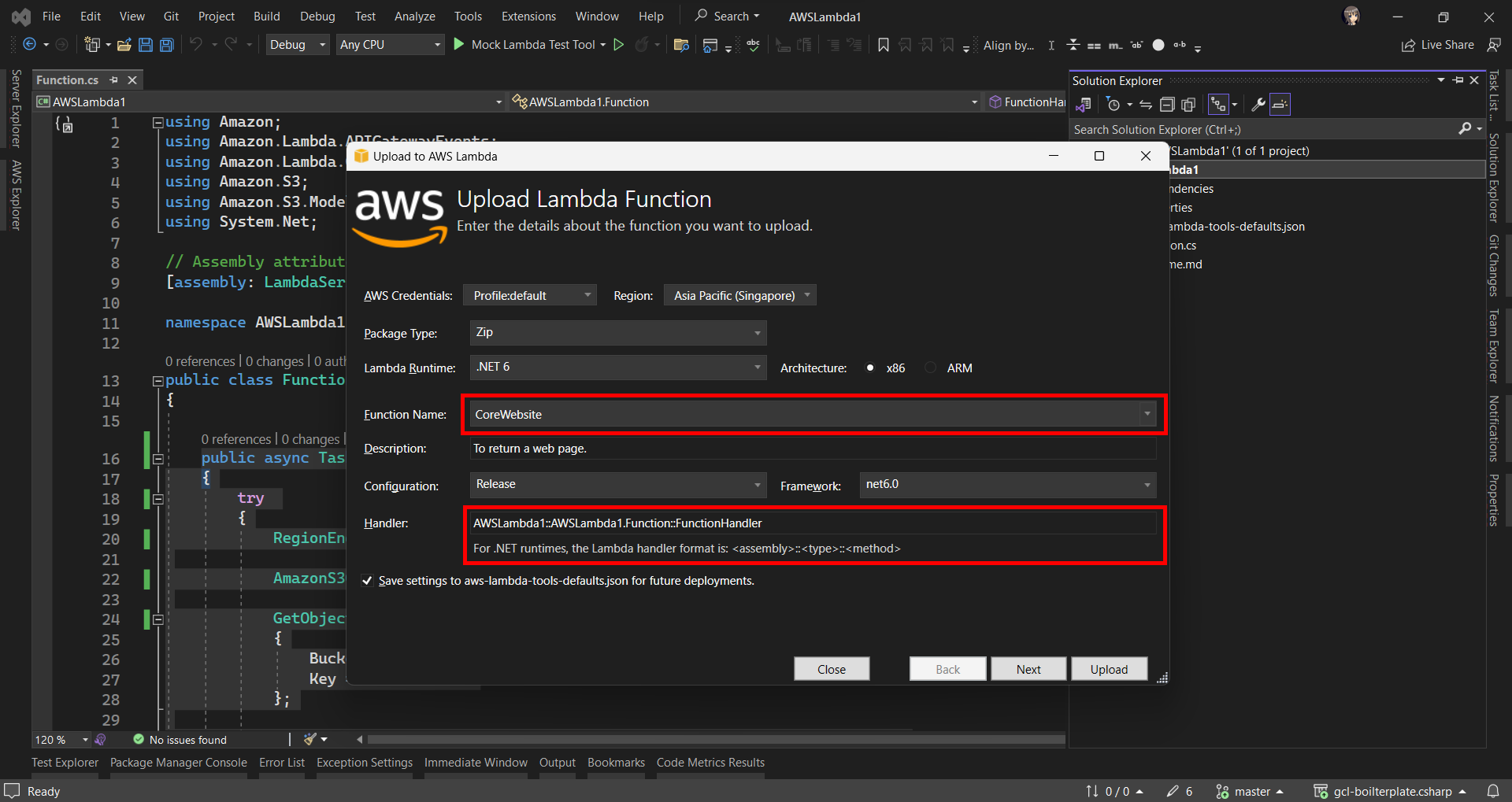
Then we are good to proceed to deploy our Lambda function.
Logging with .NET in Lambda Function
Now when we hit the URL of the API Gateway, we will receive a HTTP 500 internal server error. To investigate, we need to check the error logs.
Lambda logs all requests handled by our function and automatically stores logs generated by our code through CloudWatch Logs. By default, info level messages or higher are written to CloudWatch Logs.
Thus, in our code above, we can use the Logger to write a warning message if the file is not found or there is an error retrieving the file.
context.Logger.LogWarning($"{ex.Message} - {ex.InnerException?.Message} - {ex.StackTrace}");
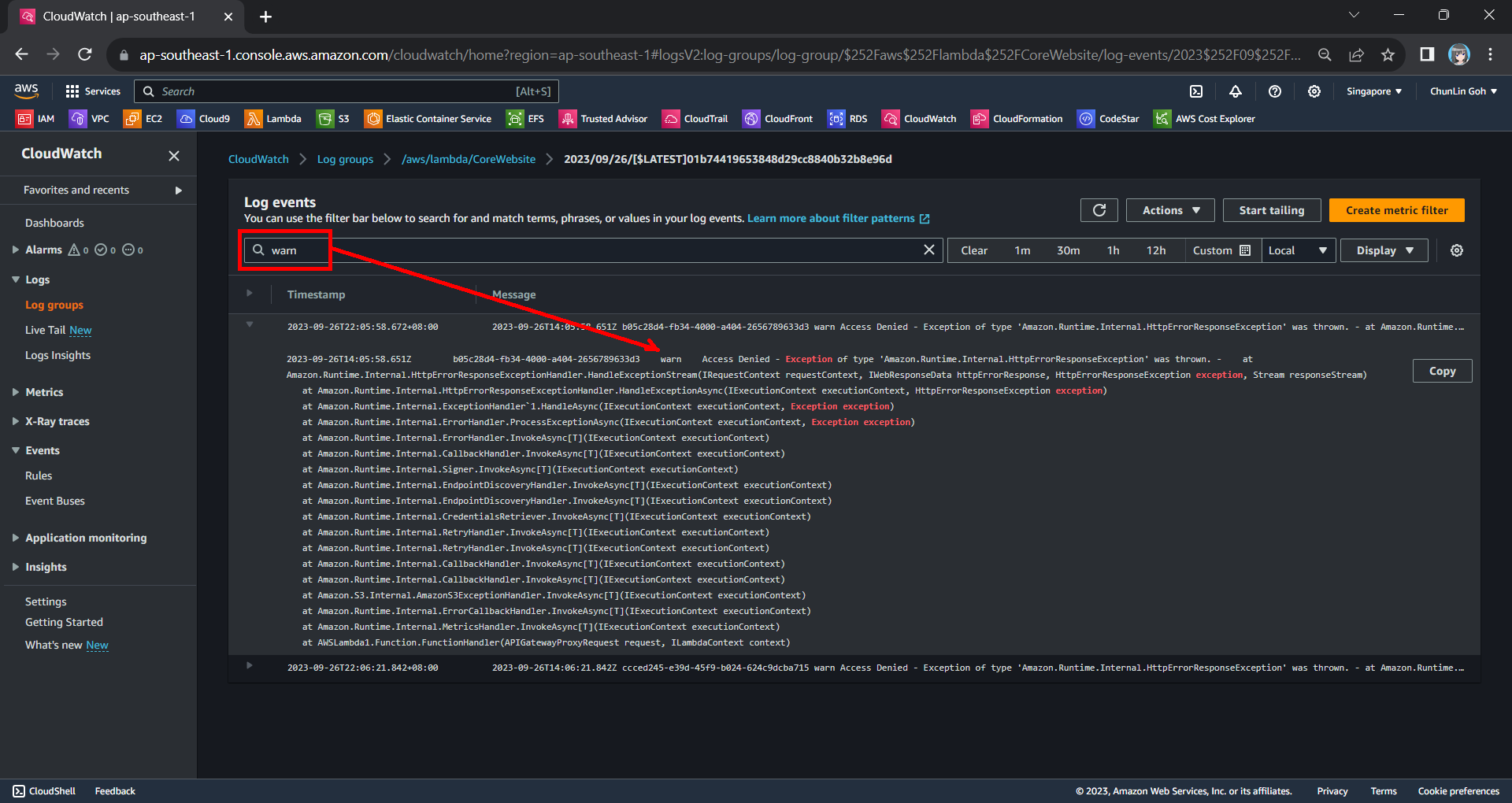
Hence, now if we access our API Gateway URL now, we should find a warning log message in our CloudWatch, as shown in the screenshot below. The page can be accessed from the “View CloudWatch logs” button under the “Monitor” tab of the Lambda function.
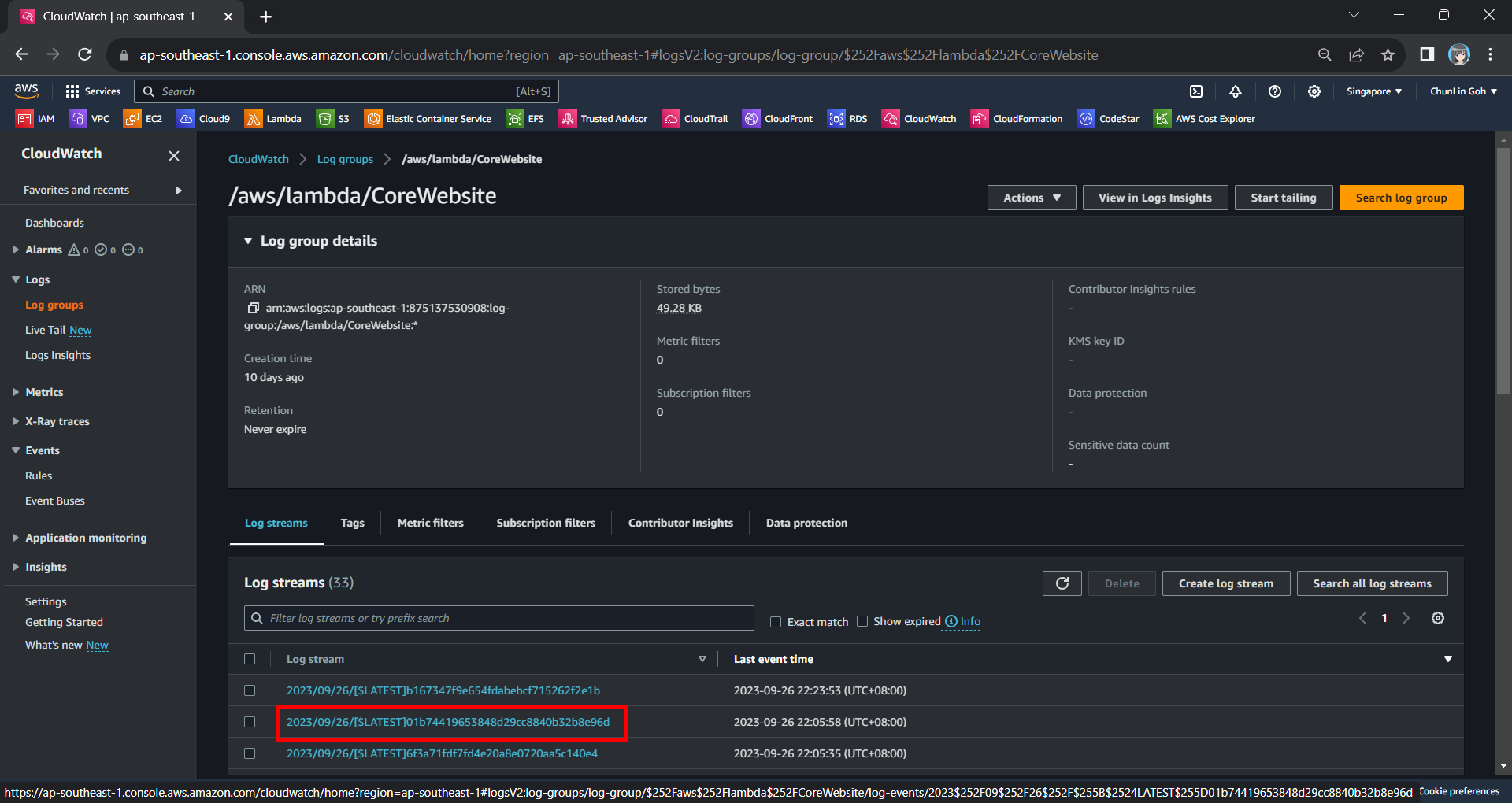
From one of the log streams, we can filter the results to list only those with the keyword “warn”. From the log message, we then know that our Lambda function has access denied from accessing our S3 bucket. So, next we will setup the access accordingly.
Connecting Lambda and S3
Since both our Lambda function and S3 bucket are in the same AWS account, we can easily grant the access from the function to the bucket.
Step 1: Create IAM Role
By default, Lambda creates an execution role with minimal permissions when we create a function in the Lambda console. So, now we first need to create an AWS Identity and Access Management (IAM) role for the Lambda function that also grants access to the S3 bucket.
In the IAM homepage, we head to the Access Management > Roles section to create a new role, as shown in the screenshot below.

In the next screen, we will choose “AWS service” as the Trusted Entity Type and “Lambda” as the Use Case so that Lambda function can call AWS services like S3 on our behalf.

Next, we need to select the AWS managed policies AWSLambdaBasicExecutionRole and AWSXRayDaemonWriteAccess.
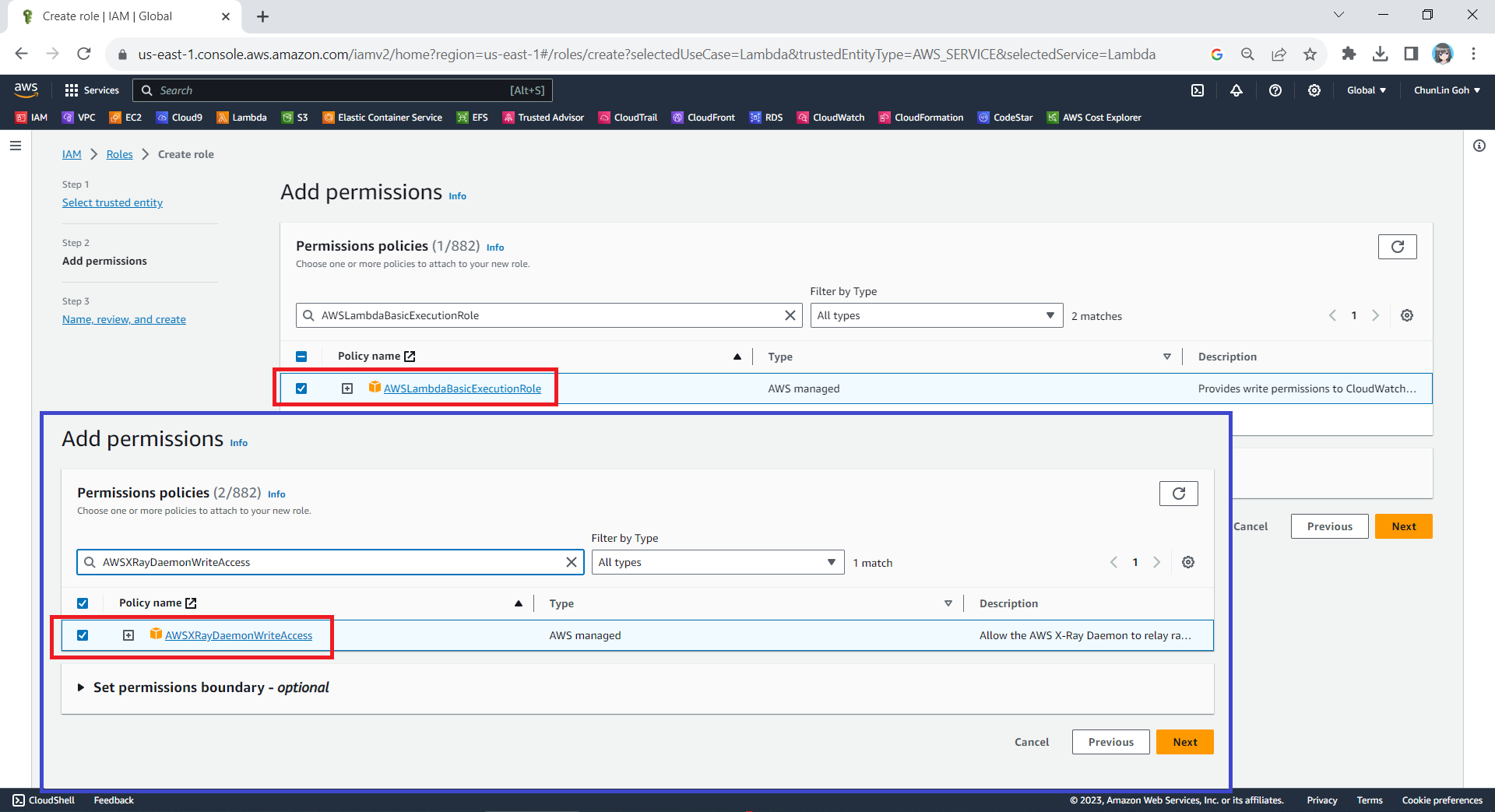
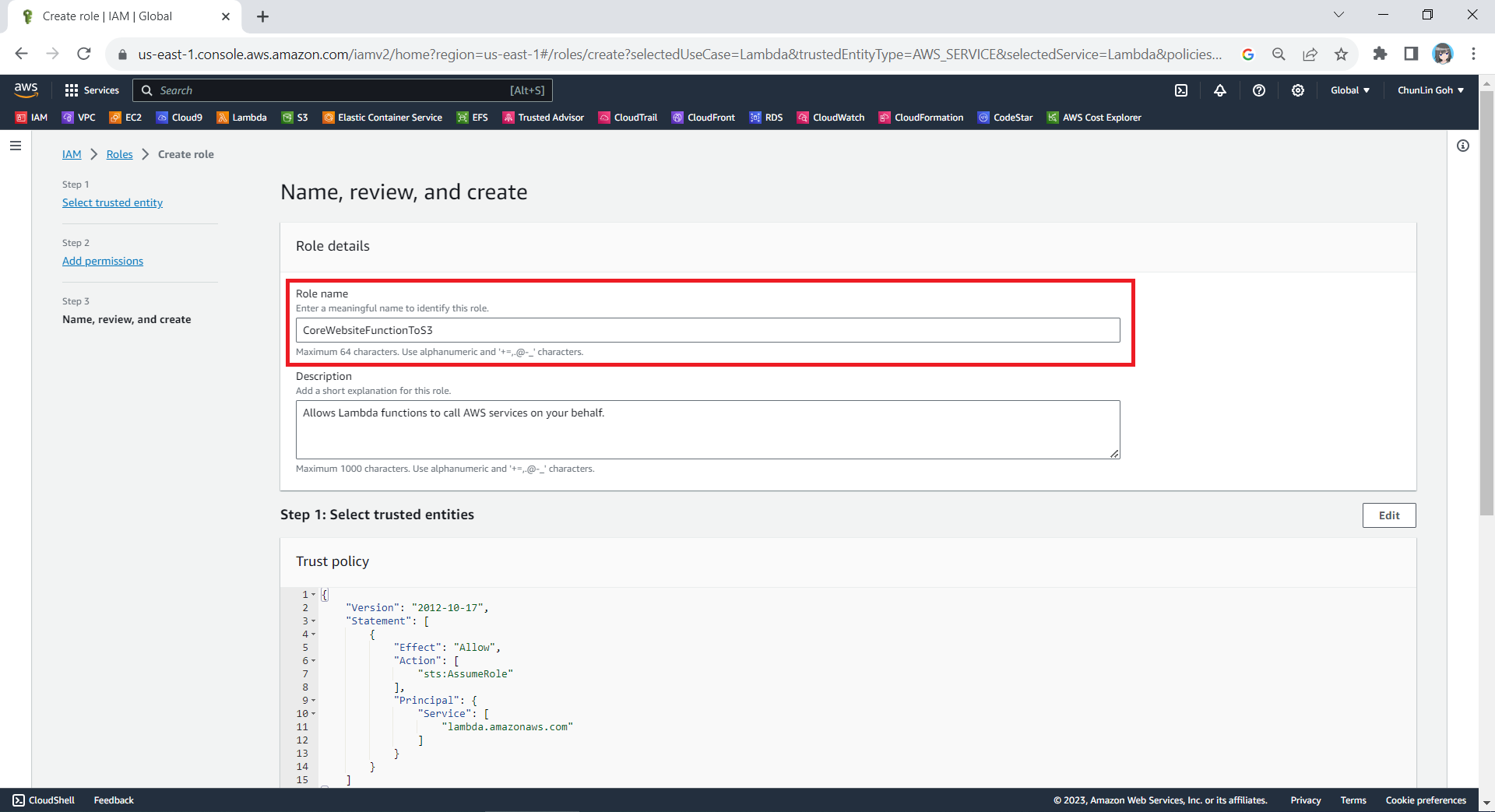
Finally, in the Step 3, we simply need to key in a name for our new role and proceed, as shown in the screenshot below.
Step 2: Configure the New IAM Role
After we have created this new role, we can head back to the IAM homepage. From the list of IAM roles, we should be able to see the role we have just created, as shown in the screenshot below.

Since the Lambda needs to assume the execution role, we need to add lambda.amazonaws.com as a trusted service. To do so, we simply edit the trust policy under the Trust Relationships tab.
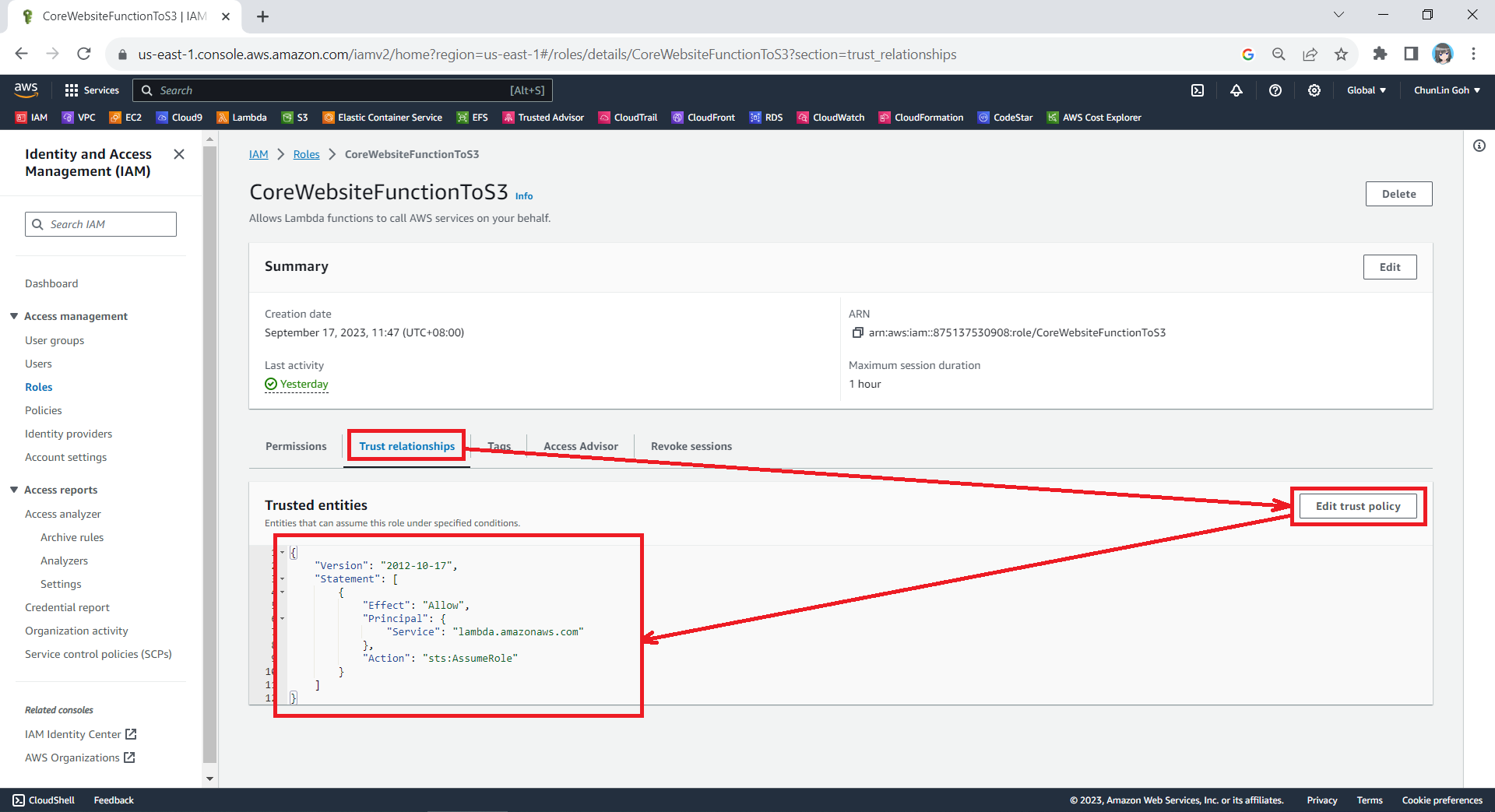
The trust policy should be updated to be as follows.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
After that, we also need to add one new inline policy under the Permissions tab.
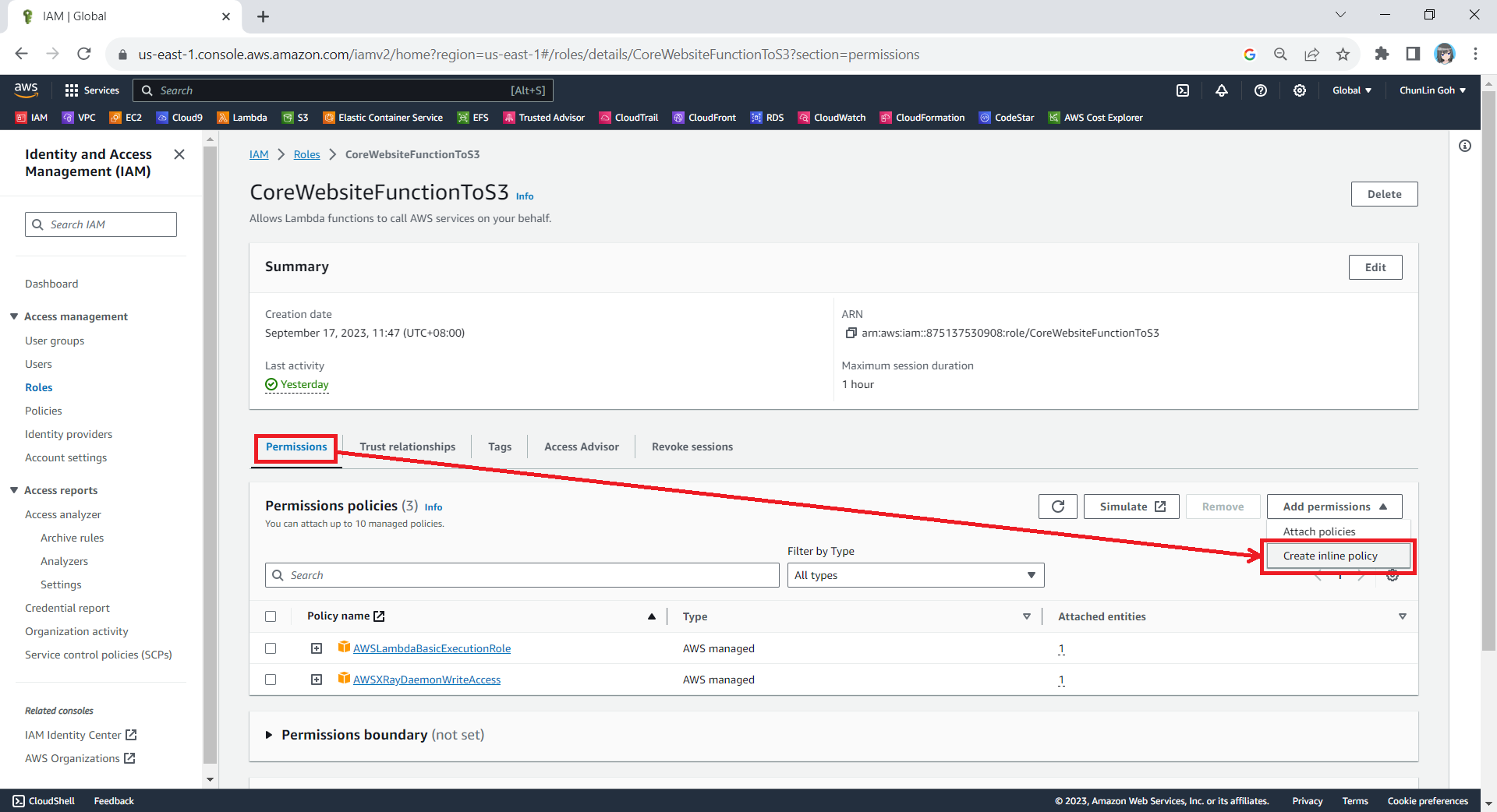
We need to grant this new role to the list and read access (s3:ListBucket and s3:GetObject) access our S3 bucket (arn:aws:s3:::corewebsitehtml) and its content (arn:aws:s3:::corewebsitehtml/*) with the following policy in JSON. The reason why we grant the list access is so that our .NET code later can tell whether the list is empty or not. If we only grant this new role the read access, the AWS S3 SDK will always return 404.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::corewebsitehtml/*",
"arn:aws:s3:::corewebsitehtml"
]
}
]
}
You can switch to the JSON editor, as shown in the following screenshot, to easily paste the JSON above into the AWS console.

After giving this inline policy a name, for example “CoreWebsiteS3Access”, we can then proceed to create it in the next step. We should now be able to see the policy being created under the Permission Policies section.
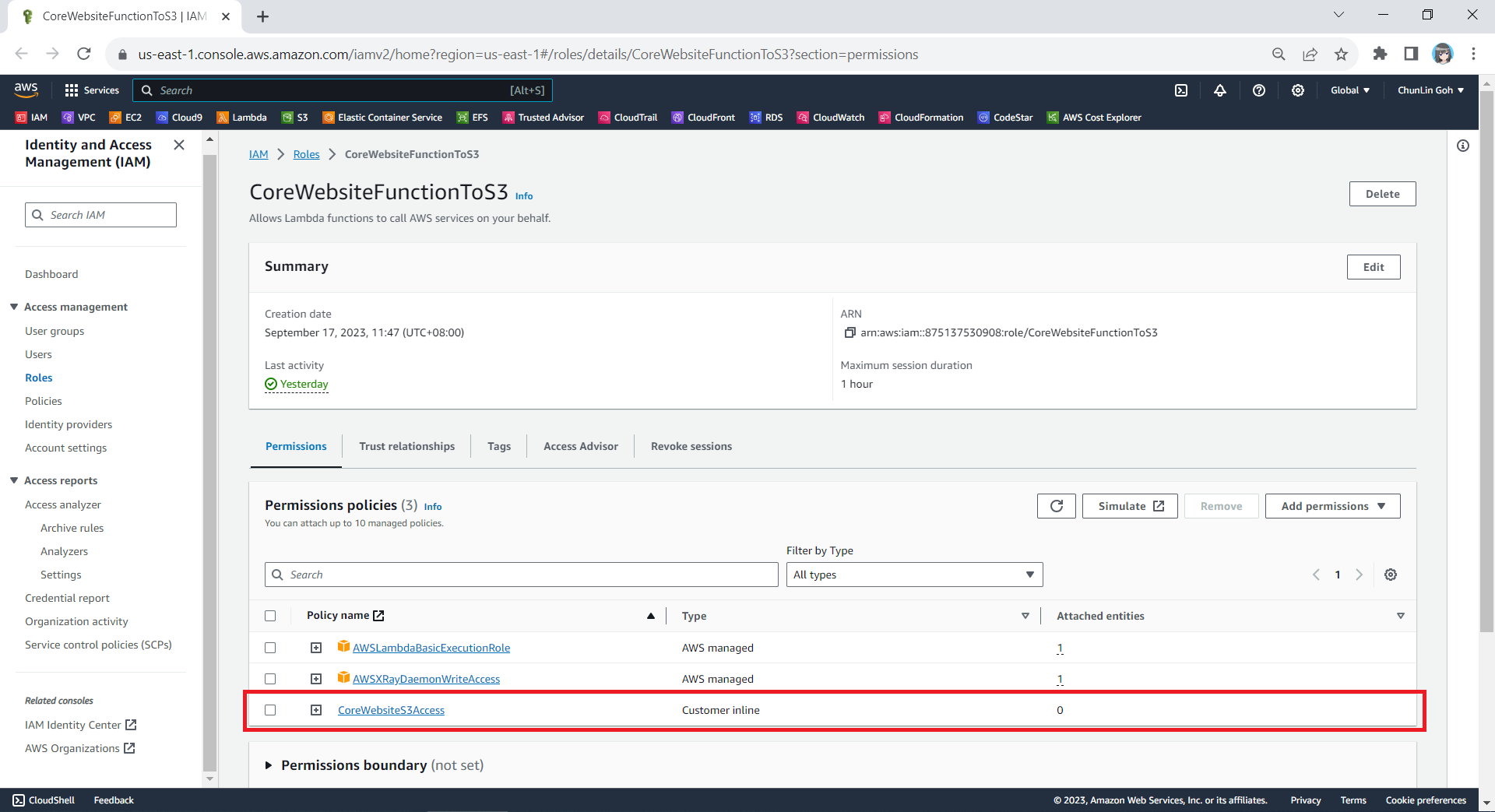
Step 3: Set New Role as Lambda Execution Role
So far we have only setup the new IAM role. Now, we need to configure this new role as the Lambda functions execution role. To do so, we have to edit the current Execution Role of the function, as shown in the screenshot below.
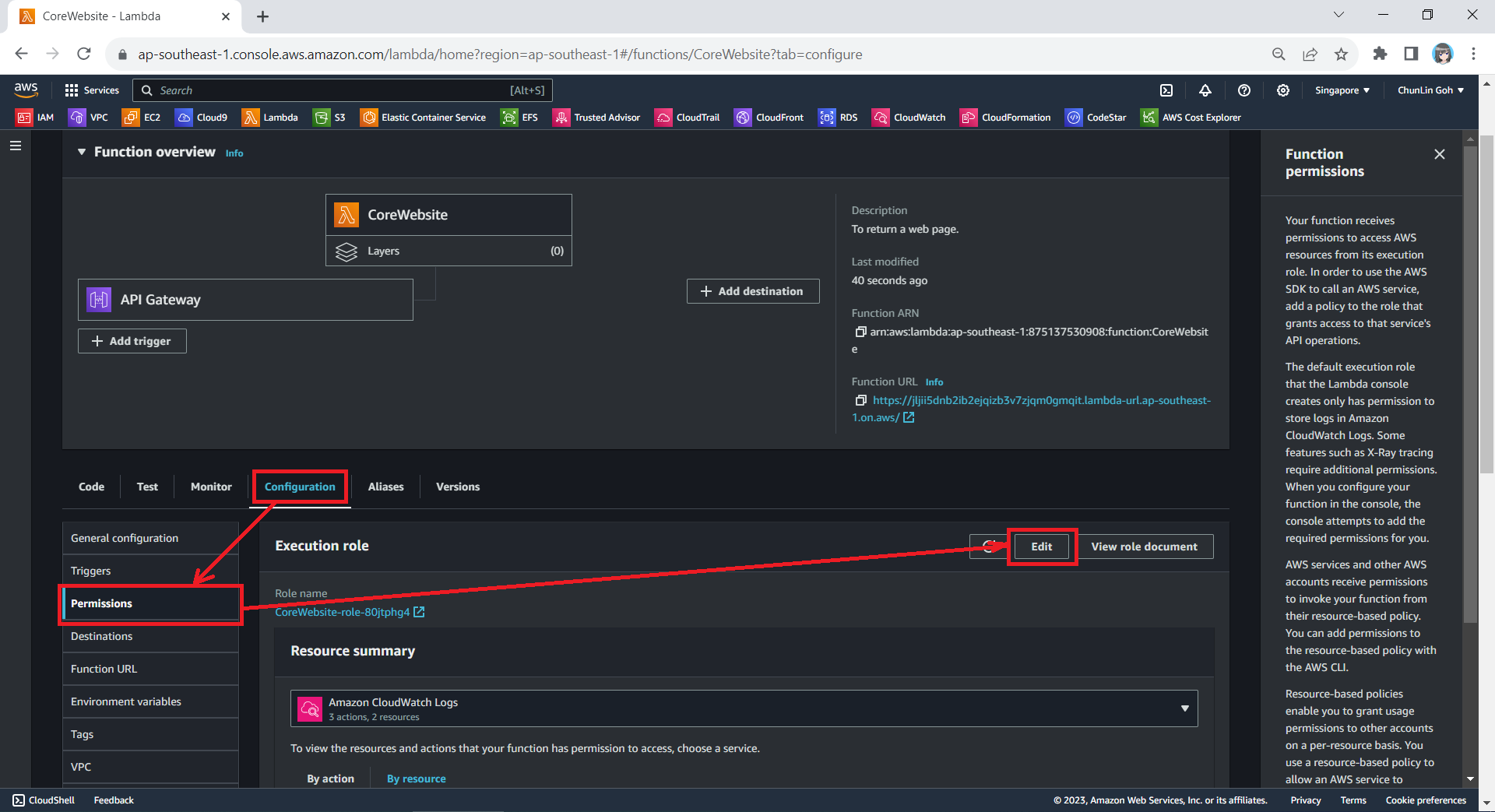
Next, we need to change the execution role to the new IAM role that we have just created, i.e. CoreWebsiteFunctionToS3.
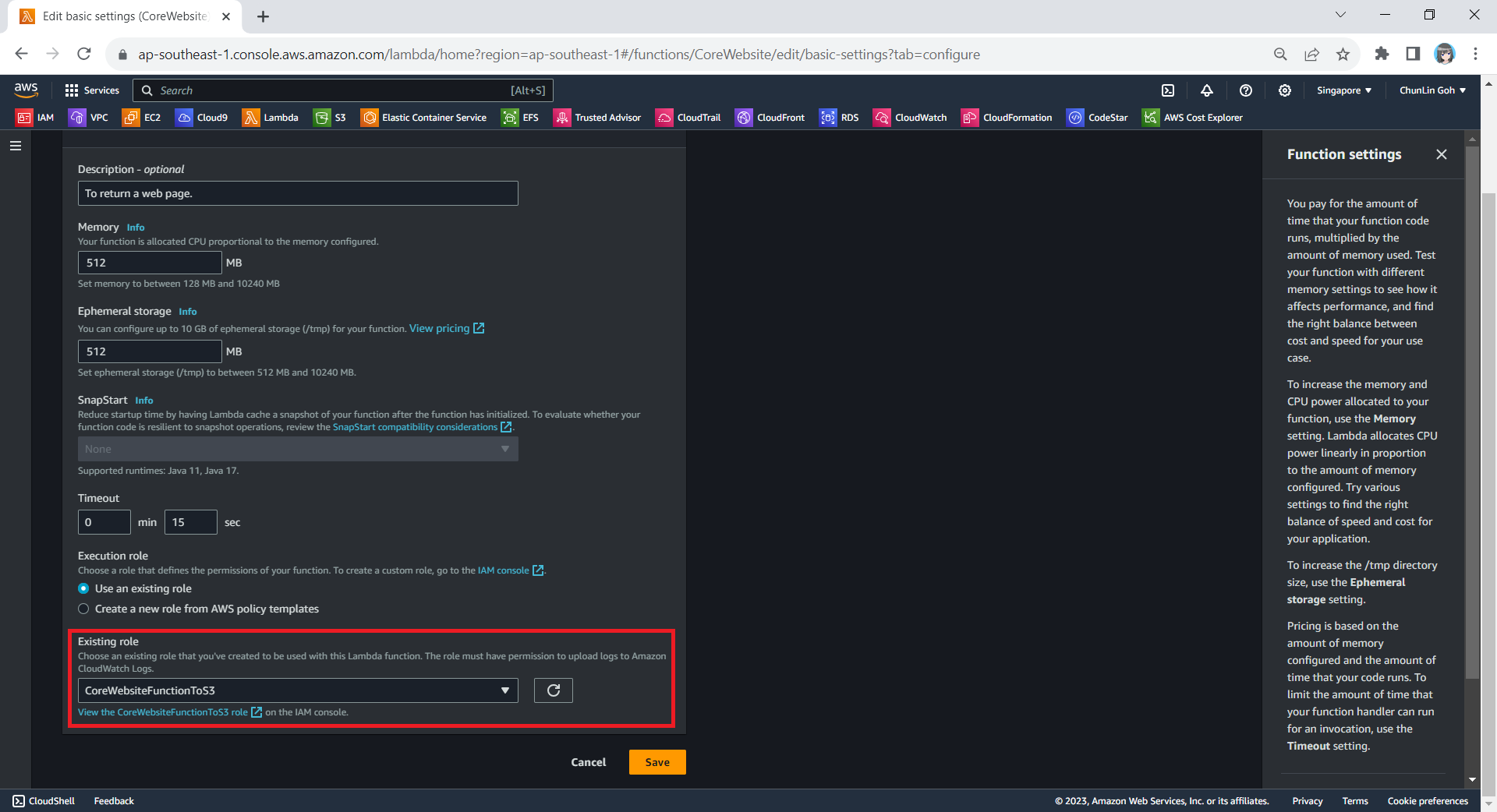
After save the change above, when we visit the Execution Role section of this function again, we should see that it can already access Amazon S3, as shown in the following screenshot.

Step 4: Allow Lambda Access in S3 Bucket
Finally, we also need to make sure that the S3 bucket policy doesn’t explicitly deny access to our Lambda function or its execution role with the following policy.
{
"Version": "2012-10-17",
"Id": "CoreWebsitePolicy",
"Statement": [
{
"Sid": "CoreWebsite",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::875137530908:role/CoreWebsiteFunctionToS3"
},
"Action": "s3:GetObject",
"Resource": [
"arn:aws:s3:::corewebsitehtml/*",
"arn:aws:s3:::corewebsitehtml"
]
}
]
}
The JSON policy above can be entered in the Bucket Policy section, as demonstrated in the screenshot below.

Setup Execution Role During Deployment
Since we have updated to use the new execution role for our Lambda function, in our subsequent deployment of the function, we should remember to set the role to be the correct role, i.e. CoreWebsiteFunctionToS3, as highlighted in the screenshot below.

After we have done all these, we shall be able to see our web content which is stored in S3 bucket to be displayed when we visit the API Gateway URL on our browser.
References
- Learn how to build a serverless web application;
- How do I allow my Lambda function access to my Amazon S3 bucket?
- Creating an execution role in the IAM console;
- Use log levels in CloudWatch Logs to generate filter-friendly logs;
- Introducing the .NET 6 runtime for AWS Lambda;
- Lambda function handler in C#;
- Create a Visual Studio .NET Core Lambda Project;
- Lambda function logging in C#.
