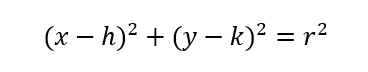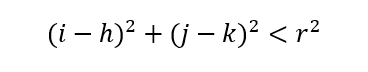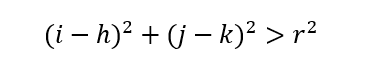I took one week leave in the following week to have some rest. I felt tired and thus I slept as much as I could in the first three days after the vaccination. In order to maintain the body hydration level, I also drank about 2 liters of plain water per day. On top of that, since the weather in Singapore was extremely warm in September, starting from three days before my vaccination day, I also bought a cup of coconut water every day.
Fortunately, to me, there was no other major side effects from the vaccine. Hence, I spent my one-week leave to do many things that I didn’t have the time to do in the normal working days.
On 6th of September, there was a session about Artificial Intelligence (AI) Fundamentals.
AI Fundamental virtual training session.
In the training session, we learnt about concepts such as, AI in Azure, common AI workloads, challenges and risks with AI, and principles of responsible AI.
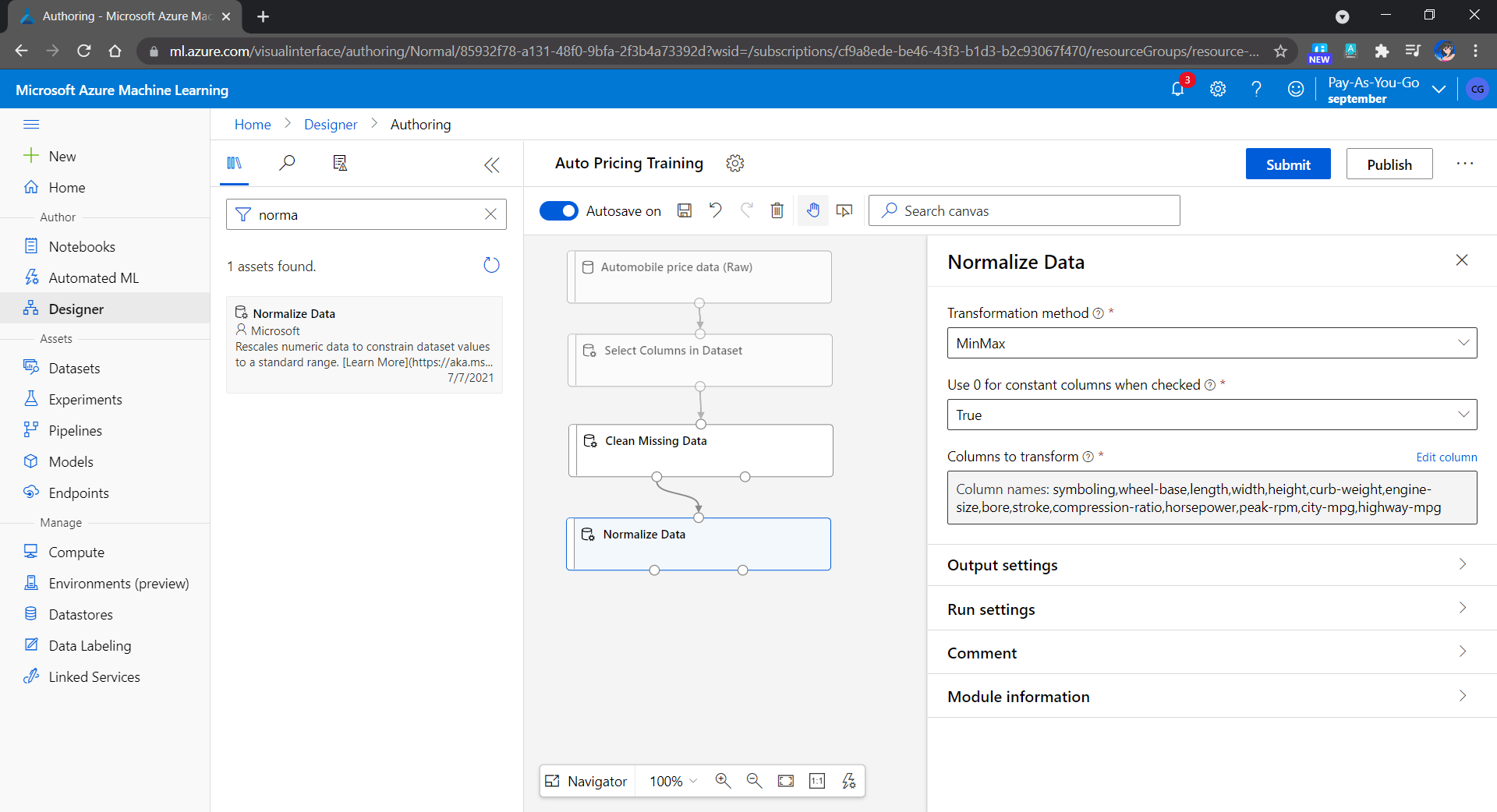
After that, we learnt how to create predictive models by finding relationships in data using Machine Learning (ML). Using Azure ML Designer, we can visually create a ML pipeline in a drag-and-drop manner.
Creating a predictive pricing model with Azure ML Designer.
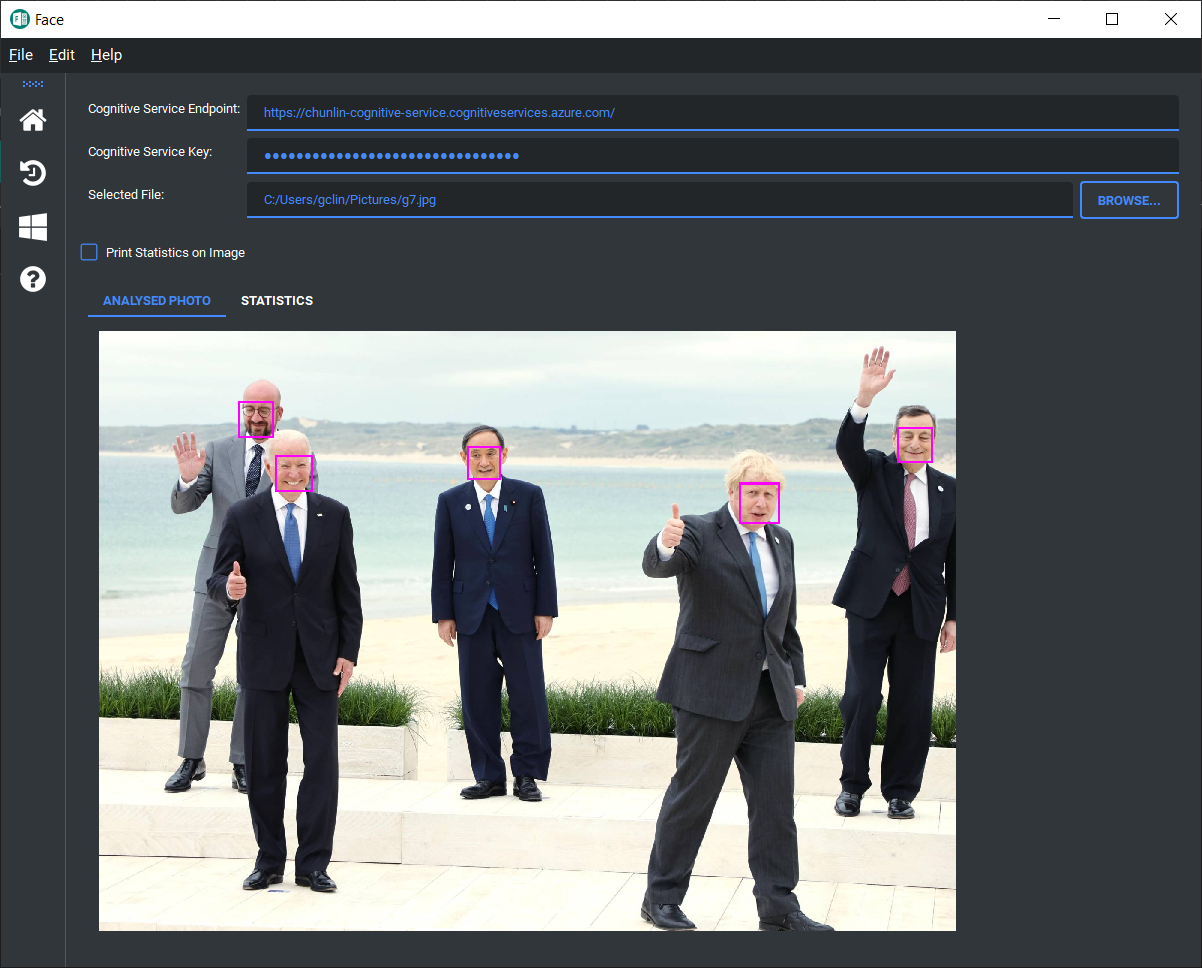
Finally, we also learnt how to use Azure Cognitive Services to analyse images, recognise faces, perform OCR.
Activity 2: Learning PyQt
I was asked by our Senior IT Architect to learn how to build a dashboard as a desktop application using Python before my leave. Hence, I also read the tutorials about PyQt5 during my leave.
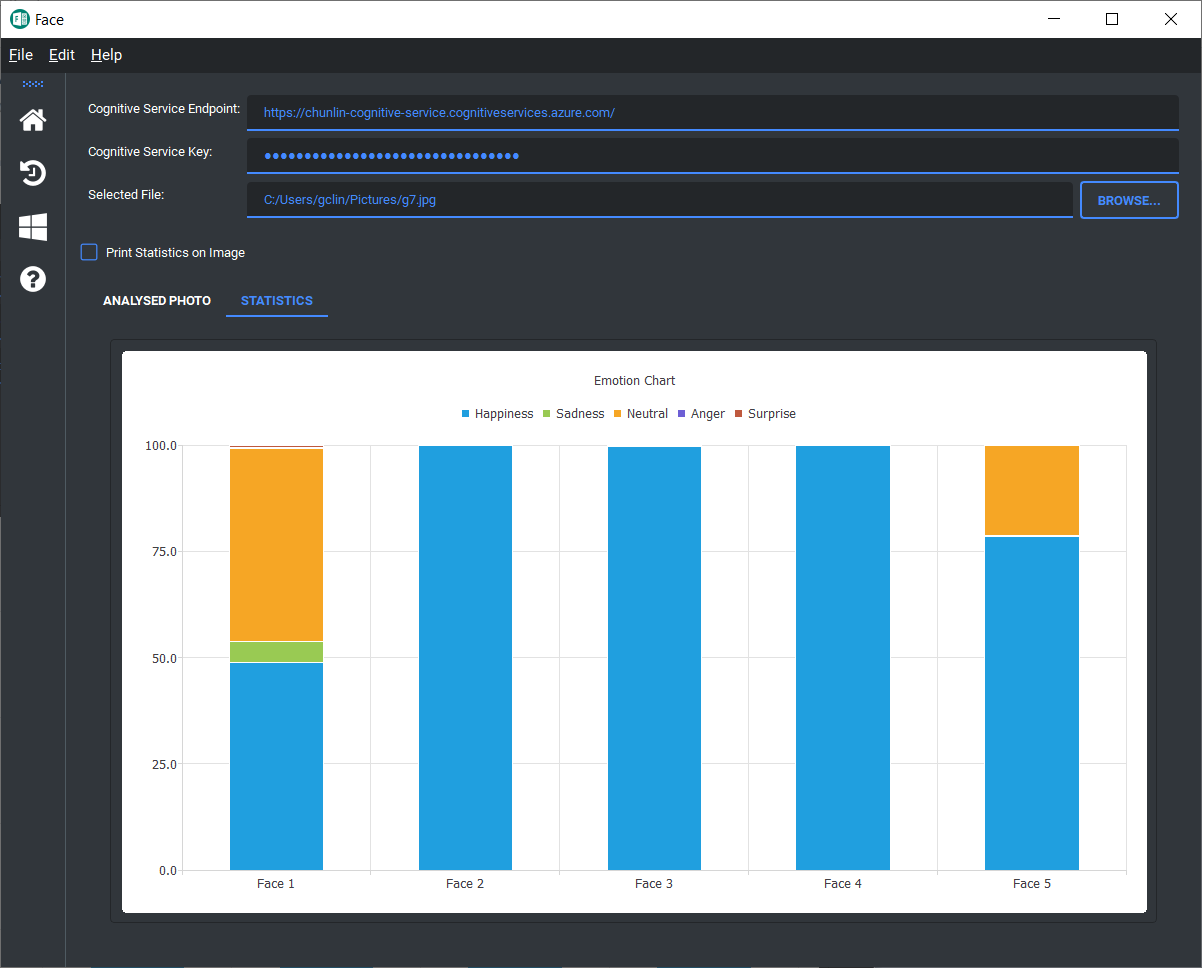
In this learning exercise, I also found out how to apply Material Design theme to a PyQt5 application using library such as Qt-Material. In addition, I also learnt how to draw charts using PyQtChart. For example, emotions of the faces detected in the screenshot above can be drawn as a chart shown in the following screenshot using the Face API.
One of the faces in the photo above looks a bit sad.
Yup, that’s all what I had done during my leave. Now, I am thinking how to clear the remaining annual leave I have brought over from the previous year.
Normally on the roads, we will see trailer trucks, which are the combination of a prime mover and a container chassis to carry freight. Container chassis is an important asset of a trucking company. It is usually an unpowered vehicle towed by another. If you still have no idea what it is, please watch the video below.
Tracking container chassis is not a simple problem to solve. We do not only need to build trackers, which are IoT devices to send back telemetry and sensor data collected from the container chassis, but also need to have another system to store, process, and display the data. This does not sound like a system that can be easily built within, let’s say, 5 minutes.
Now what if we can turn our smart phones into trackers and then install one of them on the container chassis? Also, what if we can make use of Microsoft Azure to provide a IoT data dashboard for us in just a few clicks?
Few days ago, Microsoft release a mobile app called IoT Plug and Play on both Android and iOS.
So, you may ask, why is this IoT Plug and Play interesting? This is because it can turn our iOS or Android device into an IoT device without any coding or device modeling. Our phones can then seamlessly connect to Azure IoT Central or IoT Hub with telemetry and sensor data from the devices will be automatically uploaded to the Azure in a defined delivery interval.
In this post, I am just going to share what I have tried out so far. Hopefully it helps my friends who are looking for similar solutions.
Setup Azure IoT Central
Before we proceed further, we need to understand that even though the example I use here may sound simple to you, but the services, such as Azure IoT Central is actually meant for production use so that the industries can use it to build enterprise-grade IoT applications on a secure, reliable, and scalable infrastructure.
When we are setting up Azure IoT Central, we can have a quick start by directly applying templates which are all industry focused examples available for these industries today. For example, using the templates on Azure, logistics company can create an Azure IoT Central application to track shipments in real time across air, water, and land with location and condition monitoring. This will play an important role in the logistics industry because the technology can then provide total end-to-end supply chain enablement.
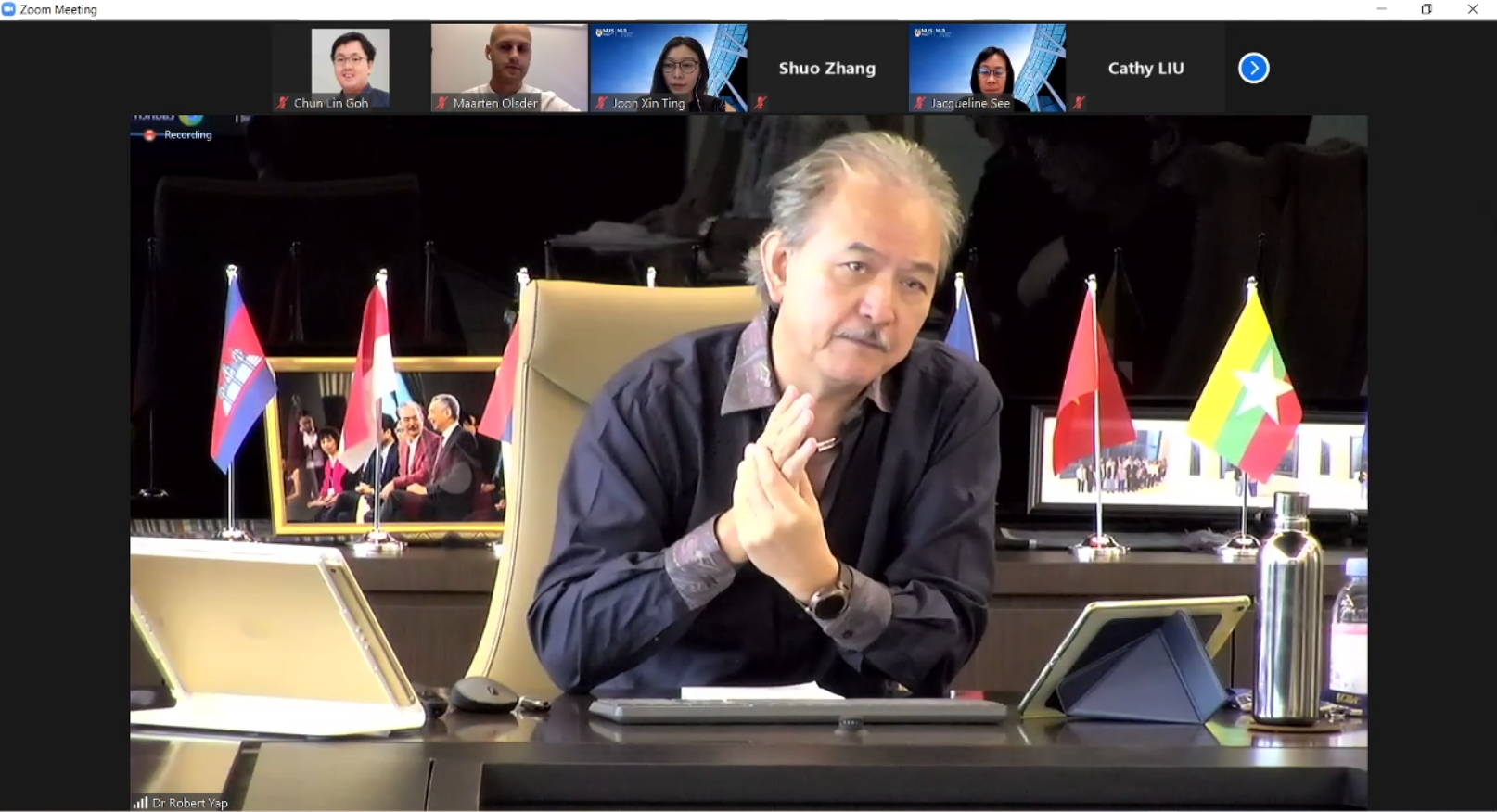
Dr Robert Yap, the Executive Chairman of YCH Group, shared about their vision of integrating the data flows in the supply chain with analytics capabilities.
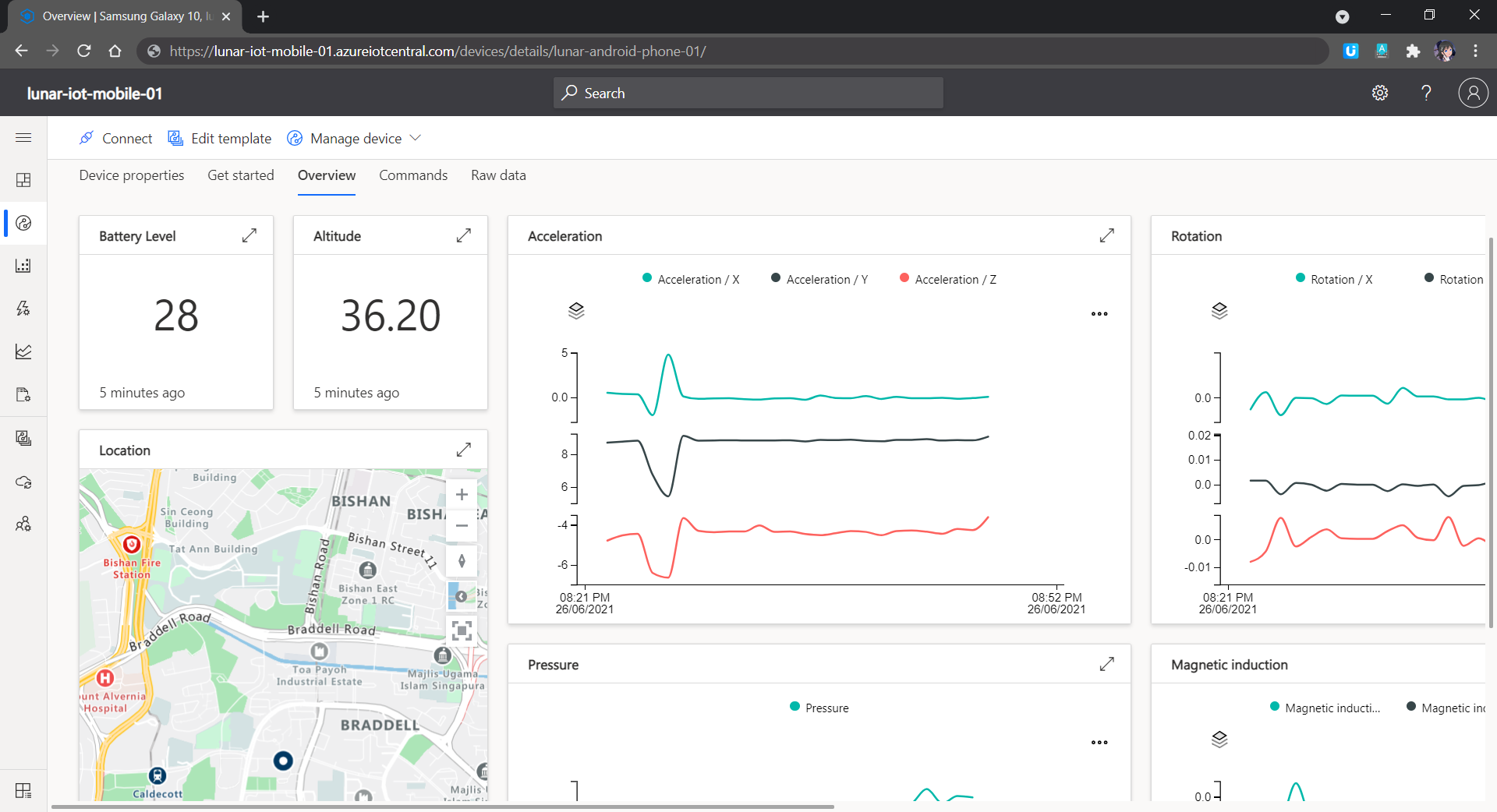
In my example, I will start with a customised template which has nothing inside. We then can proceed to the “Devices” page to add a devices for our phones.
Data collected from accelerometer, gyroscope, magnetometer, and barometer on my phone.
Rules and Triggers
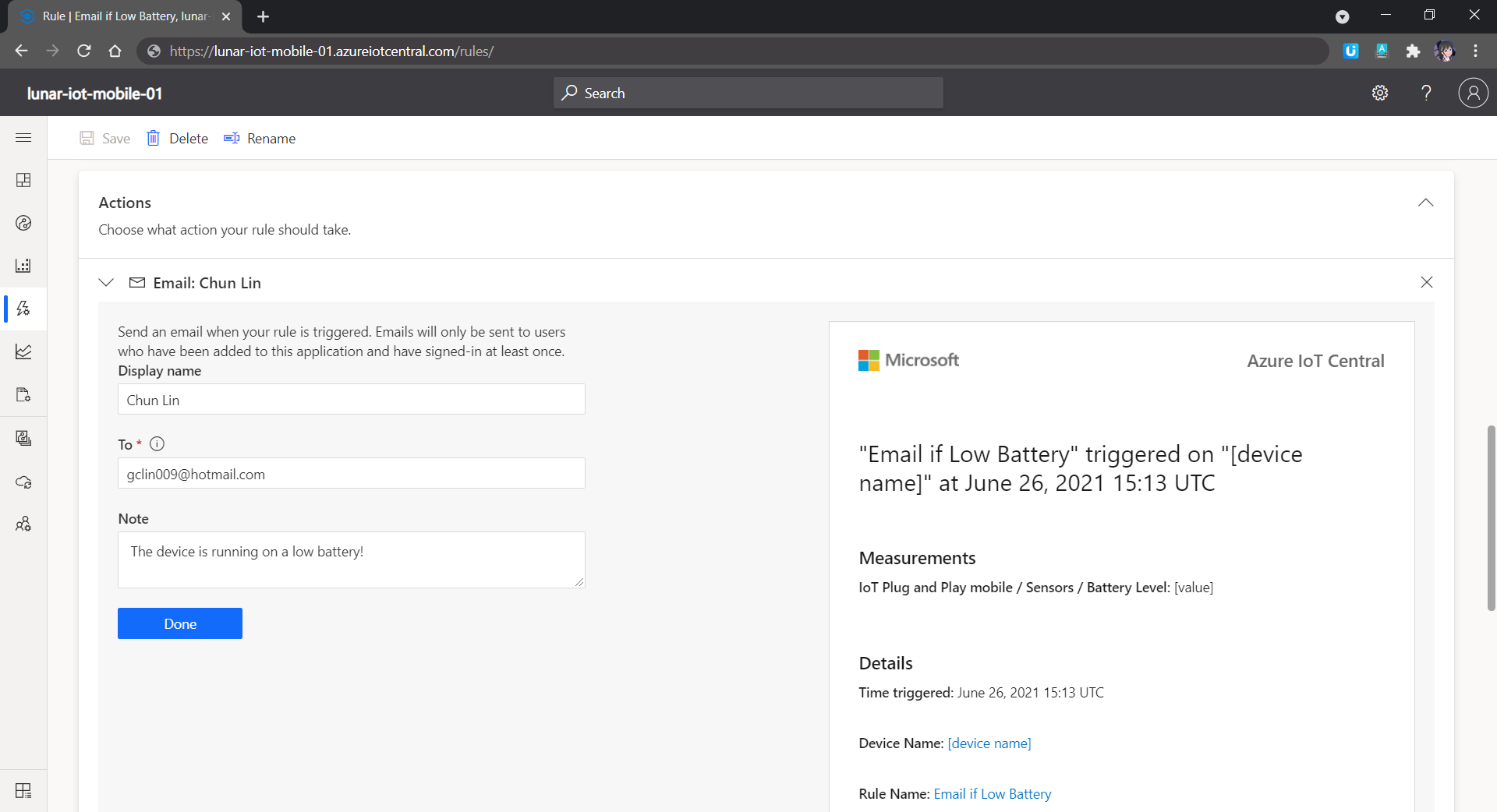
We are also able to specify rules in the Azure IoT Central so that there will be an action triggered when the defined conditions are met. We can also integrate the rule with Power Automate and Azure Logic Apps to perform relevant automated workflows.
We can also have Azure IoT Central to send us an email when the device is running on low battery, for example.
Scheduled Jobs
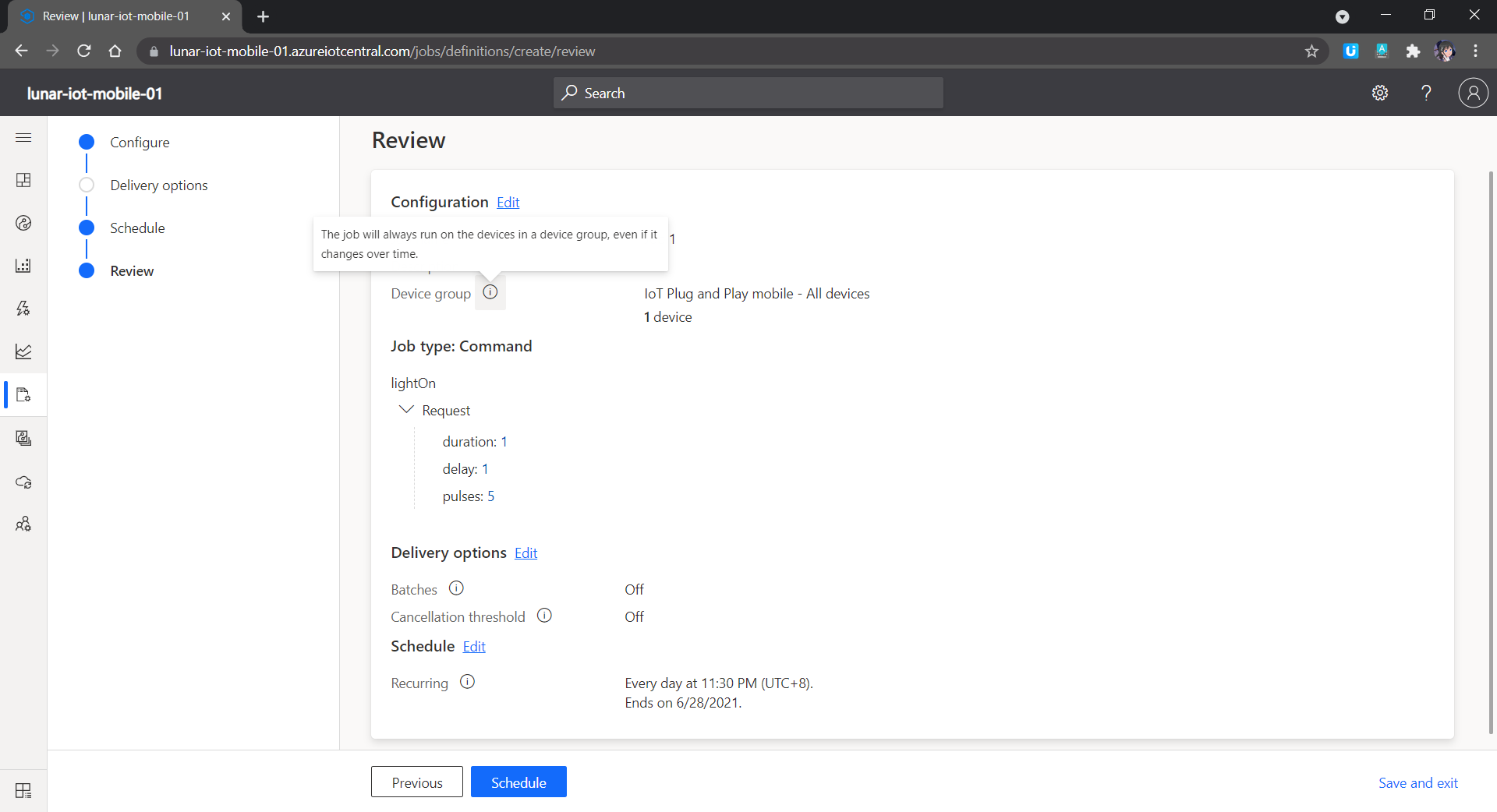
Another cool feature in Azure IoT Central is that we can send the commands back to the devices. In addition, we can send the commands in a scheduled manner. For example, in the following screenshot, the “lightOn” will be sent to all the devices in the Device Group and thus the connected phones in the Device Group will switch on their flashlight at 11.30pm in the midnight.
Don’t be scared if there is flashlight suddenly coming from chassis in midnight.
Image Upload
In the IoT Plug and Play app, we can also try out the image upload feature which allows us to submit images to the cloud from the IoT devices. As shown in the screenshot below, each IoT Central app can only link with one Azure Storage container. Hence, in the container, there will be folder for each of the registered IoT devices so that files uploaded will be categorised into their own folder accordingly.
We need to link Azure IoT Central to a container in the Azure Storage.
So with the phones setup as IoT devices, we can now install them on the container chassis to continuously send back the location data to the Azure IoT Central. The business owner can thus easily figure out where their container chassis is located at by looking at the dashboard.
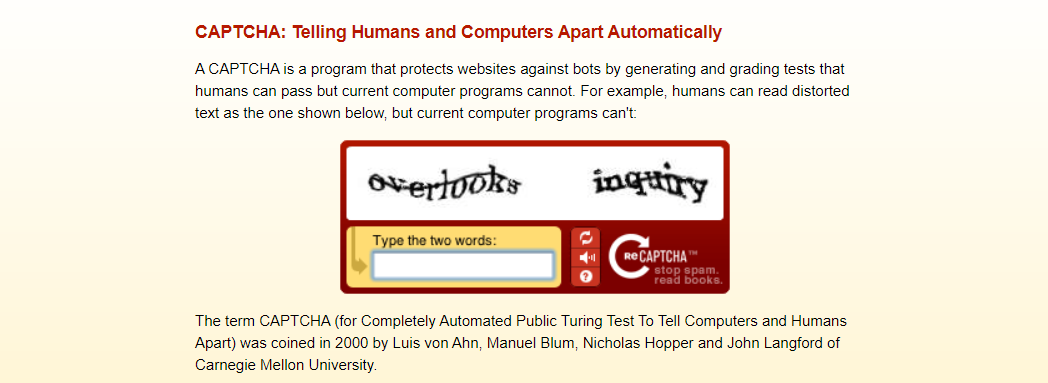
The words shown in reCAPTCHA come directly from old books that are being digitized. Hence, it does not only stop spam, but also help digitise books at the same time. (Source: reCAPTCHA)
A team led by Prof Gao Haichang from Xidian University realised that, with the development of automated computer vision techniques such as OCR, traditional text-based CAPTHCAs are not considered safe anymore for authentication. During the IEEE conference in 2010, they thus proposed a new way, i.e. using an image based CAPTCHA which involves in solving a jigsaw puzzle. Their experiments and security analysis further proved that human can complete the jigsaw puzzle CAPTCHA verification quickly and accurately which bots rarely can. Hence, jigsaw puzzle CAPTCHA can be a substitution to the text-based CAPTCHA.
Xidian University, one of the 211 Project universities and a high level scientific research innovation in China. (Image Source: Shulezetu)
In 2019, on CSDN (Chinese Software Developer Network), a developer 不写BUG的瑾大大 shared his implementation of jigsaw puzzle captcha in Java. It’s a very detailed blog post but there is still room for improvement in, for example, documenting the code and naming the variables. Hence, I’d like to take this opportunity to implement this jigsaw puzzle CAPTCHA in .NET 5 with C# and Blazor. I also host the demo web app on Azure Static Web App so that you all can access and play with the CAPTCHA: https://jpc.chunlinprojects.com/.
Today, jigsaw puzzle CAPTCHA is used in many places. (Image Credit: Hirabiki at HoYoLAB)
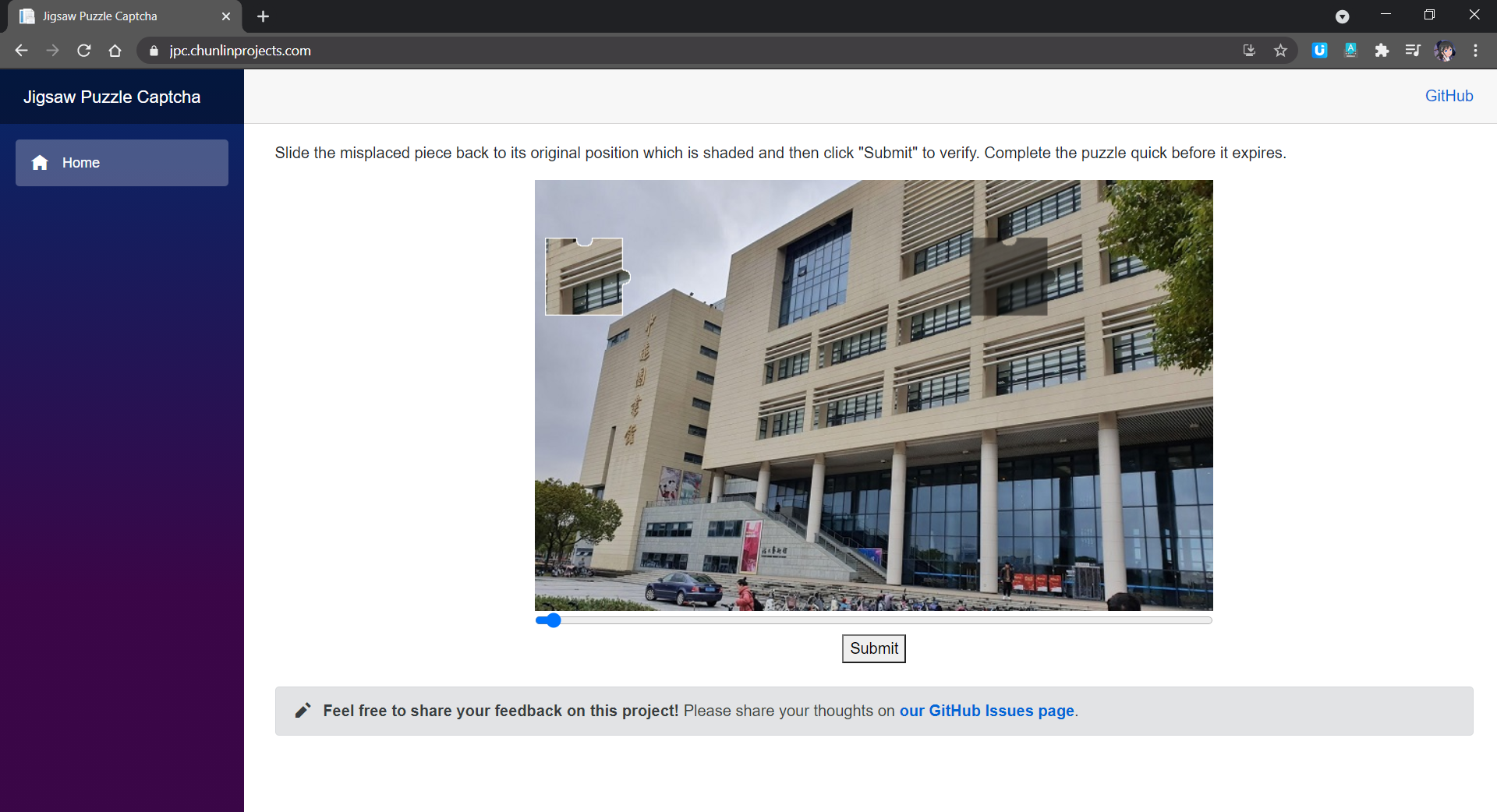
Jigsaw Puzzle CAPTCHA
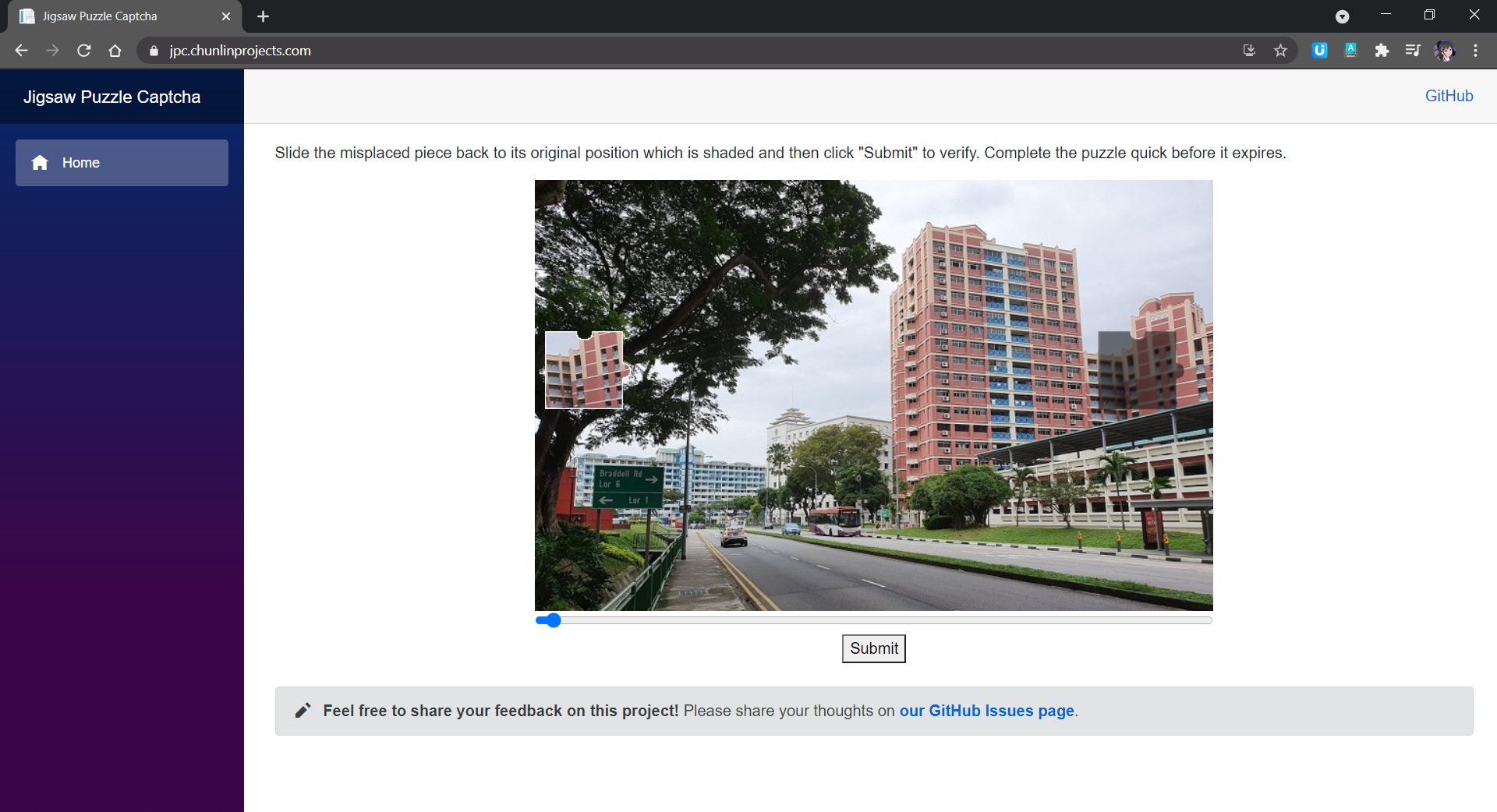
In a jigsaw puzzle CAPTCHA, there is usually a jigsaw puzzle with at least one misplaced piece where users need to move to the correct place to complete the puzzle. In my demo, I have only one misplaced piece that needs to be moved.
Jigsaw puzzle CAPTCHA implementation on Blazor. (Try it here)
As shown in the screenshot above, there are two necessary images in the CAPTCHA. One of them is a misplaced piece of the puzzle. Another image is the original image with a shaded area indicating where the misplaced piece should be dragged to. What users need to do is just dragging the slider to move the misplaced piece to the shaded area to complete the jigsaw puzzle within a time limit.
In addition, here the CAPTCHA only needs user to drag the missing piece horizontally. This is not only the popular implementation of the jigsaw puzzle CAPTCHA, but also not too challenging for users to pass the CAPTCHA.
Now, let’s see how we can implement this in C# and later deploy the codes to Azure.
Retrieve the Original Image
The first thing we need to do is getting an image for the puzzle. We can have a collection of images that make good jigsaw puzzle stored in our Azure Blob Storage. After that, each time before generating the jigsaw puzzle, we simply need to fetch all the images from the Blob Storage with the following codes and randomly pick one as the jigsaw puzzle image.
public async Task<List<string>> GetAllImageUrlsAsync()
{
var output = new List<string>();
var container = new BlobContainerClient(_storageConnectionString, _containerName);
var blobItems = container.GetBlobsAsync();
await foreach (var blob in blobItems)
{
var blobClient = container.GetBlobClient(blob.Name);
output.Add(blobClient.Uri.ToString());
}
return output;
}
Define the Missing Piece Template
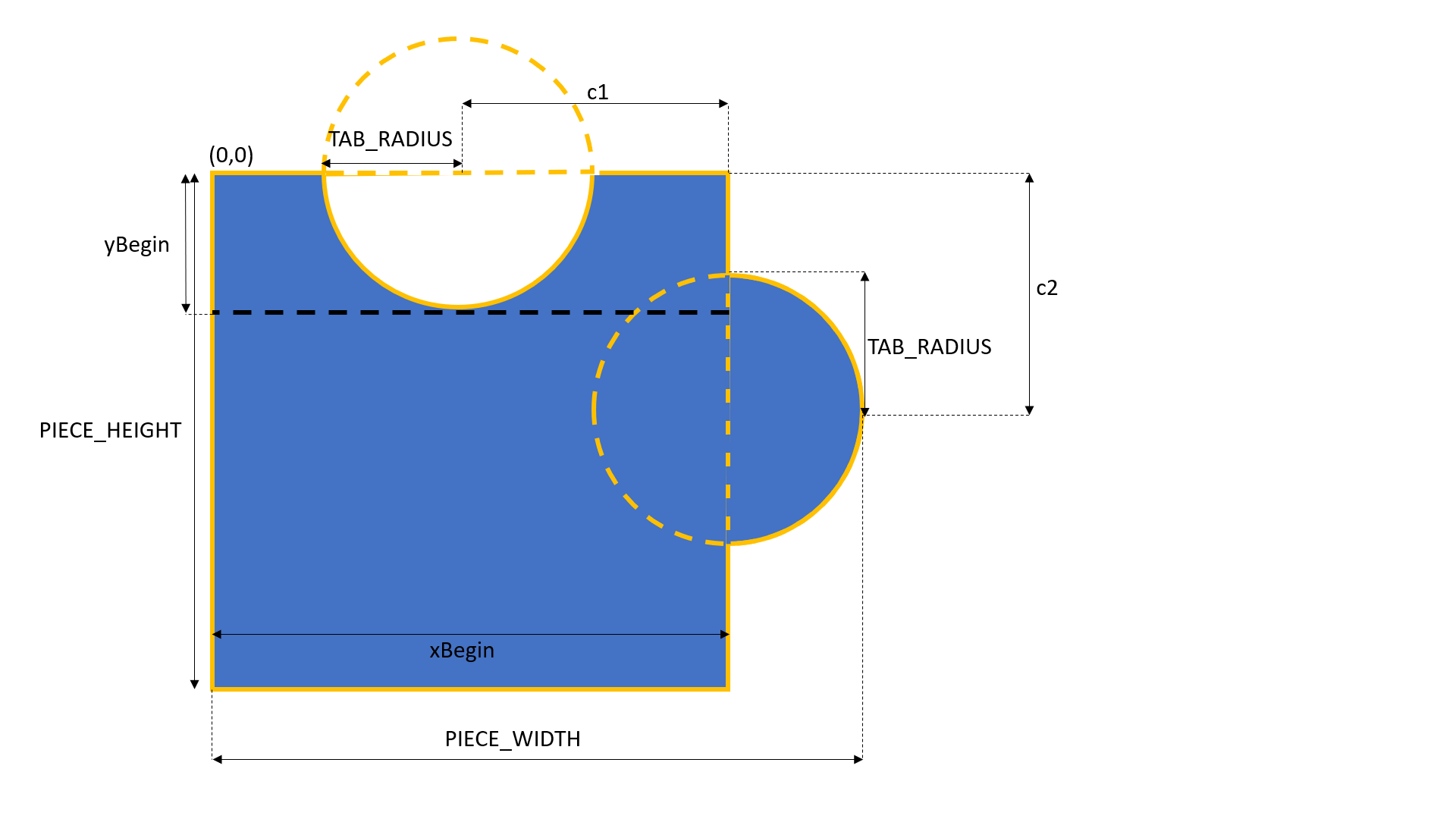
To increase the difficulty of the puzzle, we can have jigsaw pieces with different patterns, such as having tabs appearing on different sides of the pieces. In this demo, I will stick to just one pattern of missing piece, which has tabs on the top and right sides, as shown below.
The missing piece template.
The tabs are basically two circles with the same radius. Their centers are positioned at the middle point of the rectangle side. Hence, we can now build a 2D matrix for the pixels indicating the missing piece template with 1 means inside of the the piece and 0 means outside of the piece.
In addition, we know the general equation of a circle of radius r at origin (h,k) is as follows.
Hence, if there is a point (i,j) inside the circle above, then the following must be true.
If the point (i,j) is outside of the circle, then the following must be true.
With these information, we can build our missing piece 2D matrix as follows.
After that, we can determine the border of the missing piece easily too from just the template data above. We then can draw the border of the missing piece for better user experience when we display it on screen.
Next, we need to tell the user where the missing piece should be dragged to. We will use the template data above and apply it to the original image we get from the Azure Blob Storage.
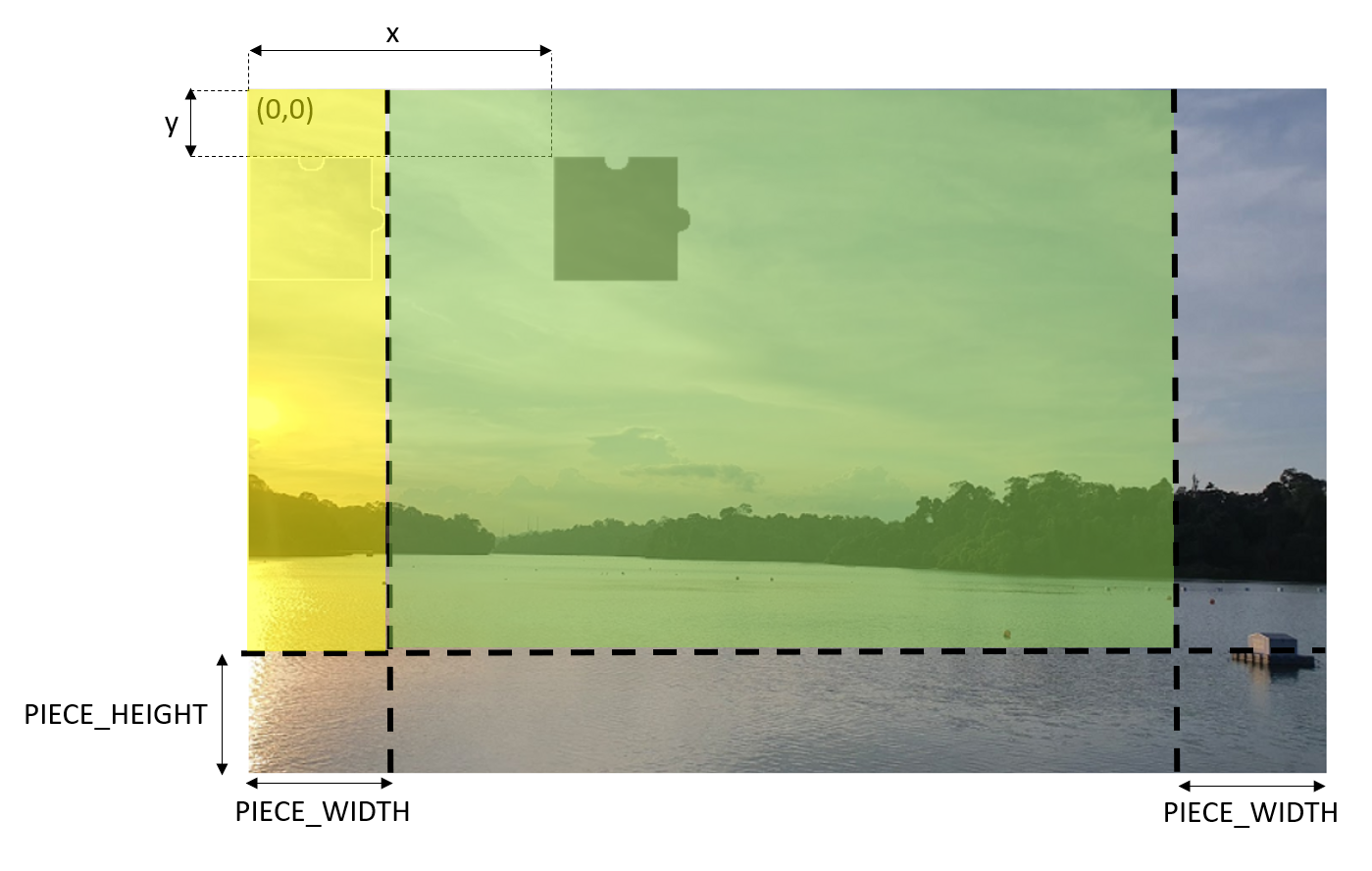
Due to the shape of the missing piece, the proper area to have the shaded area needs to be in the region highlighted in green colour below. Otherwise, the shaded area will not be shown completely and thus give users a bad user experience. The yellow area is okay too but we don’t allow the shaded area to be there to avoid cases where the missing piece covers the shaded area when the images first load and thus confuses the users.
Random random = new Random();
int x = random.Next(originalImage.Width - 2 * PIECE_WIDTH) + PIECE_WIDTH;
int y = random.Next(originalImage.Height - PIECE_HEIGHT);
Green area is where the top left of the shaded area should be positioned at.
Let’s assume the shaded area is at the point (x,y) of the original image, then given the original image in a Bitmap variable called originalImage, we can then have the following code to traverse the area and process the pixels in that area.
...
int[,] missingPiecePattern = GetMissingPieceData();
for (int i = 0; i < PIECE_WIDTH; i++)
{
for (int j = 0; j < PIECE_HEIGHT; j++)
{
int templatePattern = missingPiecePattern[i, j];
int originalArgb = originalImage.GetPixel(x + i, y + j).ToArgb();
if (templatePattern == 1)
{
...
originalImage.SetPixel(x + i, y + j, FilterPixel(originalImage, x + i, y + j));
}
else
{
missingPiece.SetPixel(i, j, Color.Transparent);
}
}
}
...
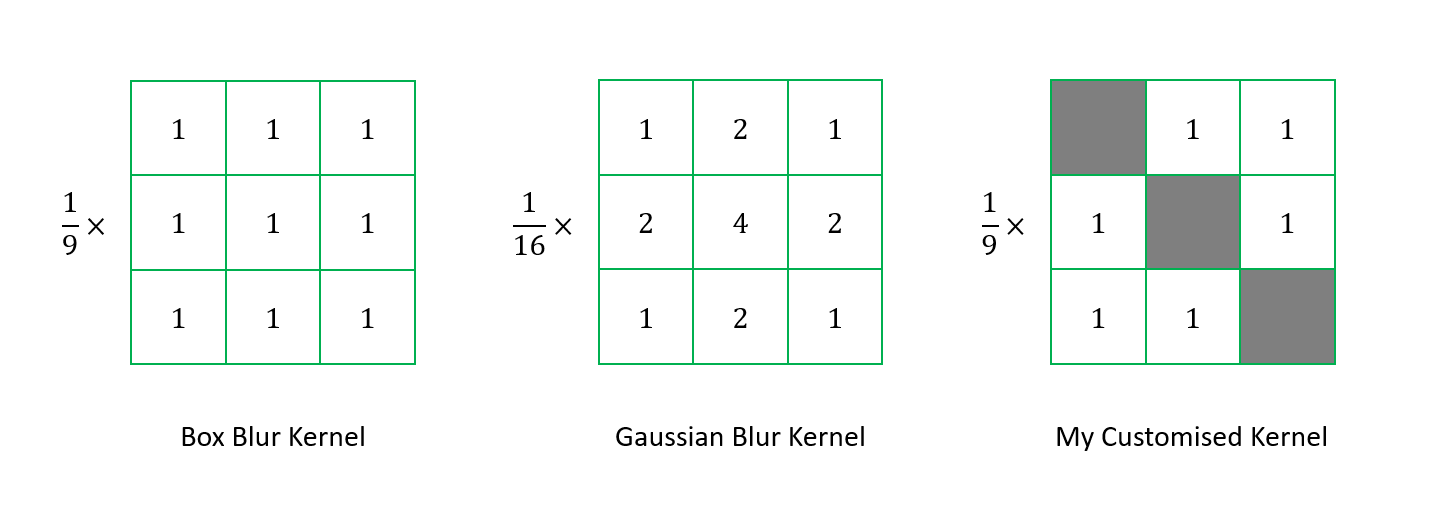
Kernels used in different types of image processing.
For the kernel, I don’t really follow the official Box Blur kernel or Gaussian Blur kernel. Instead, I dim the generated colour by forcing three pixel to be always black (when i = j). This is to make sure the shaded area is not only blurred but darkened.
private Color FilterPixel(Bitmap img, int x, int y)
{
const int KERNEL_SIZE = 3;
int[,] kernel = new int[KERNEL_SIZE, KERNEL_SIZE];
...
int r = 0;
int g = 0;
int b = 0;
int count = KERNEL_SIZE * KERNEL_SIZE;
for (int i = 0; i < kernel.GetLength(0); i++)
{
for (int j = 0; j < kernel.GetLength(1); j++)
{
Color c = (i == j) ? Color.Black : Color.FromArgb(kernel[i, j]);
r += c.R;
g += c.G;
b += c.B;
}
}
return Color.FromArgb(r / count, g / count, b / count);
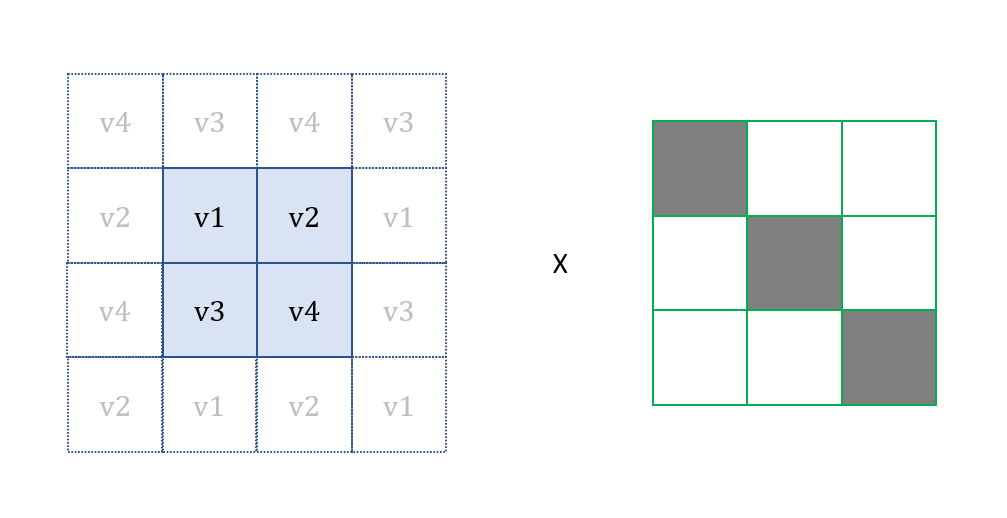
What will happen when we are processing pixel without all 8 neighbouring pixels? To handle this, we will take the value of the pixel at the opposite position which is describe in the following diagram.
Applying kernel on edge pixels.
Since we have two images ready, i.e. an image for the missing piece and another image which shows where the missing piece needs to be, we can convert them into base 64 string and send the string values to the web page.
Now, the next step will be displaying these two images on the Blazor web app.
The purpose of API in this project is to retrieve the jigsaw puzzle images and verify user submissions. We don’t need a full server for our API because Azure Static Web Apps hosts our API in Azure Functions. So we need to implement our API as Azure Functions here.
We will have two API methods here. The first one is to retrieve the jigsaw puzzle images, as shown below.
[FunctionName("JigsawPuzzleGet")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "jigsaw-puzzle")] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
var availablePuzzleImageUrls = await _puzzleImageService.GetAllImageUrlsAsync();
var random = new Random();
string selectedPuzzleImageUrl = availablePuzzleImageUrls[random.Next(availablePuzzleImageUrls.Count)];
var jigsawPuzzle = _puzzleService.CreateJigsawPuzzle(selectedPuzzleImageUrl);
_captchaStorageService.Save(jigsawPuzzle);
return new OkObjectResult(jigsawPuzzle);
}
The Azure Function first retrieve all the images from the Azure Blob Storage and then randomly pick one to use in the jigsaw puzzle generation.
Before it returns the puzzle images back in a jigsawPuzzle object, it also saves it into Azure Table Storage so that later when users submit their answer back, we can have another Azure Function to verify whether the users solve the puzzle correctly.
In the Azure Table Storage, we generate a GUID and then store it together with the location of the shaded area, which is randomly generated, as well as an expiry date and time so that users must solve the puzzle within a limited time.
...
var tableClient = new TableClient(...);
...
var entity = new JigsawPuzzleEntity
{
PartitionKey = ...,
RowKey = id,
Id = id,
X = x,
Y = y,
CreatedAt = createdAt,
ExpiredAt = expiredAt
};
tableClient.AddEntity(entity);
...
Here, GUID is used as the RowKey of the Table Storage. Hence, later when user submits his/her answer, the GUID will be sent back to the Azure Function to help locate back the corresponding record in the Table Storage.
[FunctionName("JigsawPuzzlePost")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "jigsaw-puzzle")] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
var body = await new StreamReader(req.Body).ReadToEndAsync();
var puzzleSubmission = JsonSerializer.Deserialize<PuzzleSubmissionViewModel>(body, new JsonSerializerOptions { PropertyNamingPolicy = JsonNamingPolicy.CamelCase });
var correspondingRecord = await _captchaStorageService.LoadAsync(puzzleSubmission.Id);
...
bool isPuzzleSolved = _puzzleService.IsPuzzleSolved(...);
var response = new Response
{
IsSuccessful = isPuzzleSolved,
Message = isPuzzleSolved ? "The puzzle is solved" : "Sorry, time runs out or you didn't solve the puzzle"
};
return new OkObjectResult(response);
}
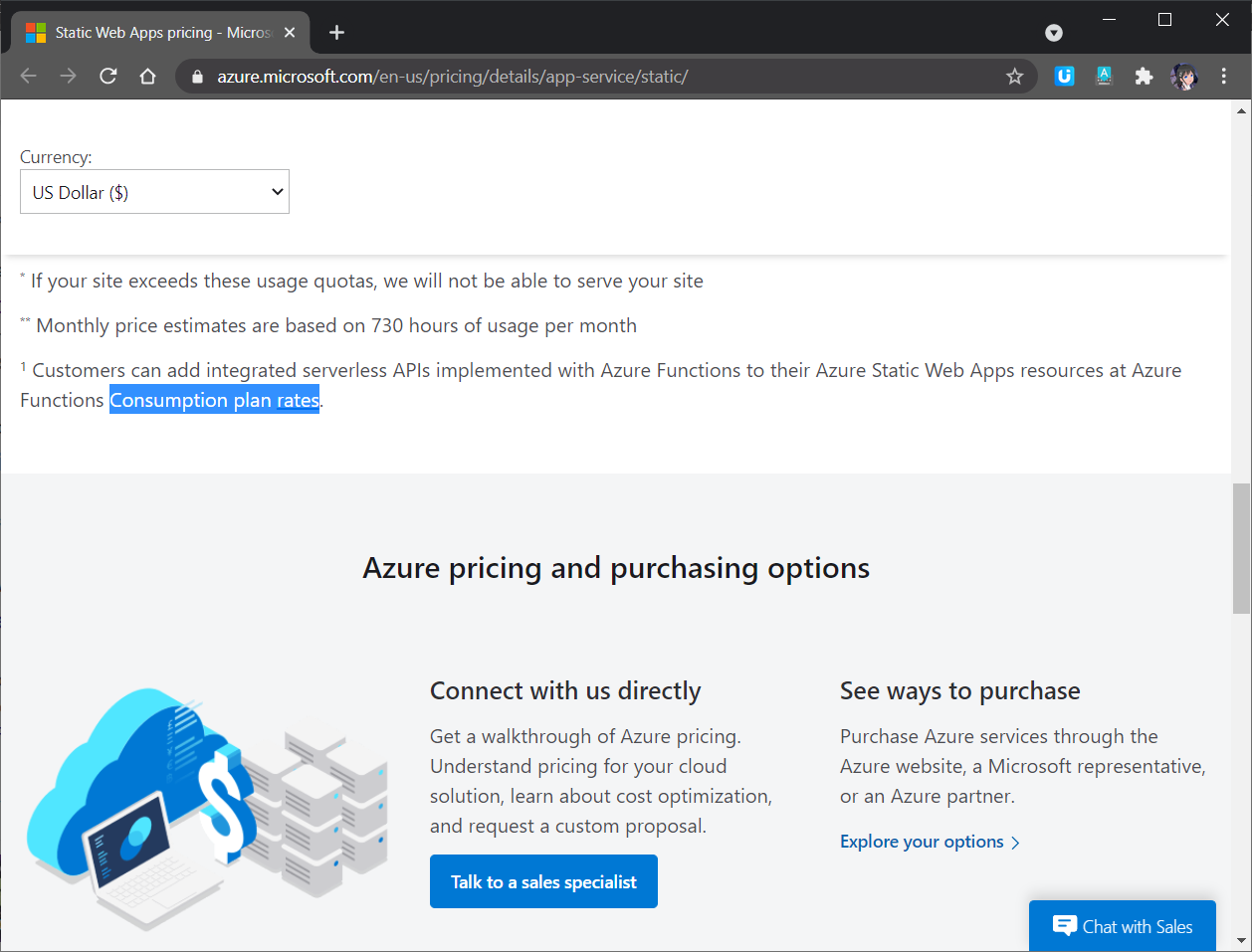
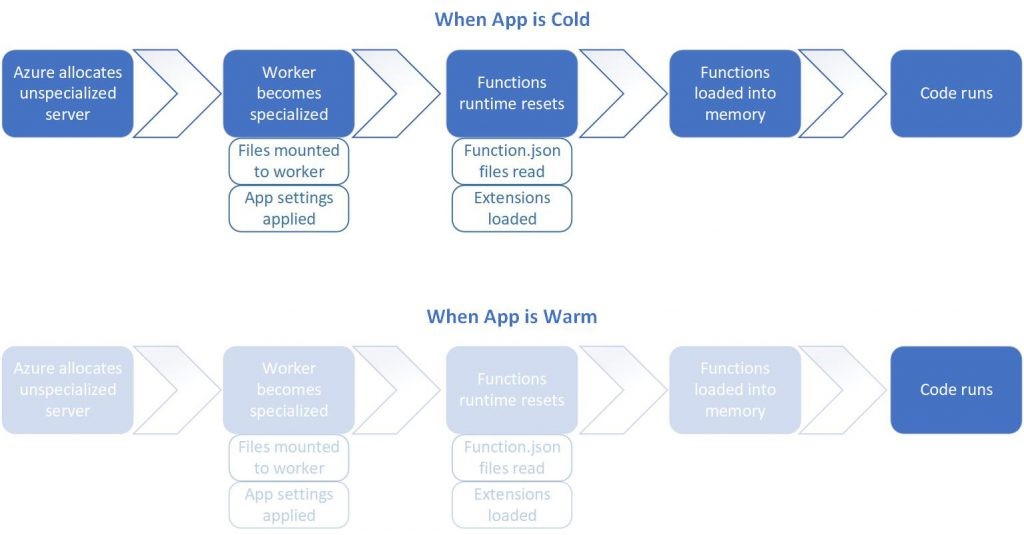
Since our API is hosted as Azure Function in Consumption Plan, as shown in the screenshot below, we need to note that our code in the Function will be in the serverless mode, i.e. it effectively scales out to meet whatever load it is seeing and scales down when code isn’t running.
The Azure Function managed by the Static Web App will be in Consumption Plan.
Latency will be there when Function is cold. (Image Source: Microsoft Azure Blog)
In this project, my friend feedbacked to me that he had encountered at least 15 seconds of latency to have the jigsaw puzzle loaded.
Blazor Frontend
Now we can move on to the frontend.
To show the jigsaw puzzle images when the page is loaded, we have the following code.
protected override async Task OnInitializedAsync()
{
var jigsawPuzzle = await http.GetFromJsonAsync("api/jigsaw-puzzle");
id = jigsawPuzzle.Id;
backgroundImage = "data:image/png;base64, " + jigsawPuzzle.BackgroundImage;
missingPieceImage = jigsawPuzzle.MissingPieceImage;
y = jigsawPuzzle.Y;
}
Take note that we don’t only get the two images but also the GUID of the jigsaw puzzle record in the Azure Table Storage so that later we can send back this information to the Azure Function for submission verification.
Here, we only return the y-axis value of the shaded area location because users are only allowed to drag the missing puzzle horizontally as discussed earlier. If you would like to increase the difficulty of the CAPTCHA by allowing users to drag the missing piece vertically as well, you can choose not to return the y-axis value.
We then have the following HTML to display the two images.
The Submit method is as follows which will feedback to users whether they solve the jigsaw puzzle correctly or not. Here I use a toast library for Blazor done by Chris Sainty, a Microsoft MVP.
private async Task Submit()
{
var submission = new PuzzleSubmissionViewModel
{
Id = id,
X = x
};
var response = await http.PostAsJsonAsync("api/jigsaw-puzzle", submission);
var responseMessage = await response.Content.ReadFromJsonAsync<Response>();
if (responseMessage.IsSuccessful)
{
toastService.ShowSuccess(responseMessage.Message);
}
else
{
toastService.ShowError(responseMessage.Message);
}
}
Now we can test how our app works!
Testing Locally
Before we can test locally, we need to provide the secrets and relevant settings to access Azure Blob Storage and Table Storage.
In addition, please remember to exclude local.settings.json from the source control.
In the Client project, since we are going to run our Api at port 7071, we shall let the Client know too. To do so, we first need to specify the base address for local in the Program.cs of the Client project.
builder.Services.AddScoped(sp => new HttpClient { BaseAddress = new Uri(builder.Configuration["API_Prefix"] ?? builder.HostEnvironment.BaseAddress) });
Then we can specify the value for API_Prefix in the appsettings.Development.json in the wwwroot folder.
{
"API_Prefix": "http://localhost:7071"
}
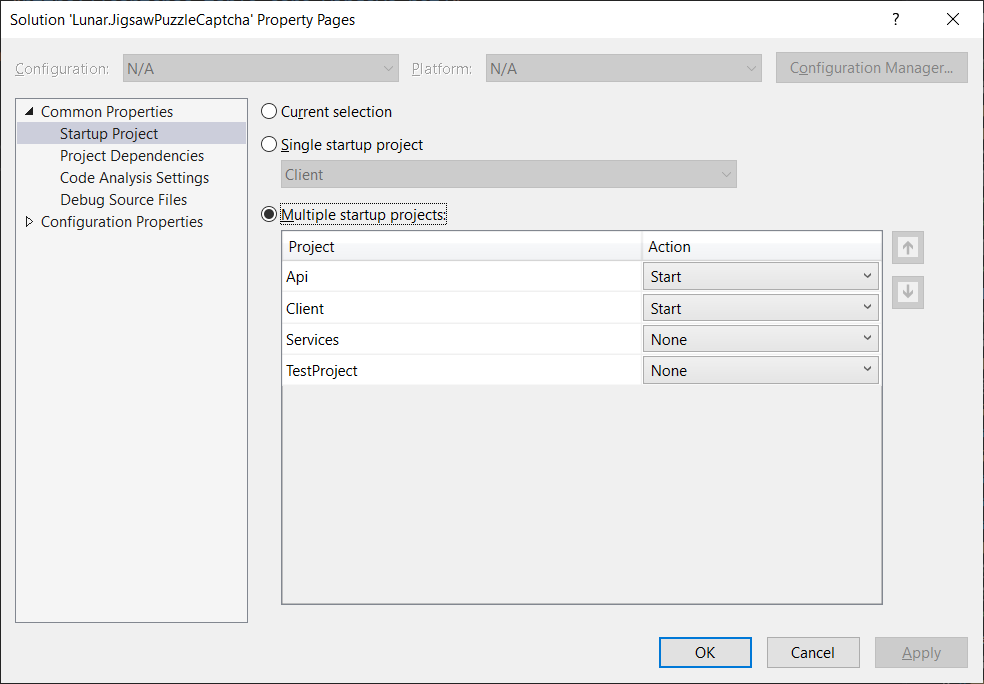
Finally, please also set both Api and Client projects as the Startup Project in the Visual Studio.
Setting multiple startup projects in Visual Studio.
Deploy to Azure Static Web App
After we have created an Azure Static Web Apps resource and bound it with a GitHub Actions which monitors our GitHub repository, the workflow will automatically build and deploy our app and its API to Azure every time we commit or create pull requests into the watched branch. The steps have been described in my previous blog post about Blazor on Azure Static Web App, so I won’t repeat it here.
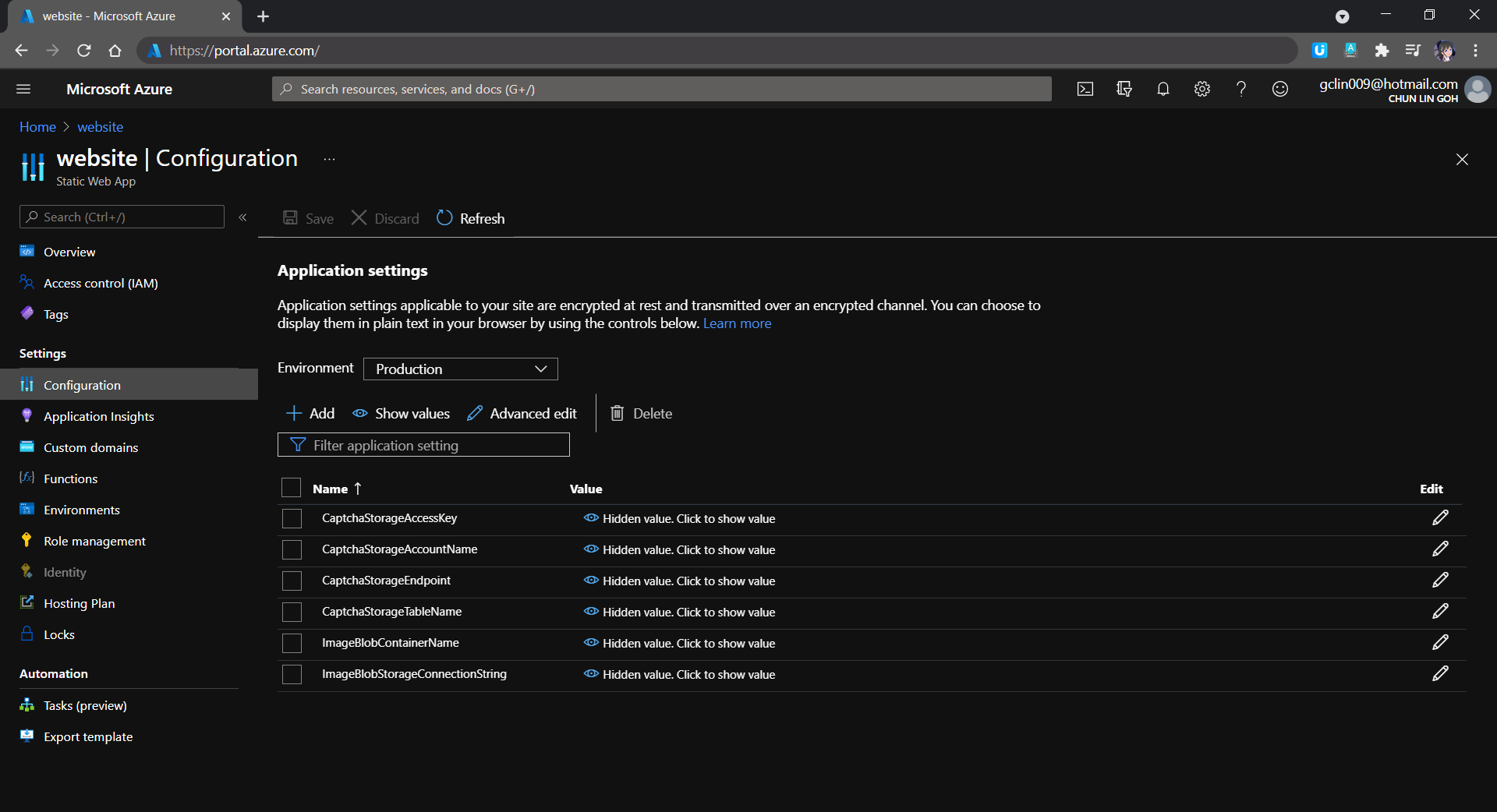
Since our API needs to have the information of secrets and connection settings to the Azure Storage, we need to specify them under Application Settings of the Azure Static Web App as well. The values will be accessible by API methods in the Azure Functions.
Managing the secrets in Application Settings.
Yup, that’s all for implementing a jigsaw puzzle CAPTCHA in .NET. Feel free to try it out on my Azure Static Web App and let me know your thoughts about it. Thank you!
Jigsaw puzzle CAPTCHA implementation on Blazor. (Try it here)
In this article, I will share how the website for Singapore .NET Developers Community and Azure Community is re-built as a Blazor web app and deployed to Azure.
The community website is very simple. It is merely a single-page website with some descriptions and photos about the community. Then it also has a section showing list of meetup videos from the community YouTube channels.
We will build the website as Blazor WebAssembly App.
Secondly, if we hope to have a similar UI template across all the web pages in the website, then we can define the HTML template under, for example, MainLayout.razor, as shown below. This template means that the header and footer sections can be shared across different web pages.
Finally, we simply need to define the @Body of each web page in their own Razor file, for example the Index.razor for the homepage.
In the Index.razor, we will fetch the data from a JSON file hosted on Azure Storage. The JSON file is periodically updated by Azure Function to fetch the latest video list from the YouTube channel of the community. Instead of using JavaScript, here we can simply write a C# code to do that directly on the Razor file of the homepage.
@code {
private List<VideoFeed> videoFeeds = new List<VideoFeed>();
protected override async Task OnInitializedAsync()
{
var allVideoFeeds = await Http.GetFromJsonAsync<VideoFeed[]>("...");
videoFeeds = allVideoFeeds.ToList();
}
public class VideoFeed
{
public string VideoId { get; set; }
public Channel Channel { get; set; }
public string Title { get; set; }
public string Description { get; set; }
public DateTimeOffset PublishedAt { get; set; }
}
public class Channel
{
public string Name { get; set; }
}
}
Publish to Azure Static Web App from GitHub
We will have our codes ready in a GitHub repo with the following structure.
.github/workflows
DotNetCommunity.Singapore
Client
(Blazor client project here)
Next, we can proceed to create a new Azure Static Web App where we will host our website at. In the first step, we can easily link it up with our GitHub account.
We need to specify the deployment details for the Azure Static Web App.
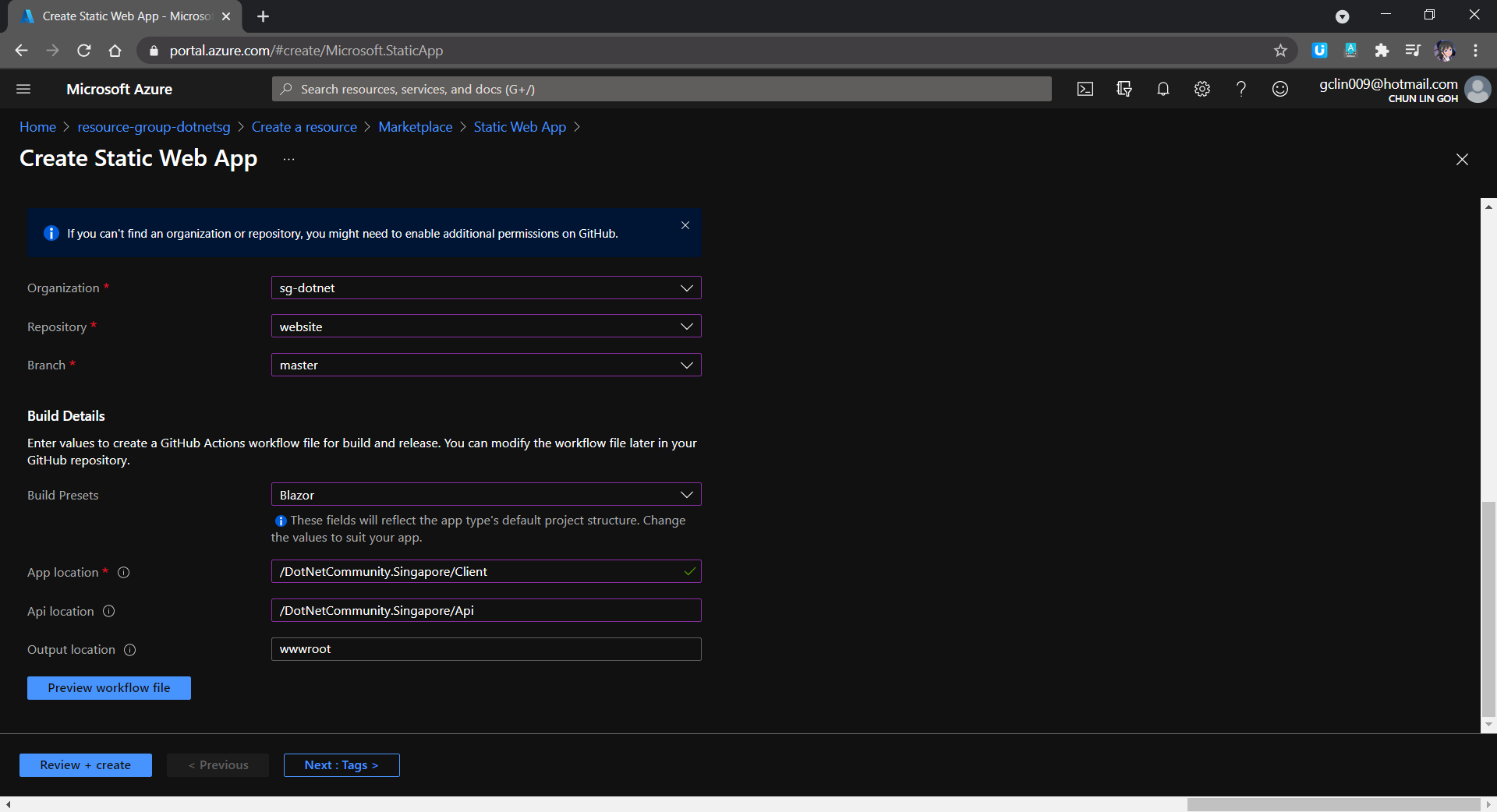
After that, we will need to provide the Build details so that a GitHub workflow will be automatically generated. That is a GitHub Actions workflow that builds and publishes our Blazor web app. Hence, we must specify the corresponding folder paths within our GitHub repo, as shown in the screenshot below.
In the Build Details, we must setup the folder path correctly.
The “App location” is to point to the location of the source code for our Blazor web app. For the “Api location”, although we are not using it in our Blazor project now, we can still set it as follows so that in the future when we can easily setup the Api folder.
With this setup ready, whenever we update the codes in our GitHub repo via commits or pull requests, our Blazor web app will be built and deployed.
Our Blazor web app is being built in GitHub Actions.
For root domain, which is “dotnet.sg” in our case, by right we can do it in Azure Static Web App by using TXT record validation and an ALIAS record.
Take note that we can only create an ALIAS record if our domain provider supports it.
However, since there is currently no support of ALIAS or ANAME records in the domain provider that I am using, I have no choice but to have another Azure Function for binding “dotnet.sg”. This is because currently there is no IP address given in Azure Static Web App but there are IP address and Custom Domain Verification ID available in Azure Function. With these two information, we can easily map an A Record to our root domain, i.e. “dotnet.sg”.
Please take note that A Records are not supported for Consumption-based Function Apps. We must pay for the “App Service Plan” instead.
IP address and Custom Domain Verification ID on Azure Function. The root domain here is also SSL enabled.
With all these ready, we can finally get our community website up and running at dotnet.sg.
Welcome to the Singapore .NET/Azure Developer Community at dotnet.sg.
Export SSL Certificate For Azure Function
This step is optional. I need to go through this step because I have a Azure App Service managed certificate in one subscription but Azure Function in another subscription. Hence, I need to export the SSL certificate out and then import it back to another subscription.
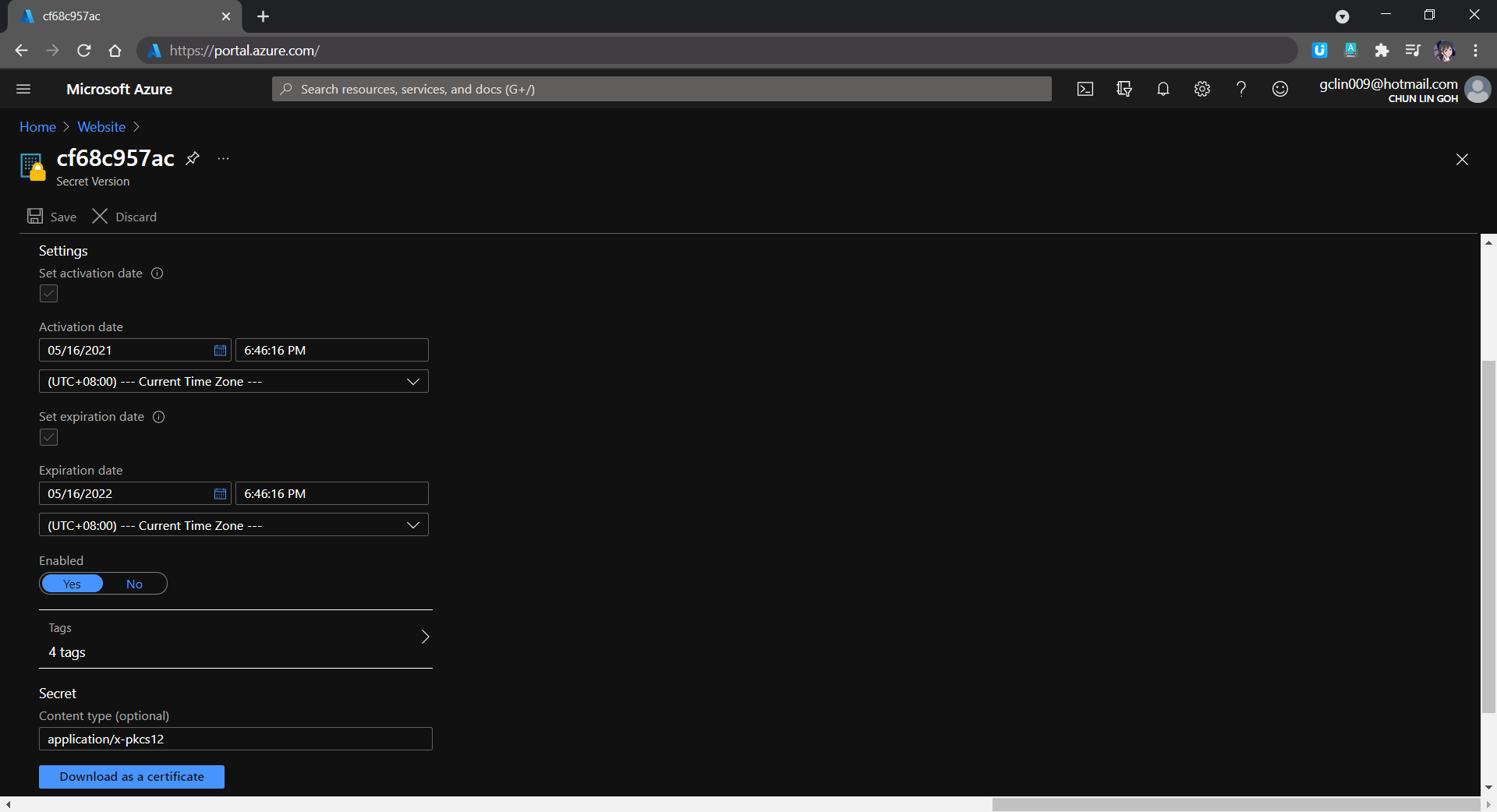
We can export certificate from the Key Vault Secret.
In the Key Vault Secret screen, we then need to choose the correct secret version and download the certificate, as shown in the following screenshot.
We will be prompted for a password after executing the first command. We simply press enter to proceed because the certificate, as mentioned above, has no password.
OpenSSL command prompt.
With this step done, I finally can import the cert to the Azure Function in another subscription.
Yup, that’s all for hosting our community website as a Blazor web app on Azure Static Web App!