
This month marks my third year in port and logistics industry.
In April, I attended a talk organised by NUS Business School on the future-ready supply chain. The talk is delivered by Dr Robert Yap, the YCH Group Executive Chairman. During the talk, Dr Yap mentioned that they innovated to survive because innovation was always at the heart of their development and growth. To him and his team, technology is not only an enabler for the growth of their business, but also a competitive advantage of the YCH Group.
In YCH Group, they have a vision of integrating the data flows in the supply chain with their unique analytics capabilities so that they can provide a total end-to-end supply chain enablement and transformation. Hence, today I’d like to share about how, with Microsoft Azure, we can build a data pipeline and modern data warehouse which helps to enable logistics companies to gear towards a future-ready supply chain.

Two months ago, I also had the opportunity to join an online workshop to learn from Michelle Xie, Microsoft Azure Technical Trainer, about Azure Data Fundamentals. The workshop consists of four modules. In the workshop, we learnt core data concepts, relational and non-relational data offerings in Azure, modern data warehouses, and Power BI. Hence, I will share with you what I have learned in the workshop in this article as well.
About Data
Data is a collection of facts, figures, descriptions, and objects. Hence, data can be texts written on papers, or it can be in digital form and stored inside the electronic devices, or it could be facts that are in our mind. Data can be classified as follows.
- Structured Data: Data stored in predefined schemas. Often structured data is managed using Structured Query Language (SQL). Data needs to be normalised so that no data duplication exists.
- Semi-structured Data: A form of structured data that has a different, non-tabular schema and thus it does not obey the tabular structure, but nonetheless contains tags to separate semantic elements and enforce hierarchies of records and fields within the data. Data storage formats include XML, JSON, Apache ORC, and Apache Parquet.
- Unstructured Data: Data that does not naturally contains field and is stored in its natural format until it’s extracted for analysis, for example image, blob, audio, and video.

ETL Data Pipeline
To build an data analytical system, we normally will have the following steps in a data pipeline to perform ETL procedure. ETL stands for Extract, Transform and Load. ETL loads data first into the staging storage server and then into the target storage system, as shown below.

- Data Ingestion: Data is moved from one or many data sources to a destination where it can be stored and further analysed;
- Data Processing: Sometimes the raw data may not in the format suitable for querying. Hence, we need to transform and clean up the data;
- Data Storage: Once the raw data has been processed, all the cleaned and transformed data will be stored to different storage systems which serve different purposes;
- Data Exploration: A way of analysing performance through graphs and charts with business intelligence tools. This is helpful in making informed business decisions.

In the world of big data, raw data often comes from different endpoints and the data is stored in different storage systems. Hence, there is a need of a service which can orchestrate the processes to refine these enormous stores of raw data into actionable business insights. This is where the Azure Data Factory, a cloud ETL service for scale-out serverless data integration and data transformation, comes into picture.
There are two ways of capturing the data in the Data Ingestion stage.
The first method is called the Batch Processing where a set of data is first collected over time and then fed into an analytics system to process them in group. For example, the daily sales data collected is scheduled to be processed every midnight. This is not just because midnight is the end of the day but also because the business normally ends at night and thus midnight is also the time when the servers are most likely to have more computing capacity.
Another method will be Streaming model where data is fed into analytics tools as it arrives and the data is processed in real time. This is suitable for use cases like collecting GPS data sent from the trucks because every piece of new data is generated in continuous manner and needs to be sent in real time.
Modern Data Warehouse
A modern data warehouse allows us to gather all our data at any scale easily, and to get insights through analytics, dashboard, and reports. The following image shows the data warehouse components on Azure.

For a big data pipeline, the data is ingested into Azure through Azure Data Factory in batches, or streamed near real-time using Apache Kafka, Event Hub, or IoT Hub. This data will then land in Azure Data Lake Storage long term persisted storage.
The Azure Data Lake Storage is an enterprise-wide hyper-scale repository for large volume of raw data. It is a suitable staging storage for our ingested data before the data is converted into a format suitable for data analysis. Thus, it can store any data in its native format, without requiring any prior transformations. Data Lake Storage can be accessed from Hadoop with the WebHDFS-compatible REST APIs.
As part of our data analytics workflow, we can use Azure Databricks as a platform to run SQL queries on the data lake and provide results for the dashboards in, for example, PowerBI. In addition, Azure Databricks also integrates with the MLflow machine learning platform API to support the end-to-end machine learning lifecycle from data preparation to deployment.

Let’s say a container trucking company collects data about each container delivery through an IoT device installed on the vehicle. Information such as the location and the speed of the prime mover is constantly sent from the IoT device to Azure Event Hub. We then can use Azure Databricks to correlate of the trip data, and also to enrich the correlated data with neighborhood data stored in the Databricks file system.
In addition, to process large amount of data efficiently, we can also rely on the Azure Synapse Analytics, which is basically an analytics service and a cloud data warehouse that lets us scale, compute, and store elastically and independently, with a massively parallel processing architecture.
Finally, we have Azure Analysis Services, which is an enterprise-grade analytics engine as a service. It is used to combine the data, define metrics, and secure the data in a single, trusted tabular semantic data model with enterprise-grade data models. As mentioned by Christian Wade, the Power BI Principal Program Manager in Microsoft, in March 2021, they have brought Azure Analysis Services capabilities to Power BI.

Relational Database Deployment Options on Azure and HOSTING COST
On Azure, there are two database deployment options available, i.e. IaaS and PaaS. IaaS option means that we have to host our SQL server on their virtual machines. For PaaS approach, we are able to either use Azure SQL Database, which is considered as DBaaS, or Azure SQL Managed Instance. Unless there is a need for the team to have OS-level access and control to the SQL servers, PaaS approach is normally the best choice.
Both PaaS and IaaS options include base price that covers underlying infrastructure and licensing. In IaaS, we can reduce the cost by shutting down the resources. However, in PaaS, the resources are always running unless we drop and re-create our resources when they are needed.
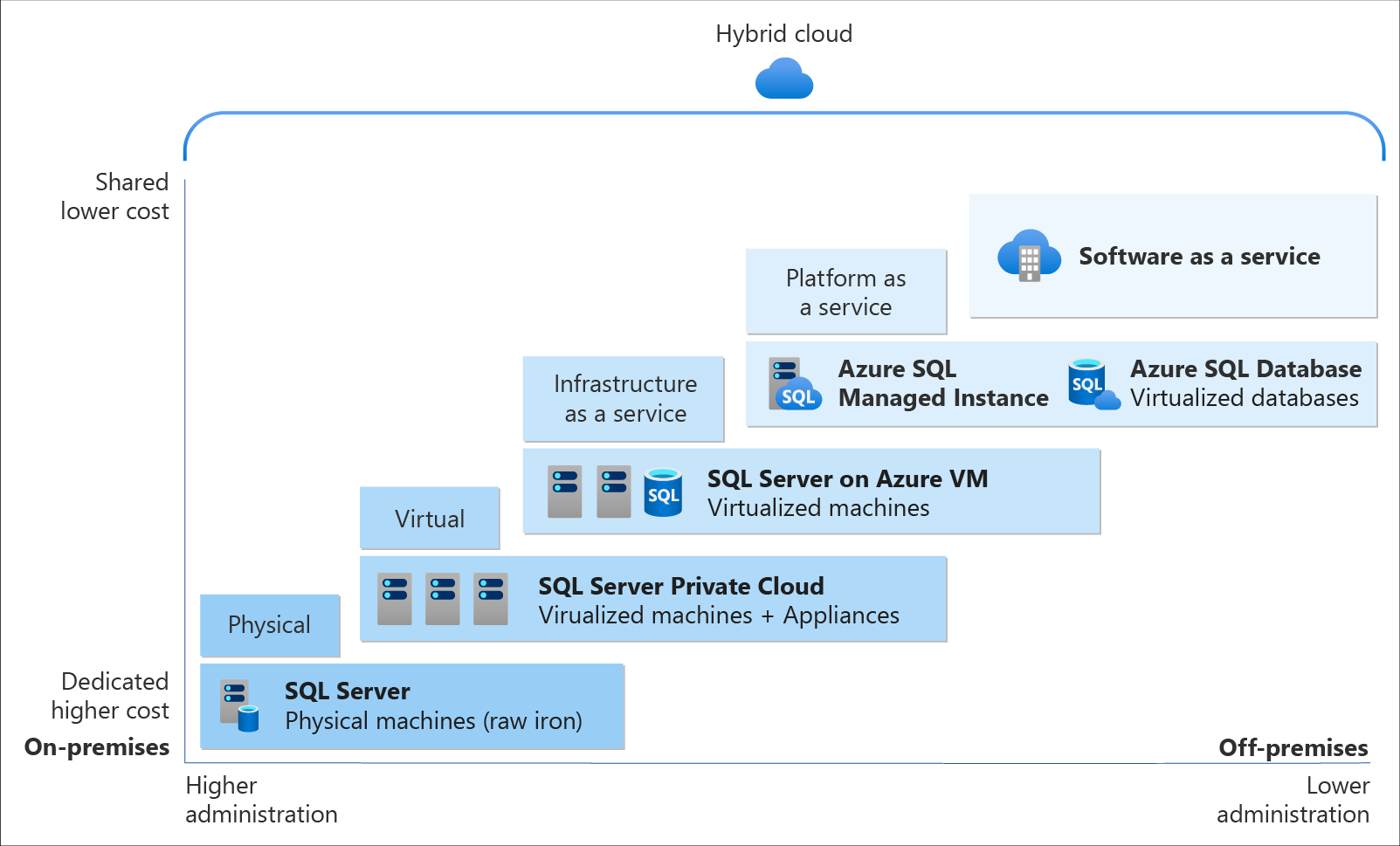
SQL Managed Instance is the latest deployment option which enables easy migration of most of the on-premises databases to Azure. It’s a fully-fledged SQL instance with nearly complete compatible with on-premise version of SQL server. Also, since SQL Managed Instance is built on the same PaaS service infrastructure, it comes with all PaaS features. Hence, if you would like to migrate from on-premise to Azure without management overhead but at the same time you require instance-scoped features, such as SQL Server Agent, you can try the SQL Managed Instance.
Andreas Wolter, one of the only 7 Microsoft Certified Solutions Masters (MCSM) for the Data Platform worldwide, once came to Singapore .NET Developers Community to talk about the SQL Database Managed Instance. If you’re new to SQL Managed Instance, check out the video below.
Spatial Data Types
Visibility plays a crucial role in the logistics industry because it relates to the ability of supply chain partners to be able to access and share operation information with other parties. Tracking the asset locations with GPS is one of the examples. However, how should we handle the geography data in our database?
Spatial data, also known as geospatial data, is data represented by numerical values in a geographic coordinate system. There are two types of spatial data, i.e. the Geometry Data Type, which supports Euclidean flat-earth data, and the Geography Data Type, which stores round-earth data, such as GPS latitude and longitude coordinates.
In Microsoft SQL Server, native spatial data types are used to represent spatial objects. In addition, it is able to index spatial data, provide cost-based optimizations, and support operations such as the intersection of two spatial objects. This functionality is also available in Azure SQL Database and Azure Managed Instances.

Let’s say now we want to find the closest containers to a prime mover as shown in the following map.

In addition, we have a table of container positions defined with the schema below.
CREATE TABLE ContainerPositions
(
Id int IDENTITY (1,1),
ContainerNumber varchar(13) UNIQUE,
Position GEOGRAPHY
);

We can then simply use spatial function as shown below like STDistance, which will return the shortest distance between the two geography locations, in our query to sort the containers having the shortest to the longest distance from the prime mover.

In addition, starting from version 2.2, Entity Framework Core also supports mapping to spatial data types using the NetTopologySuite spatial library. So, if you are using EF Core in your ASP .NET Core project, for example, you can easily get the mapping to spatial data types.

Non-Relational DatabaseS on Azure
Azure Table Storage is one of the Azure services storing non-relational structured data. It provides a key/attribute store with a schema-less design. Since it’s a NoSQL datastore, it is suitable for datasets which do not require complex joins and can be denormalised for fast access.
Each of the Azure Table Storage consists of relevant entities, similar to a database row in RDBMS. Then each entity can have up to 252 properties to store the data together with a partition key. Entities with the same partition key will be stored in the same partition and the same partition server. Thus, entities with the same partition key can be queried more quickly. This also means that batch processing, the mechanism for performing atomic updates across multiple entities, can only operate on entities stored in the same partition.
In Azure Table Storage, using more partitions increases the scalability of our application. However, at the same time, using more partitions might limit the ability of the application to perform atomic transactions and maintain strong consistency for the data. We can then make use of this design to store, for example, data from each of the IoT devices in a warehouse, into different partition in the Azure Table Storage.
For a larger scale of the system, we can also design a data solution architecture that captures real-time data via Azure IoT Hub and store them into Cosmos DB which is a fast and flexible distributed database that scales seamlessly with guaranteed latency and throughput. If there is existing data in other data sources, we can also import data from data sources such as JSON files, CSV files, SQL database, and Azure Table storage to the Cosmos DB with the Azure Cosmos DB Migration Tool.

Globally, supply chain with Industry 4.0 is transformed into a smart and effective procedure to produce new outlines of income. Hence, the key impression motivating Industry 4.0 is to guide companies by transforming current manual processes with digital technologies.
Hard-copy of container proof of delivery (POD), for example, is still necessary in today’s container trucking industry. Hence, storing images and files for document generation and printing later is still a key feature in the digitalised supply chain workflow.

On Azure, we can make use of Blob Storage to store large, discrete, binary objects that change infrequently, such as the documents like Proof of Delivery mentioned earlier.
In addition, there is another service called Azure Files available to provide serverless enterprise-grade cloud file shares. Azure Files can thus completely replace or supplement traditional on-premises file servers or NAS devices.
Hence, as shown in the screenshot below, we can upload files from a computer to the Azure File Share directly. Then the files will be accessible in another computer which is also connected to the Azure File Share, as shown below.

The Data Team
Setting up a new data team, especially in a startup, is a challenging problem. We need to explore roles and responsibilities in the world of data.
There are basically three roles that we need to have in a data team.
- Database Administrator: In charge of operations such as managing the databases, creating database backups, restoring backups, monitoring database server performance, and implementing data security and access rights policy.
- Tools: SQL Server Management Studio, Azure Portal, Azure Data Studio, etc.
- Data Engineer: Works with the data to build up data pipeline and processes as well as apply data cleaning routine and transformations. This role is important to turn the raw data into useful information for the data analysis.
- Tools: SQL Server Management Studio, Azure Portal, Azure Synapse Studio.
- Data Analysis: Explores and analyses data by creating data visualisation and reporting which transforms data into insights to help in business decision making.
- Tools: Excel, Power BI, Power BI Report Builder
In 2016, Gartner, a global research and advisory firm, shared a Venn Diagram on how data science is multi-disciplinary as shown below. Hence, there are some crucial technical skills needed, such as statistics, querying, modelling, R, Python, SQL, and data visualisation. Besides the technical skill, the team also needs to be equipped with business domain knowledge and soft skills.

In addition, the data team can also be organised in two manners, according to Lisa Cohen, Microsoft Principal Data Science Manager.
- Embedded: The data science teams are spread throughout the company and each of the teams serves specific functional team in the company;
- Centralised: There will be a core data team providing services to all functional teams across the company.





























