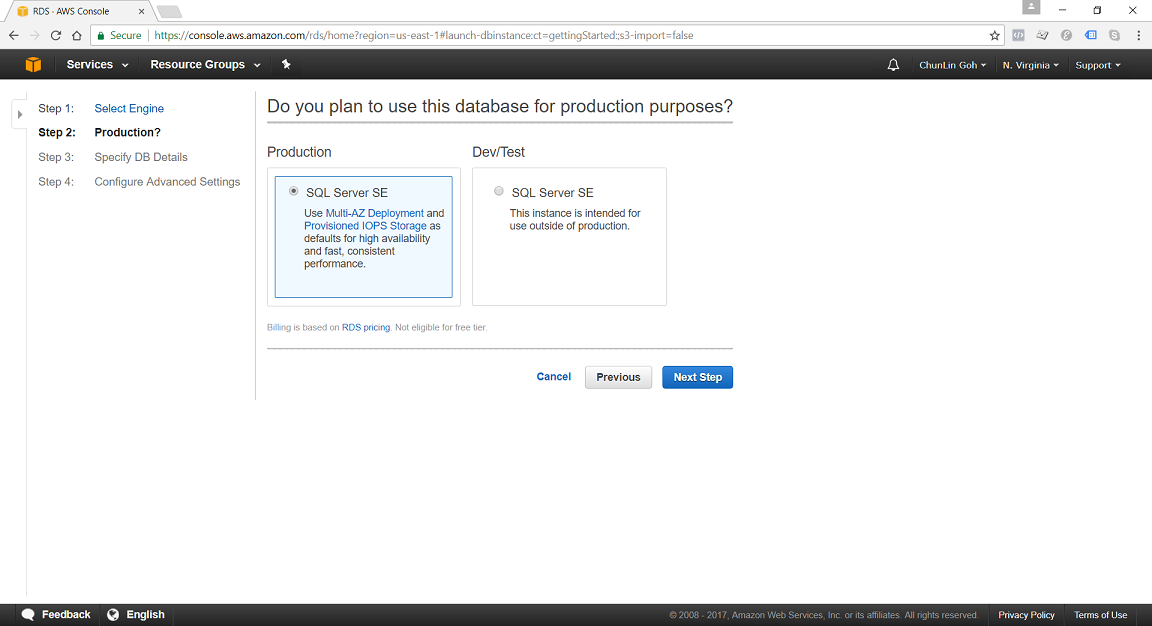
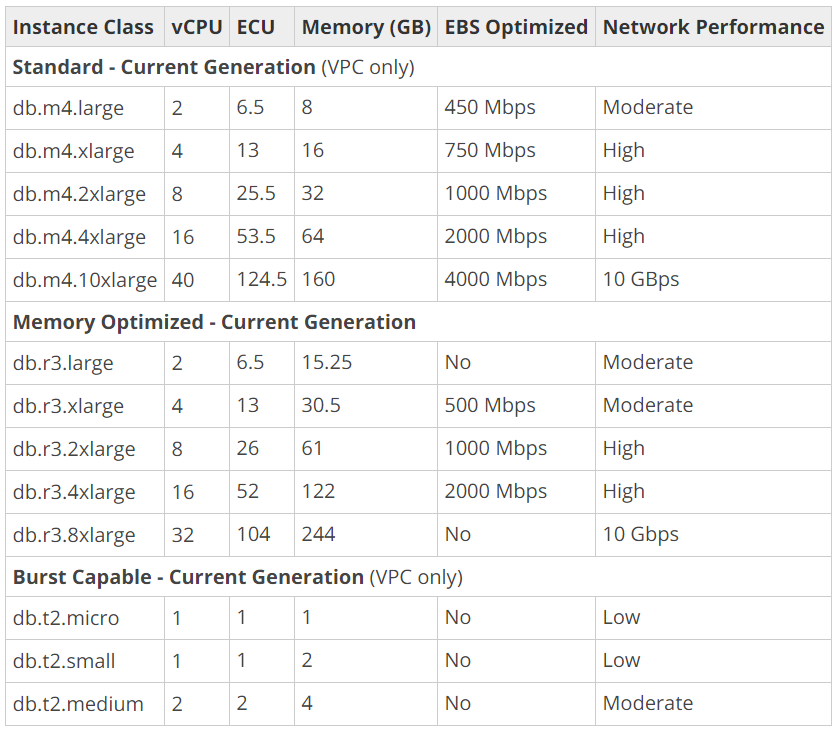
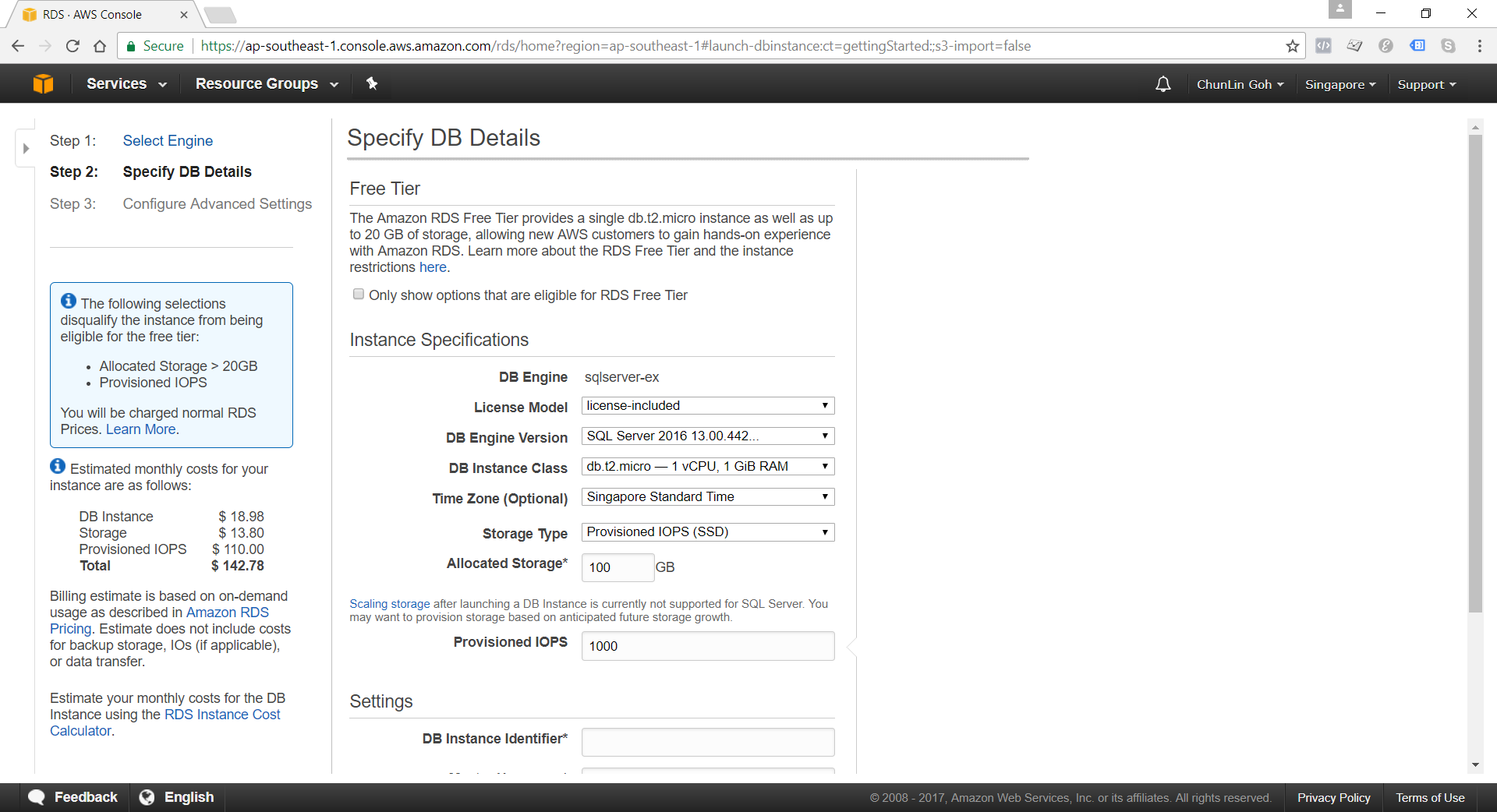
Continue from the previous topic…
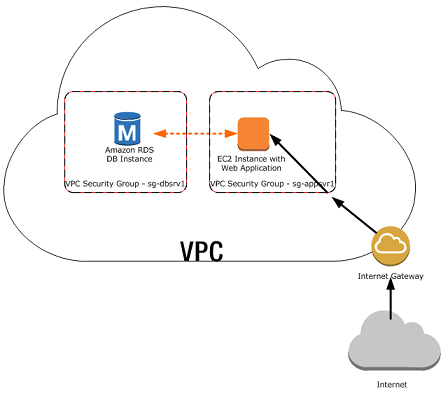
Playing YouTube video via console is cool but it’s not user friendly. Hence, I decided to move on to make it a web app. Design of a web app that I chose to follow is the one shared in Sau Sheong Chang’s book, Go Web Programming. The following diagram covers the overview of the architecture of the web app.

Hence, I started of with two folders and two Go files in the project folder. The two folders are public and templates folders. The public folder stores all CSS files and Javascript files. Then we have one index.go file which is basically the handler function for the homepage of our web app and finally server.go file.
The server.go
In the server.go file, we have our multiplexer which in charge of inspecting the URL being requested and redirecting the request to the correct handler. The main function also sits in server.go file. There is where we also connect to the database which has its connection made to be global. The following code shows the beginning of our main function.
package main
...
var db *sql.DB
func main() {
var err error
// Initialize connection string.
var connectionString = fmt.Sprintf(os.Getenv("CONNECTION_STRING"))
// Initialize connection object.
db, err = sql.Open("postgres", connectionString)
checkError(err)
// Set up multiplexer
mux := http.NewServeMux()
// Handle static files in the public folder
staticFiles := http.FileServer(http.Dir("public"))
mux.Handle("/static/", http.StripPrefix("/static/", staticFiles))
mux.HandleFunc("/index", index)
server := &http.Server{
Addr: "127.0.0.1:8081",
Handler: mux,
}
server.ListenAndServe()
}
There is one thing that needs to take note is that, as described on the GoDoc, “The returned DB (of sql.Open) is safe for concurrent use by multiple goroutines and maintains its own pool of idle connections. Thus, the Open function should be called just once. It is rarely necessary to close a DB.” So we don’t close the DB here.
The index.go
For the index.go file where we have our homepage handler function, we will first connect to the database to retrieve the list of videos from the table. In addition, the index handler function will be in charge of generating the HTML responses with templates that we define in templates folder, which is index.html in this case.
The following code shows the index handler function where it retrieves all the video records from the table then store them into a map, the built-in dictionary data type in Go.
package main
...
func index(writer http.ResponseWriter, request *http.Request) {
template, _ := template.ParseFiles("templates/index.html")
err := db.Ping()
checkError(err)
if err != nil {
template.Execute(writer, "Cannot connect to the database")
} else {
// Read data from table.
...
sqlStatement := "SELECT * FROM videos;"
rows, err := db.Query(sqlStatement)
checkError(err)
defer rows.Close()
videos := make(map[string]string)
...
template.Execute(writer, videos)
}
}
The templates/index.html
Now, let’s see what’s inside index.html template file. It basically uses the Bootstrap 4.2.1 template that I downloaded from Bootswatch.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>YouTube RePlayer</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<link rel="stylesheet" href="static/bootstrap.min.css" media="screen">
</head>
<body>
...
{{ range $videoId, $videoName := . }}
...
<span>{{ $videoName }}</span>
...
{{ end }}
...
</body>
</html>
There are two highlights in the code above.
Firstly, even though we put the CSS and JS files in the public folder, we still have their relative path as “static/…”. The reason is because of the lines in server.go as shown below.
// Handle static files in the public folder
staticFiles := http.FileServer(http.Dir("public"))
mux.Handle("/static/", http.StripPrefix("/static/", staticFiles))
Secondly, we iterate through the map using range. That will help to list down the videos we retrieved earlier on the HTML side.
The public Folder
Since we are using Bootstrap, we need to have the CSS and JS files of the framework locally. Hence, they are all put under the public folder. Then files with my customized CSS and JS codes are also put in this folder.

Form Submission
Now I move on to add a function that allows users to add new YouTube video the the video list. On HTML, we have the following hidden fields. They are hidden fields because the values, i.e. YouTube video id and video title, are retrieved from the URL and the YouTube API, respectively.
<form action="/addVideo" method="POST">
<input id="hidVideoID" name="hidVideoID" type="hidden" />
<input id="hidVideoName" name="hidVideoName" type="hidden" />
<input id="btnAddToList" type="submit" class="btn btn-primary btn-lg" value="Add to List"></input>
</form>
After that, due to the fact that I want the form to be posted to the relative request URL /addVideo, so there is a new handler needed. Hence, a new line as follows is added to the server.go file.
mux.HandleFunc("/addVideo", addVideo)
Then we have our new handler function in a new file, addVideo.go, as shown below.
package main
...
func addVideo(writer http.ResponseWriter, request *http.Request) {
request.ParseForm()
err := db.Ping()
checkError(err)
if err != nil {
http.Redirect(writer, request, "/index", http.StatusSeeOther)
} else {
// Insert data into the table.
sqlStatement := "INSERT INTO videos (name, url) VALUES ($1, $2);"
_, err = db.Exec(sqlStatement, request.PostForm["hidVideoName"][0], "https://www.youtube.com/watch?v="+(request.PostForm["hidVideoID"][0]))
checkError(err)
http.Redirect(writer, request, "/index", http.StatusSeeOther)
}
}
As the code above shows, after the data is successfully saved to the database table, we need to redirect the user back to the homepage.
References
1. Golang: http.Redirect;
2. Golang SQL Database Open and Close;
3. Golang: How to Redirect to an URL.