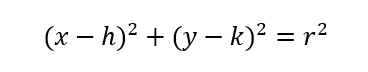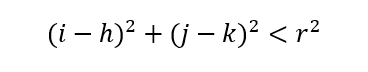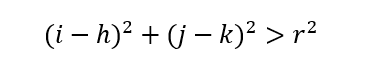I like to explore interesting new technologies. I also love to learn more from the materials available on Microsoft Virtual Academy, Google Developers channel, and several other tech/dev events.
Starting from 23rd of June 2021, the “Install” button of the apps that I own on Microsoft Store no longer work. It turns out that this issue does not only happen on the UWP applications that I build, but also other apps in the market. The following animated GIF shows the problem.
This prevents me to get the app installed on my Windows 10 machine. Arggg!
The expected behavior will be an installation of the process will start right after we click on the “Install” button with a progress bar displayed and the “Install” button hidden.
After spending some time on googling, I realised that I was not the only one encountering this issue. In fact, this problem has been around for years. The oldest post that I could find now is a discussion thread posted on 24th of July 2019 on Microsoft Community platform. From the discussion and some other proposed solutions online, I listed down suggestions that I had tried in this post. Interestingly, only the last suggestion, i.e. Suggestion 04, works for me.
Suggestion 01: Logout and Re-Login
This does not work.
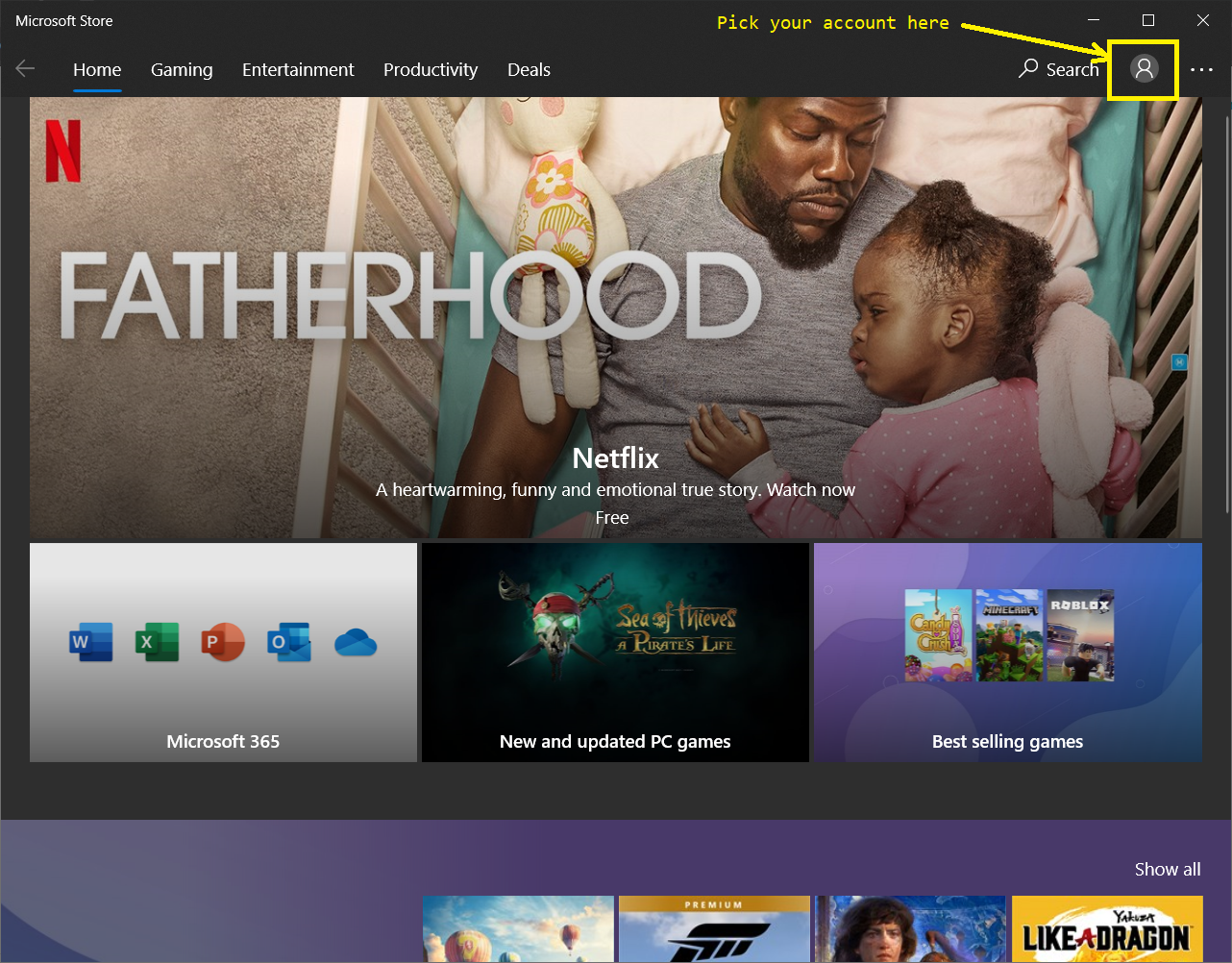
However, if you insist to try, you can always click on the profile icon at the top-right of Microsoft Store to pick your account and sign yourself out from the Store. Then you can try to see if you are able to install apps again after re-login to the Store.
It’s quite strange that the Microsoft Store does not show my profile picture there.
Suggestion 02: Check for Pending Updates
We need to make sure that we are up to date and there are no mandatory pending updates, as shown in the following screenshot.
To check this, simply search for “Check for Updates” in the Windows 10 Start Menu and choose the “Check for Updates” located in the System Settings. We have to install any pending updates and then restart our computer. However, this doesn’t really work with me.
There are no pending updates for my machine.
Suggestion 03: Reset Windows Store
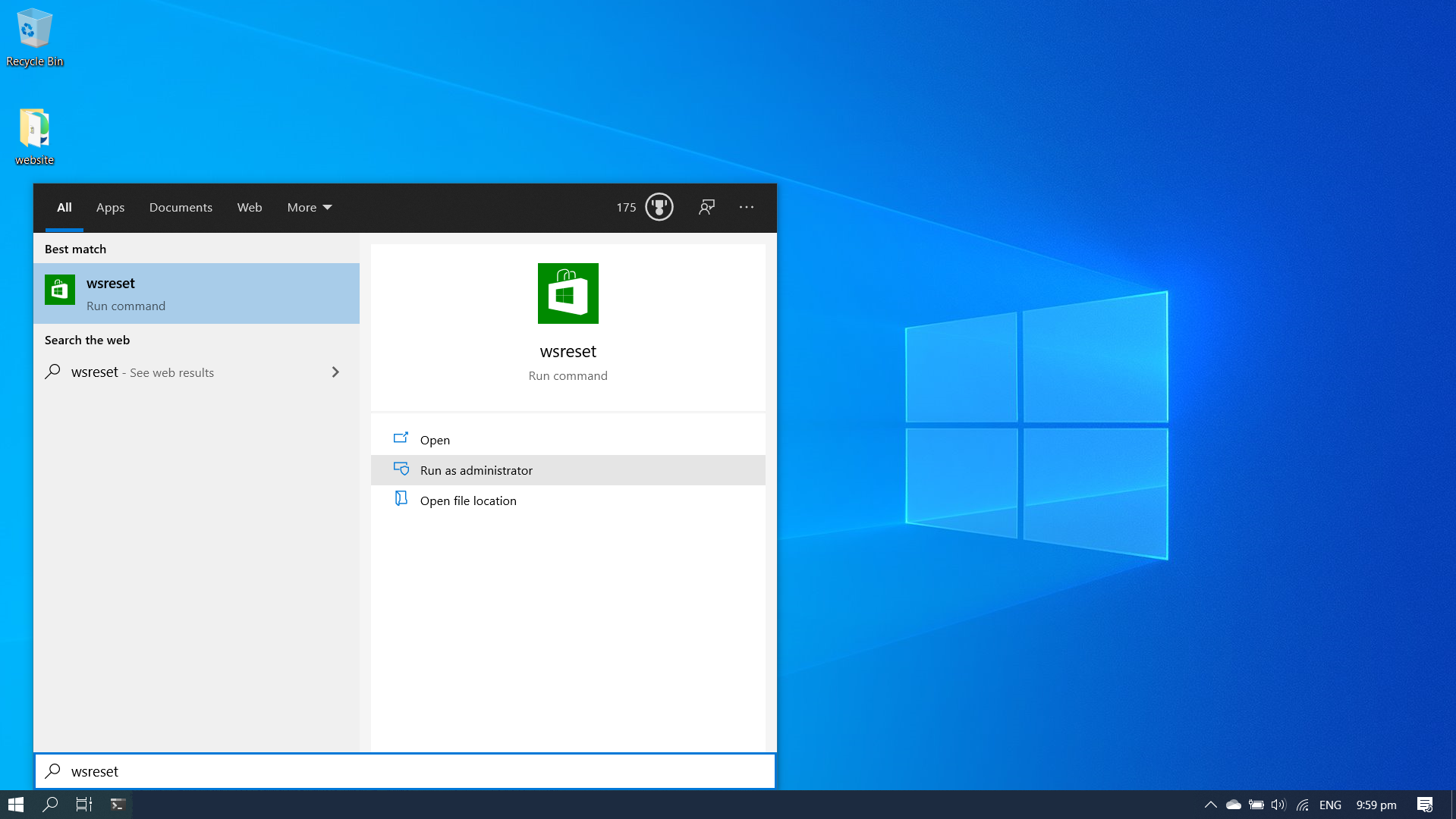
Often when we encountered issues on Microsoft Store, resetting the cache for Microsoft Store with the built-in command-line tool WSReset.exe can be a solution to those issues.
We simply need to run the WSReset.exe as an administrator, as shown in the screenshot below.
Where to find WSReset.exe.
After the tool successfully completes its work, it will launch the Microsoft Store.
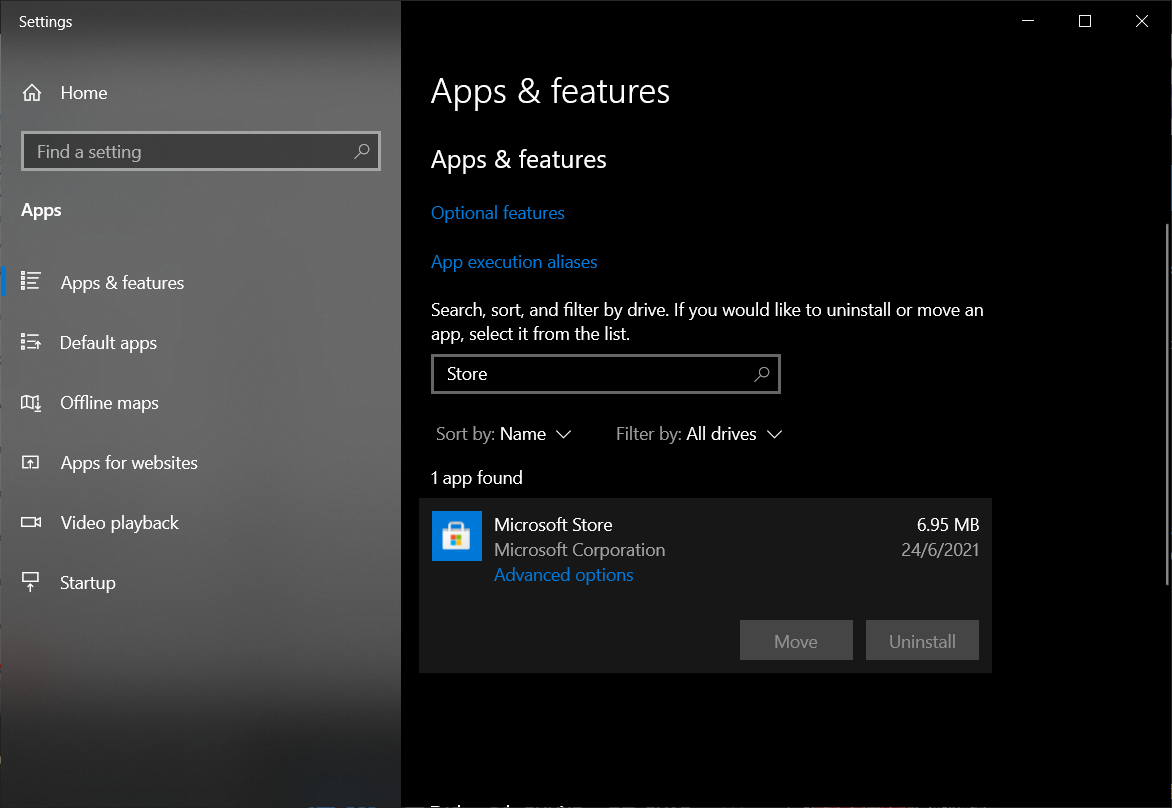
In addition, we can also reset Microsoft Store via “Apps & Features”, as shown in the screenshot below.
To reset Microsoft Store, we need to visit its “Advanced options” section.
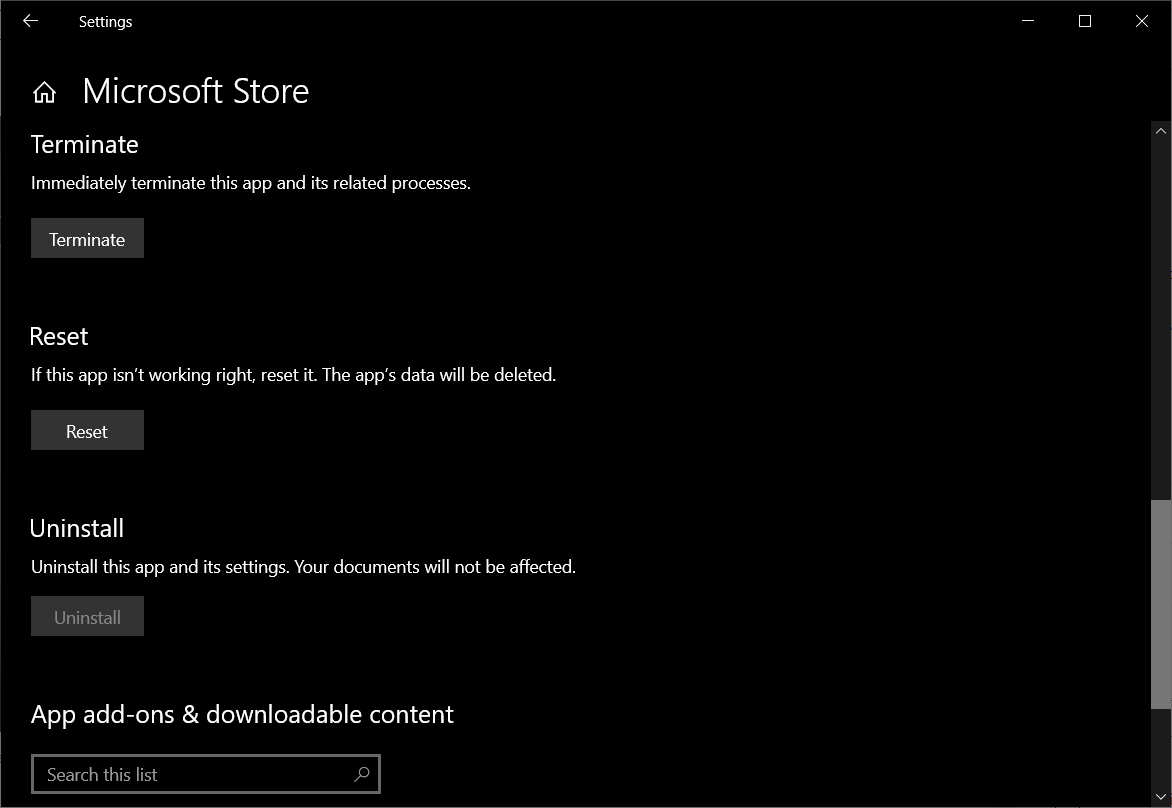
Then we can proceed to click on the “Reset” button to remove the app data of Microsoft Store, as shown in the screenshot below.
We can reset Microsoft Store whenever it is not working right.
Again, resetting Microsoft Store doesn’t solve my problem.
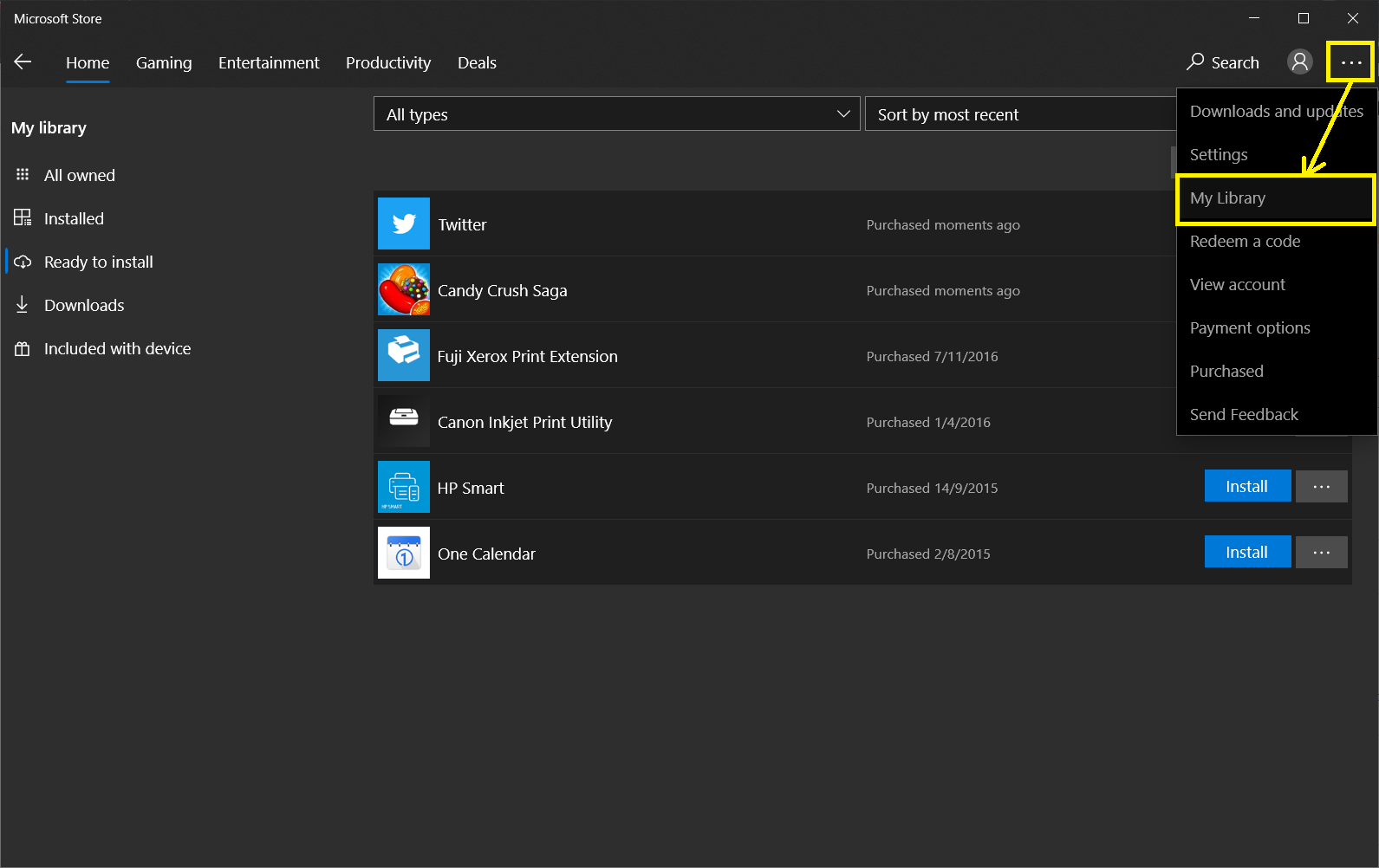
Suggestion 04: Installing Apps from My Library
This suggestion works for me.
This solution is mentioned in a YouTube video done by Apk Heaven. It turns out that there is also “Install” button for the Store apps there too, as shown in the screenshot below. You can try to find your apps by navigating the left-side menu.
“My Library” is accessible via the kebab menu at the top-right of Microsoft Store.
It is interesting to find out that the “Install” button here works for me. Hooray! Now I can finally install apps from Microsoft Store.
Personally, for devices such as computer, even though it might not work anymore for a specific purpose, but as long as it can still function, I try to find a use for it.
NEA encourages residents to recycle the electronic waste.
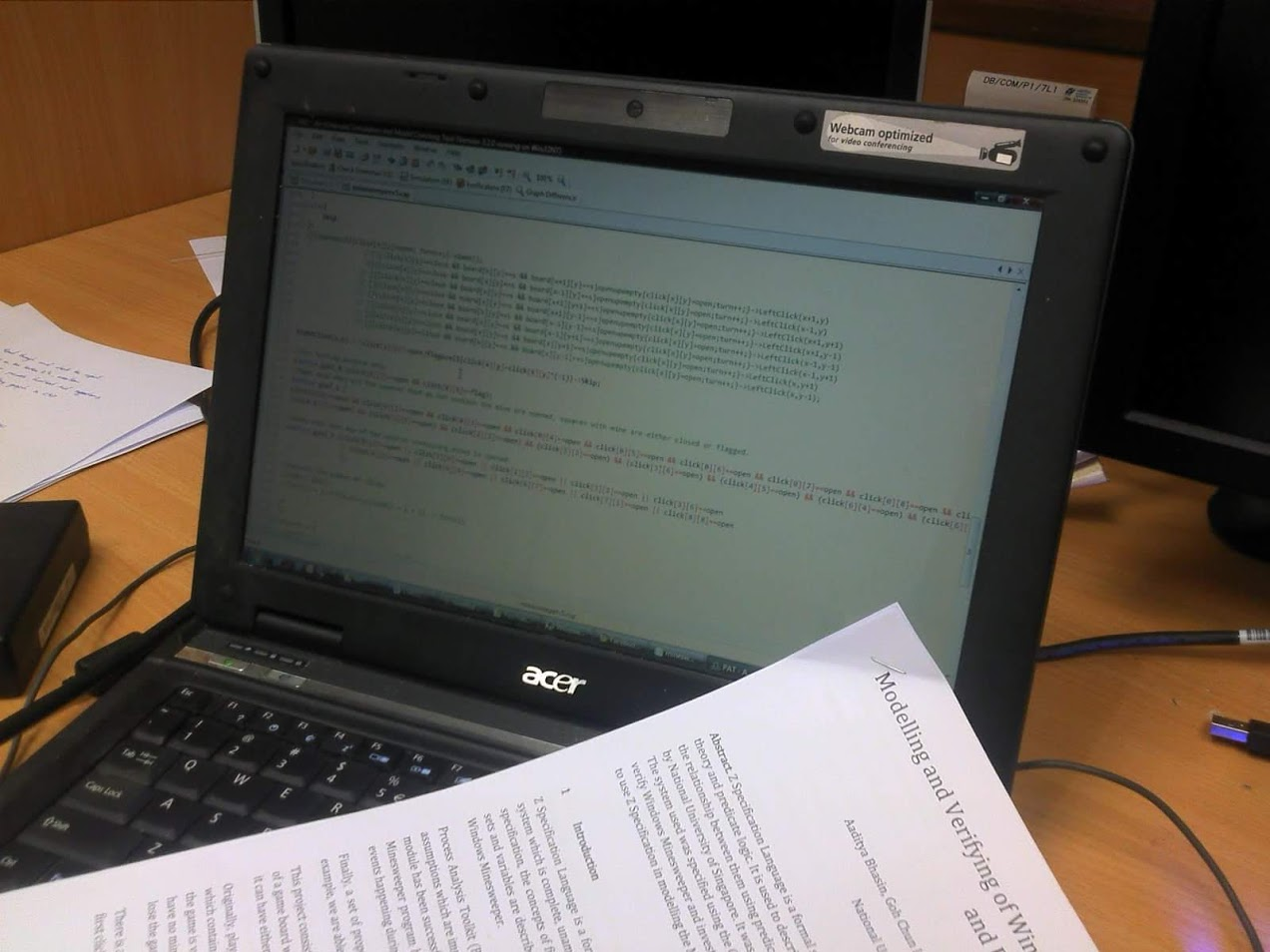
I bought my first laptop in 2007 when I enrolled in the National University of Singapore. It is an Acer TravelMate 6292 with Intel Core 2 Duo T7300 CPU and 2GB RAM. The operating system installed in the machine was Windows Vista and it ran very slow. Nevertheless, I still managed to live with it and successfully completed all the assignments and projects using the slow computer.
Acer TravelMate 6292 with Windows Vista installed is the only machine I had in my 4-year campus life.
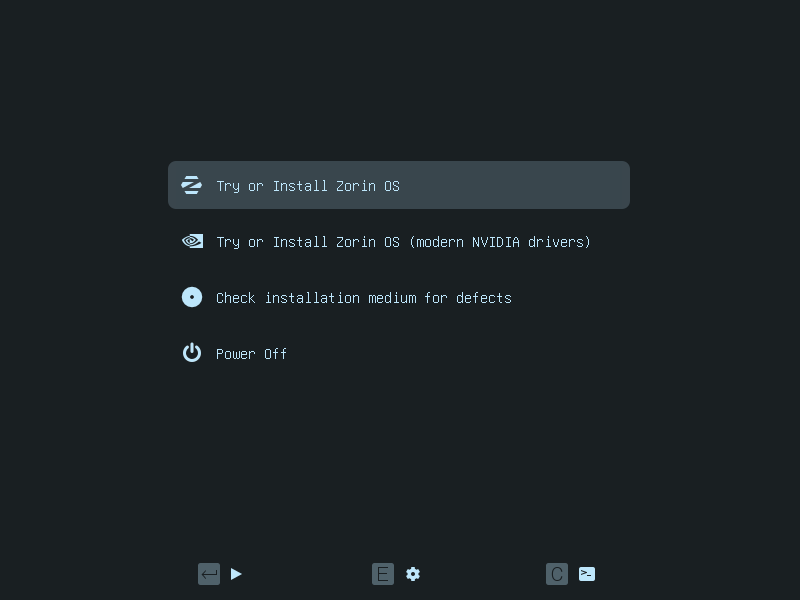
Hence, it’s now not a good idea to install Windows 10 on this 14-year-old laptop. Instead, I simply remove Windows and install a lightweight version of Linux, Zorin OS.
Why Zorin OS?
Zorin OS is fully graphical. It is a sexy looking Linux distro that manages to provide a good user experience – even with its lite edition. Speaking of user experience, although Zorin OS is an Ubuntu-based Linux distribution, it has a Windows-like graphical user interface. Hence, it is suitable to Windows users who are very accustomed to the way Windows works and are not interested in learning a new OS.
We can try Zorin OS before install it when we boot from the USB installation drive. (Image Source: zorinos.com)
Battery Replacement
The last time I changed the battery of my laptop is 10 years ago. In addition, recently the battery would become extremely hot until I couldn’t even grab my laptop when it was charging. Hence, it’s now time to replace the battery with a new one.
According to the spec of the battery, it has a battery life of 4 hours maximum and it would take 3 hours and 30 minutes to charge. In my case, I can only use the laptop to listen to an online radio on Chromium for at most 2 hours and 15 minutes after I have fully charged it. In addition, the CPU usage was only around 20% and RAM usage was around 1GB when the online radio is playing. However, for charging, currently it takes only around 2 hours to fully charge the battery.
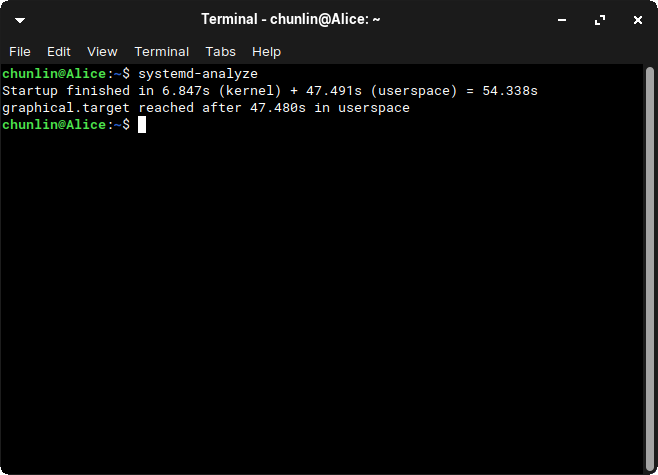
System Booting Time
Currently, Zorin OS Lite took about 1 minute to boot. To find the exact time it takes to boot, we can use a tool known as systemd-analyze.
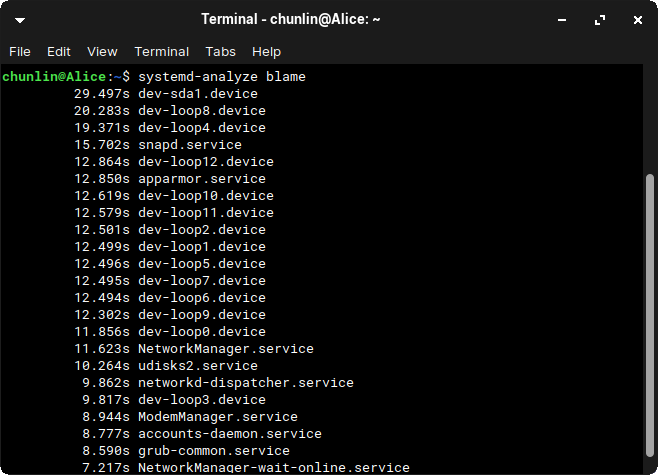
We can further list all the running services that started at the boot time along with the time they took with the systemd-analyze blame command, as shown below.
Using Gdebi Package Manager to install the downloaded .deb package of Microsoft Edge. (Guide on using gdebi)
Besides listening to online radio, I also like to watch videos on Bilibili and YouTube. Unlike YouTube, Bilibili is more engaging because it has a real-time captioning system known as Danmu (弹幕) that displays user comments as streams of scrolling subtitles overlaid on the video playback screen. Due to the Danmu system, Bilibili videos don’t play well on Firefox but performs better on Chromium and Edge.
Bilibili video performance on Firefox vs Chromium on Zorin OS Lite.
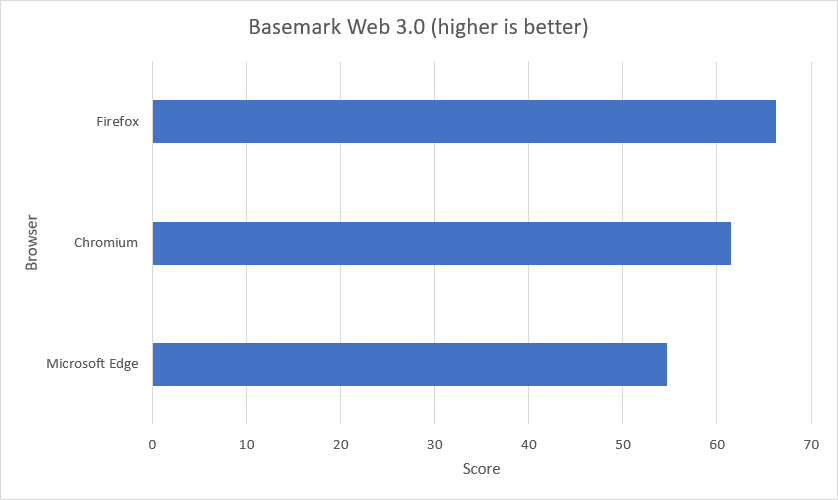
Out of curiosity, I run the Basemark benchmark on Chromium, Firefox, and Edge. Here, Basemark Web 3.0 is used because it tests how well our system can use web apps. The benchmark includes various system and graphic tests that use the web recommendations and features. Firefox is a clear winner in this benchmark, with Edge and Chromium had problems on running some of the tests and Firefox couldn’t run the WebGL 2.0 Test.
Score of three web browsers on Zorin OS Lite.
Screen Recording
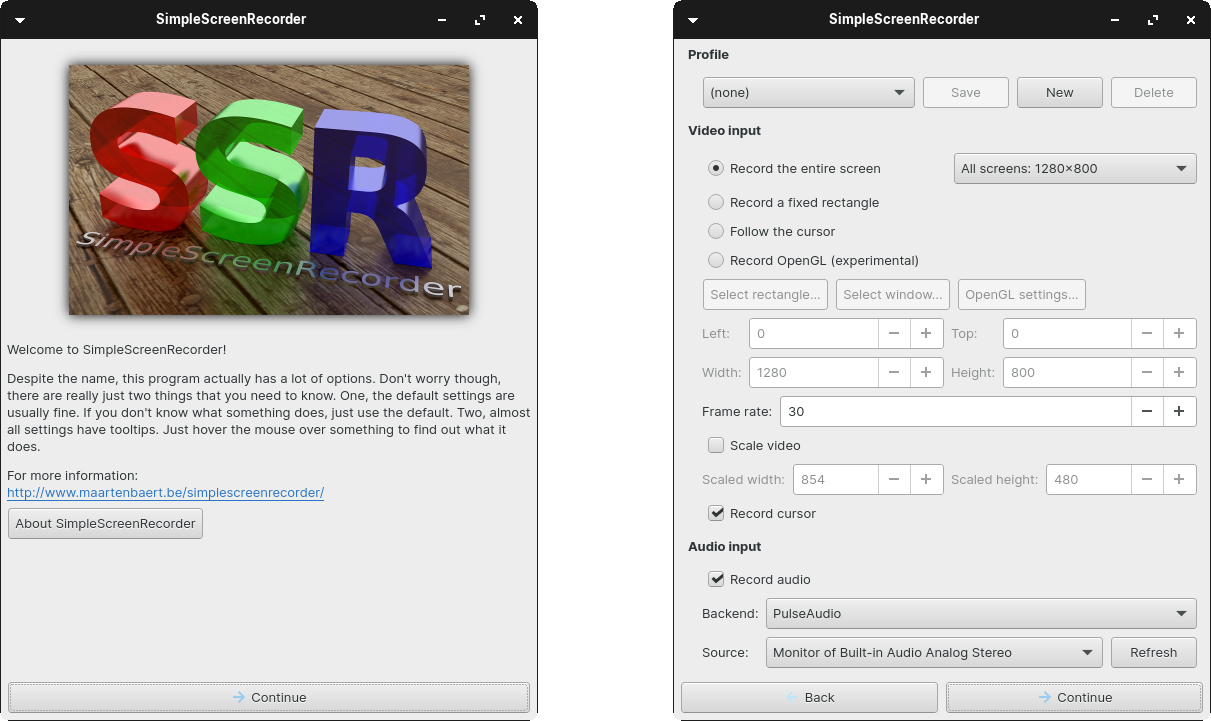
The video shown above is recorded using a Linux program known as SimpleScreenRecorder, which is user-friendly with a straightforward GUI.
SimpleScreenRecorder gives user a simple way to do a screen record on Linux.
To install the application, we simply need to execute the following commands.
After the videos were recorded, I edited them on my Windows machine which has a video editing software installed.
File Upload
To share the files from Zorin OS to my Windows machine, I decided to use Microsoft Azure Storage as a medium. On Zorin OS Software Store, we can easily find the Azure Storage Explorer and download it. After the Azure Storage Explorer is successfully installed, we can simply drag-and-drop files to Azure Storage and download them from other machines.
Downloading and installing Microsoft Azure Storage Explorer from Zorin OS Software store.
Chinese Input
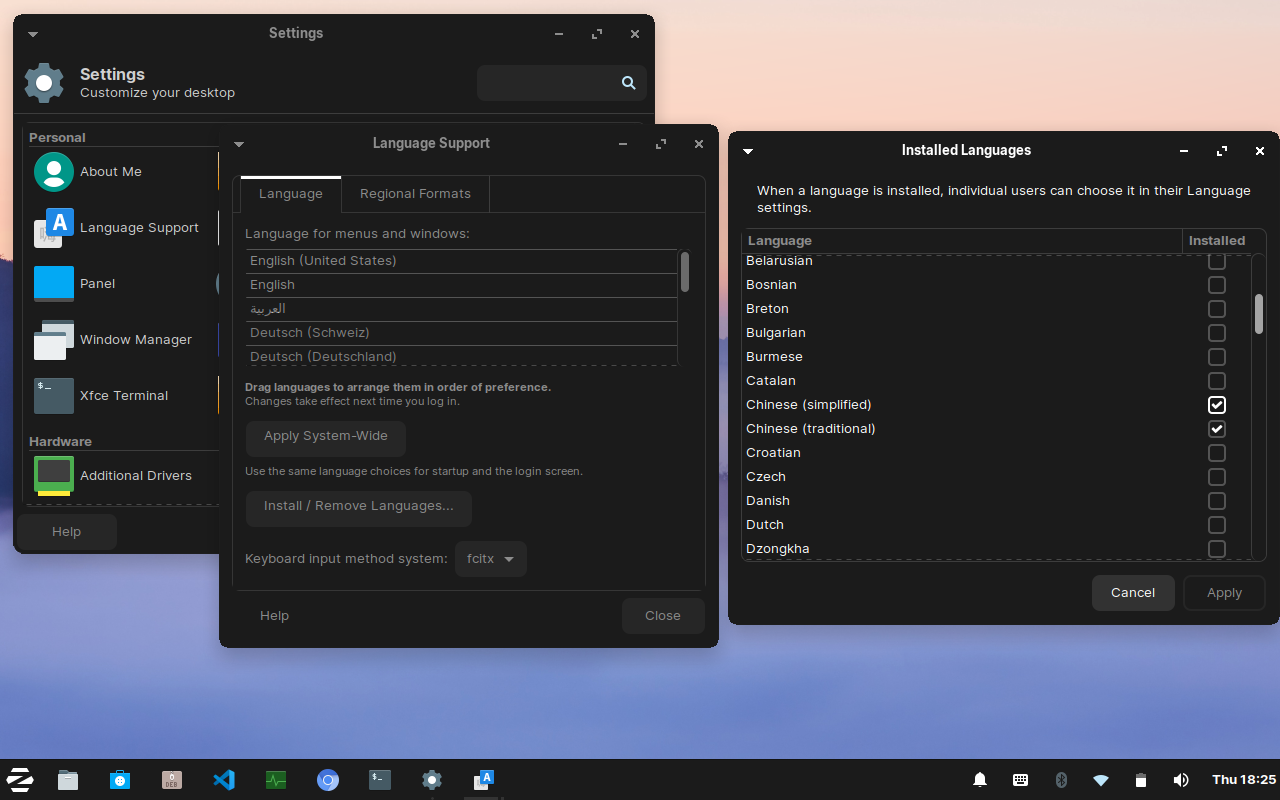
Sometimes, I need to use Chinese in websites such as Bilibili. To add Chinese input method on Zorin OS, we will first need to install fcitx with the following command.
Settings > Language Support > Install / Remove Languages;
Check “Chinese (simplified)”;
Set “fcitx” as the Keyboard Input Method System in the Language Support window;
Apply system-wide;
Restart the machine;
Choose “Fctix Configuration” from the “Zorin Start Menu”;
Click the + button and uncheck “Only show current language”;
Search “google pinyin” and add it;
Done, now we can type Chinese in Zorin OS.
Setting languages and keyboard input method system in Zorin OS.
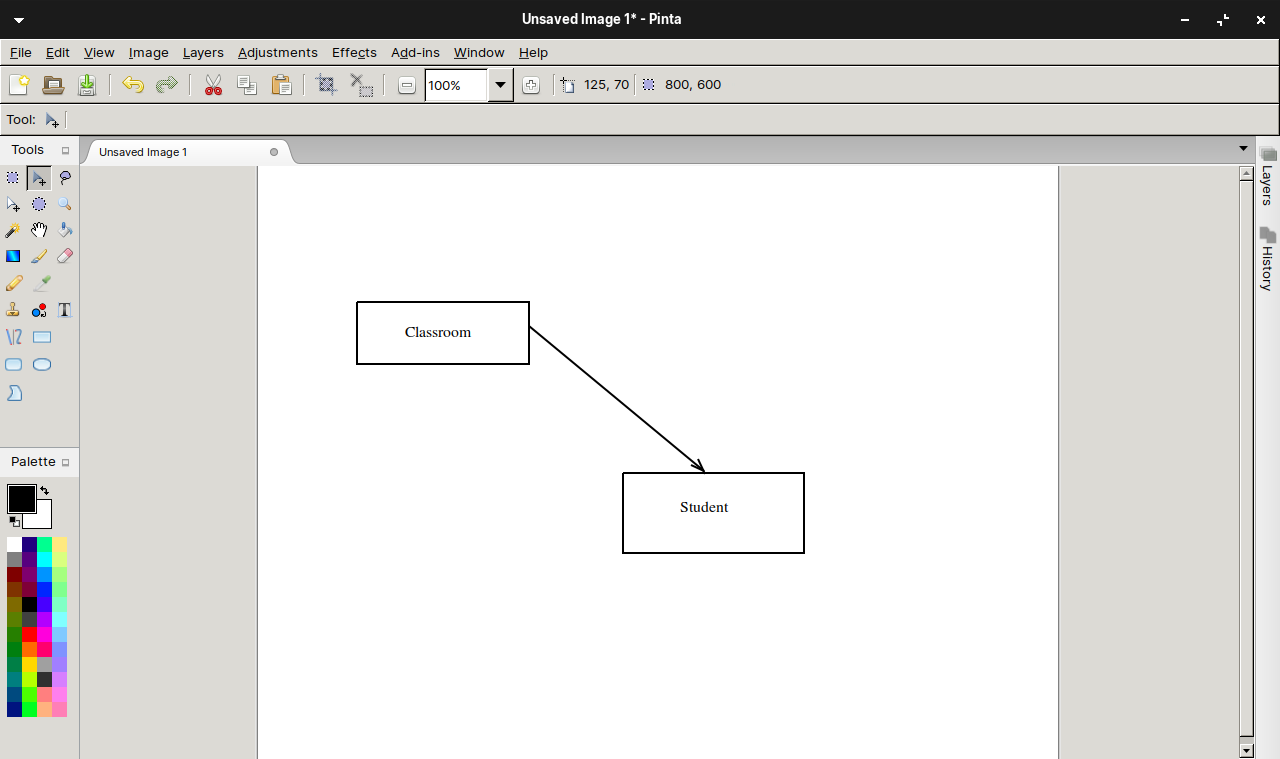
Drawing
I’ve also installed Pinta, a free and open-source program for drawing and image editing. The reason I choose to use Pinta is because it is designed in lieu of the Paint.NET on Windows.
Drawing diagram using Pinta.
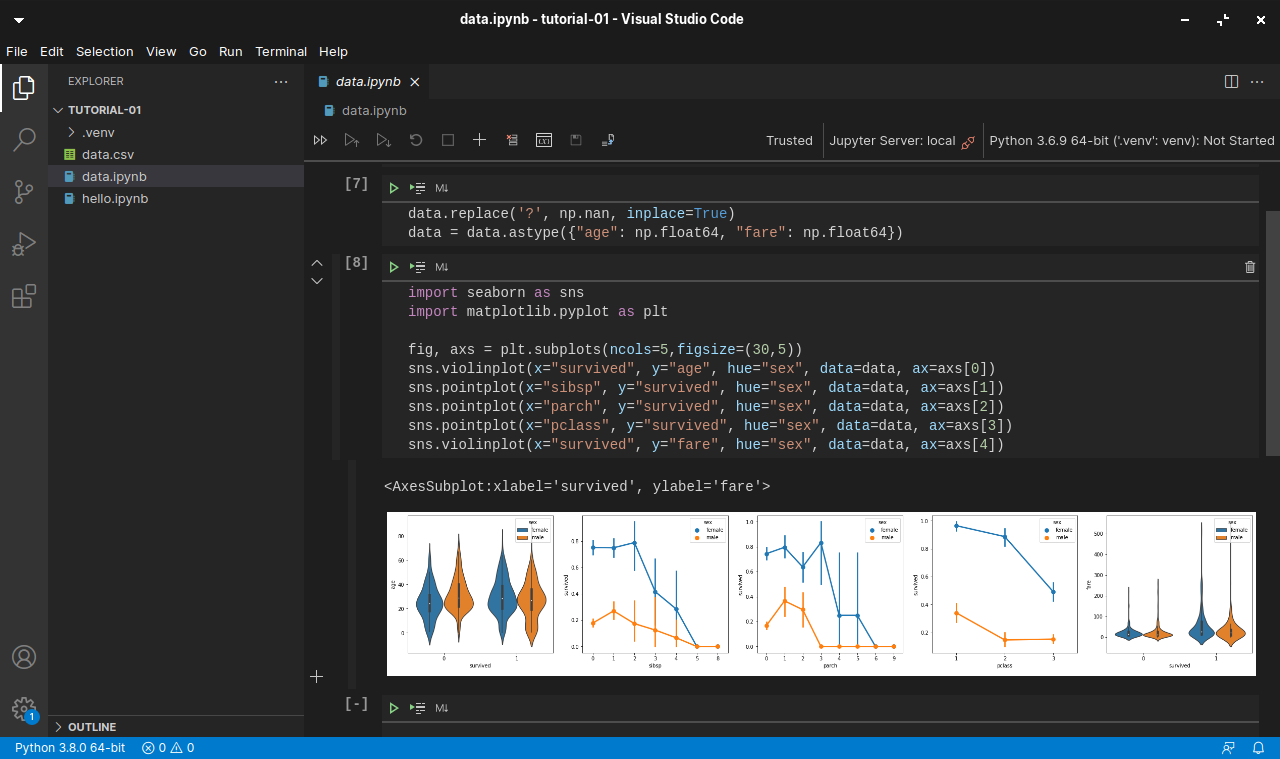
Programming
I also use the laptop to learn programming at my own time. Hence, I choose to install one of my user-friendly IDEs, i.e. Visual Studio Code.
Currently, I have installed Jupyter Notebooks extension on the VS Code. The first project that I am working on now is to learn how to install and use packages, such as pandas, numpy, seaborn, and matplotlib to do statistical data visualisation, as shown below.
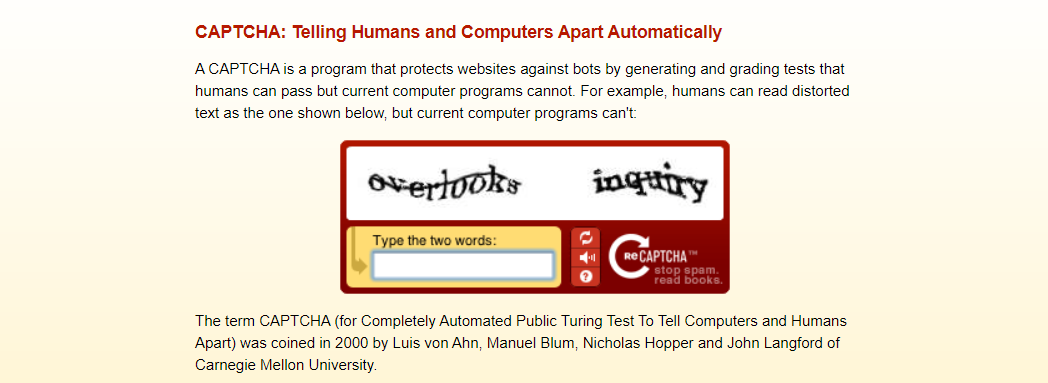
The words shown in reCAPTCHA come directly from old books that are being digitized. Hence, it does not only stop spam, but also help digitise books at the same time. (Source: reCAPTCHA)
A team led by Prof Gao Haichang from Xidian University realised that, with the development of automated computer vision techniques such as OCR, traditional text-based CAPTHCAs are not considered safe anymore for authentication. During the IEEE conference in 2010, they thus proposed a new way, i.e. using an image based CAPTCHA which involves in solving a jigsaw puzzle. Their experiments and security analysis further proved that human can complete the jigsaw puzzle CAPTCHA verification quickly and accurately which bots rarely can. Hence, jigsaw puzzle CAPTCHA can be a substitution to the text-based CAPTCHA.
Xidian University, one of the 211 Project universities and a high level scientific research innovation in China. (Image Source: Shulezetu)
In 2019, on CSDN (Chinese Software Developer Network), a developer 不写BUG的瑾大大 shared his implementation of jigsaw puzzle captcha in Java. It’s a very detailed blog post but there is still room for improvement in, for example, documenting the code and naming the variables. Hence, I’d like to take this opportunity to implement this jigsaw puzzle CAPTCHA in .NET 5 with C# and Blazor. I also host the demo web app on Azure Static Web App so that you all can access and play with the CAPTCHA: https://jpc.chunlinprojects.com/.
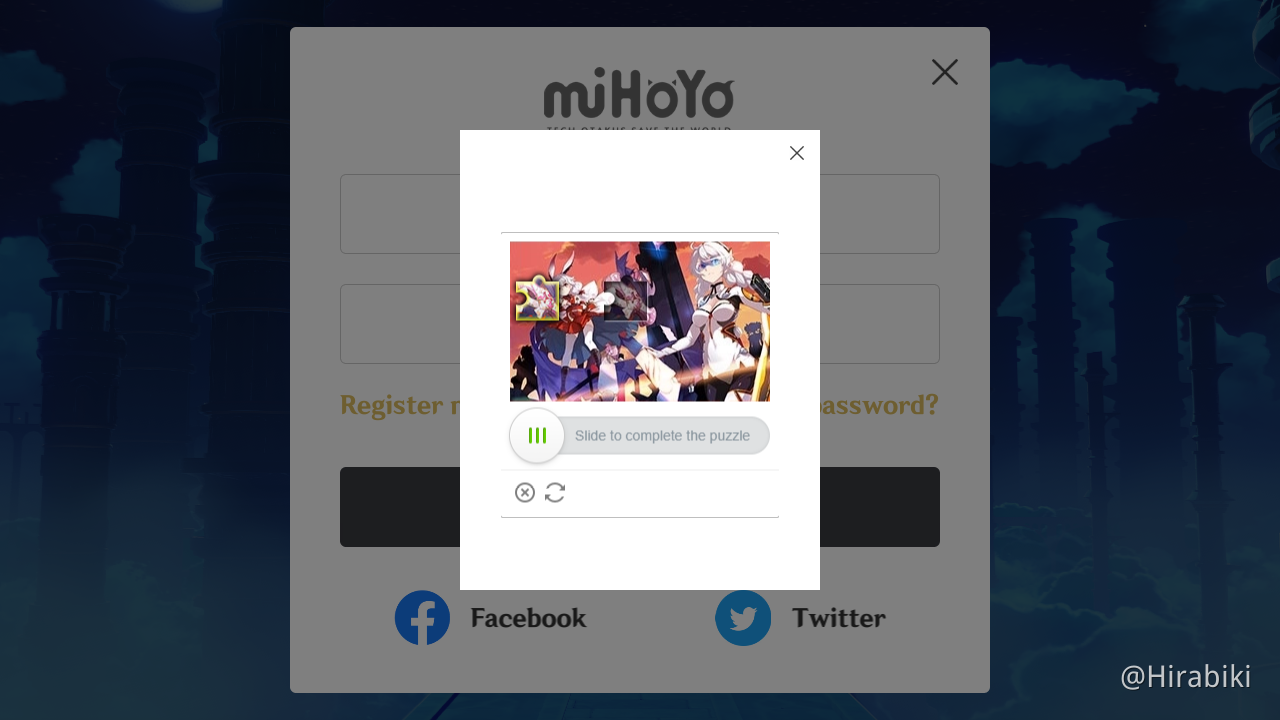
Today, jigsaw puzzle CAPTCHA is used in many places. (Image Credit: Hirabiki at HoYoLAB)
Jigsaw Puzzle CAPTCHA
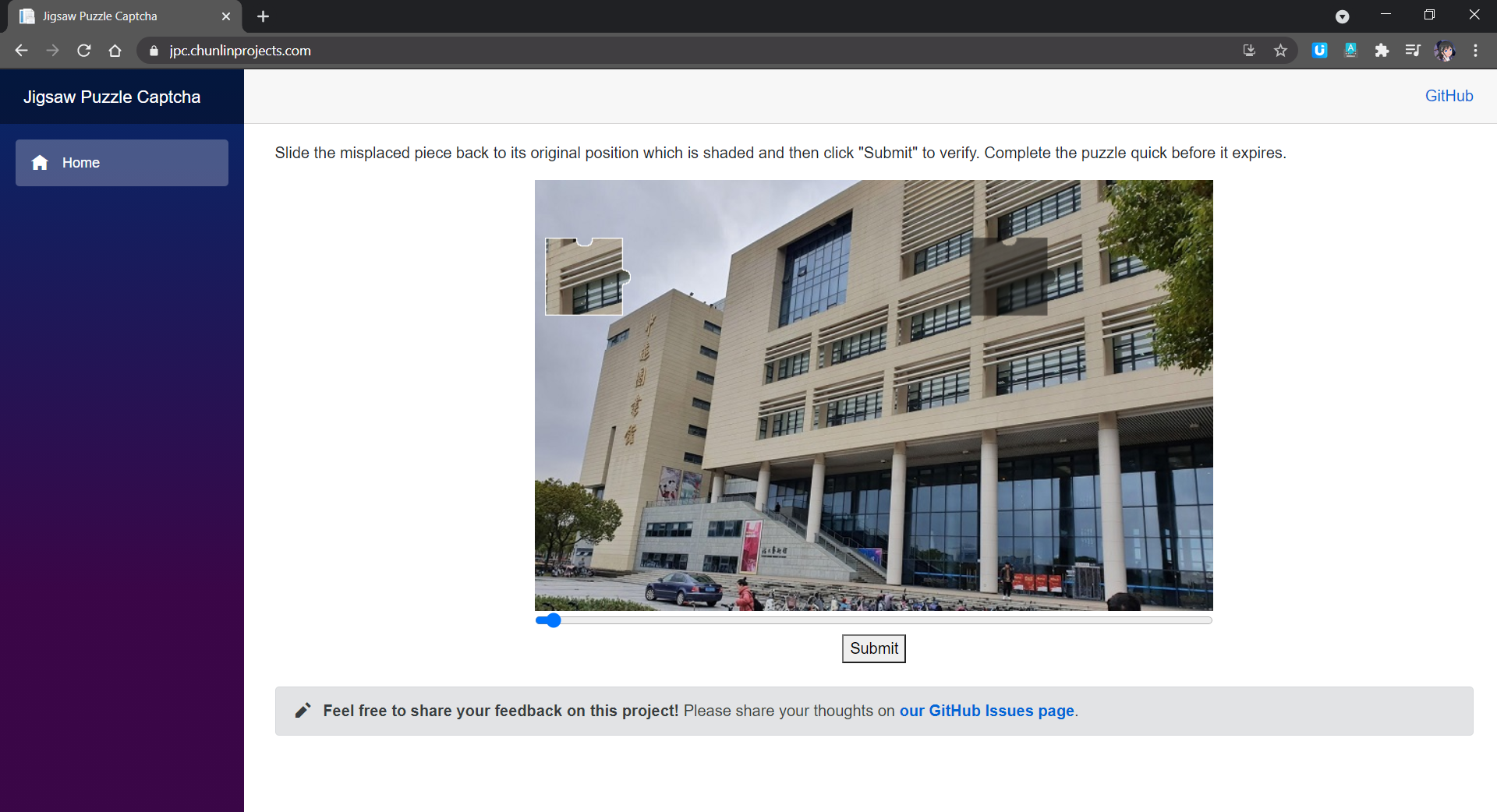
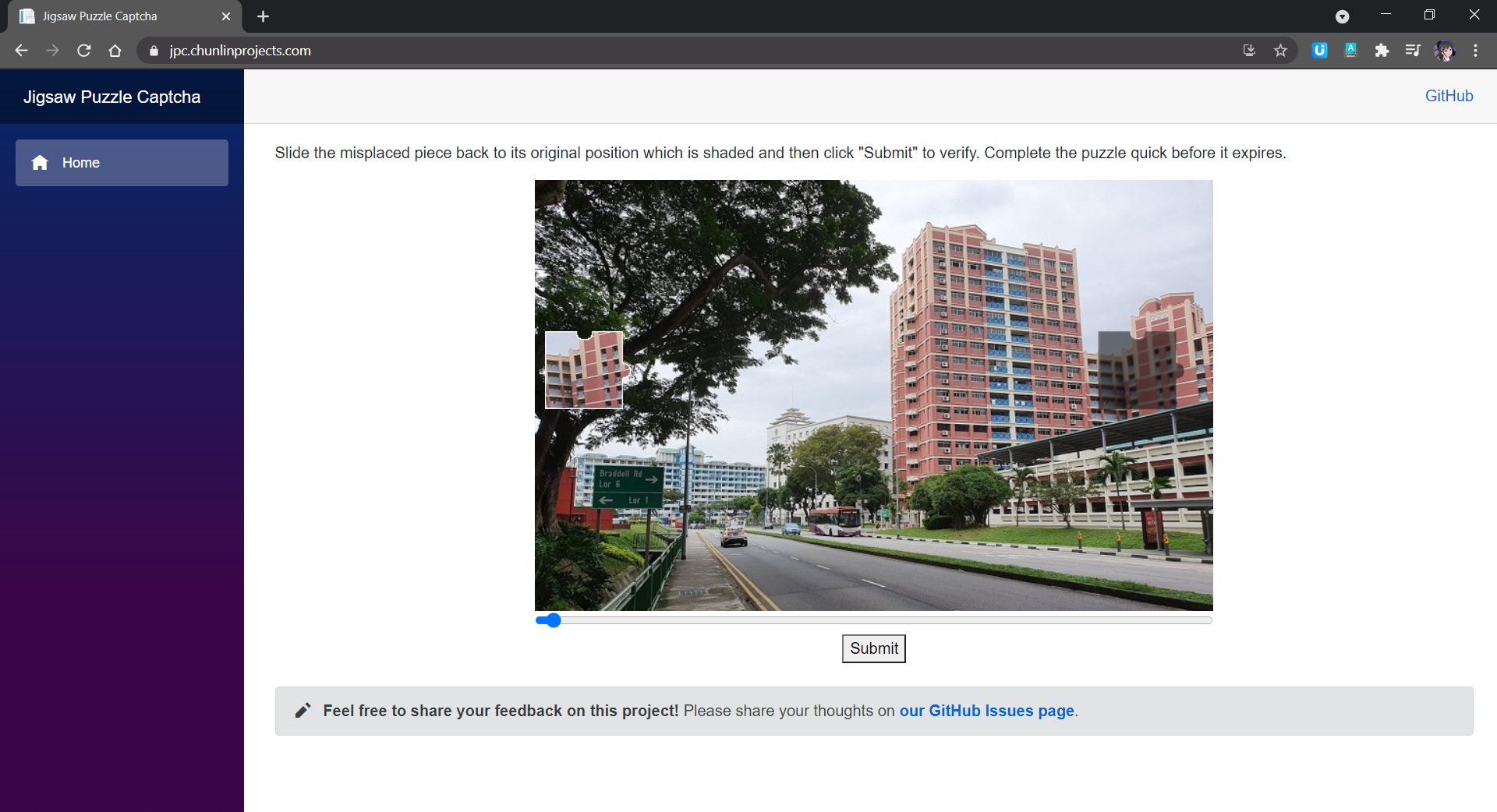
In a jigsaw puzzle CAPTCHA, there is usually a jigsaw puzzle with at least one misplaced piece where users need to move to the correct place to complete the puzzle. In my demo, I have only one misplaced piece that needs to be moved.
Jigsaw puzzle CAPTCHA implementation on Blazor. (Try it here)
As shown in the screenshot above, there are two necessary images in the CAPTCHA. One of them is a misplaced piece of the puzzle. Another image is the original image with a shaded area indicating where the misplaced piece should be dragged to. What users need to do is just dragging the slider to move the misplaced piece to the shaded area to complete the jigsaw puzzle within a time limit.
In addition, here the CAPTCHA only needs user to drag the missing piece horizontally. This is not only the popular implementation of the jigsaw puzzle CAPTCHA, but also not too challenging for users to pass the CAPTCHA.
Now, let’s see how we can implement this in C# and later deploy the codes to Azure.
Retrieve the Original Image
The first thing we need to do is getting an image for the puzzle. We can have a collection of images that make good jigsaw puzzle stored in our Azure Blob Storage. After that, each time before generating the jigsaw puzzle, we simply need to fetch all the images from the Blob Storage with the following codes and randomly pick one as the jigsaw puzzle image.
public async Task<List<string>> GetAllImageUrlsAsync()
{
var output = new List<string>();
var container = new BlobContainerClient(_storageConnectionString, _containerName);
var blobItems = container.GetBlobsAsync();
await foreach (var blob in blobItems)
{
var blobClient = container.GetBlobClient(blob.Name);
output.Add(blobClient.Uri.ToString());
}
return output;
}
Define the Missing Piece Template
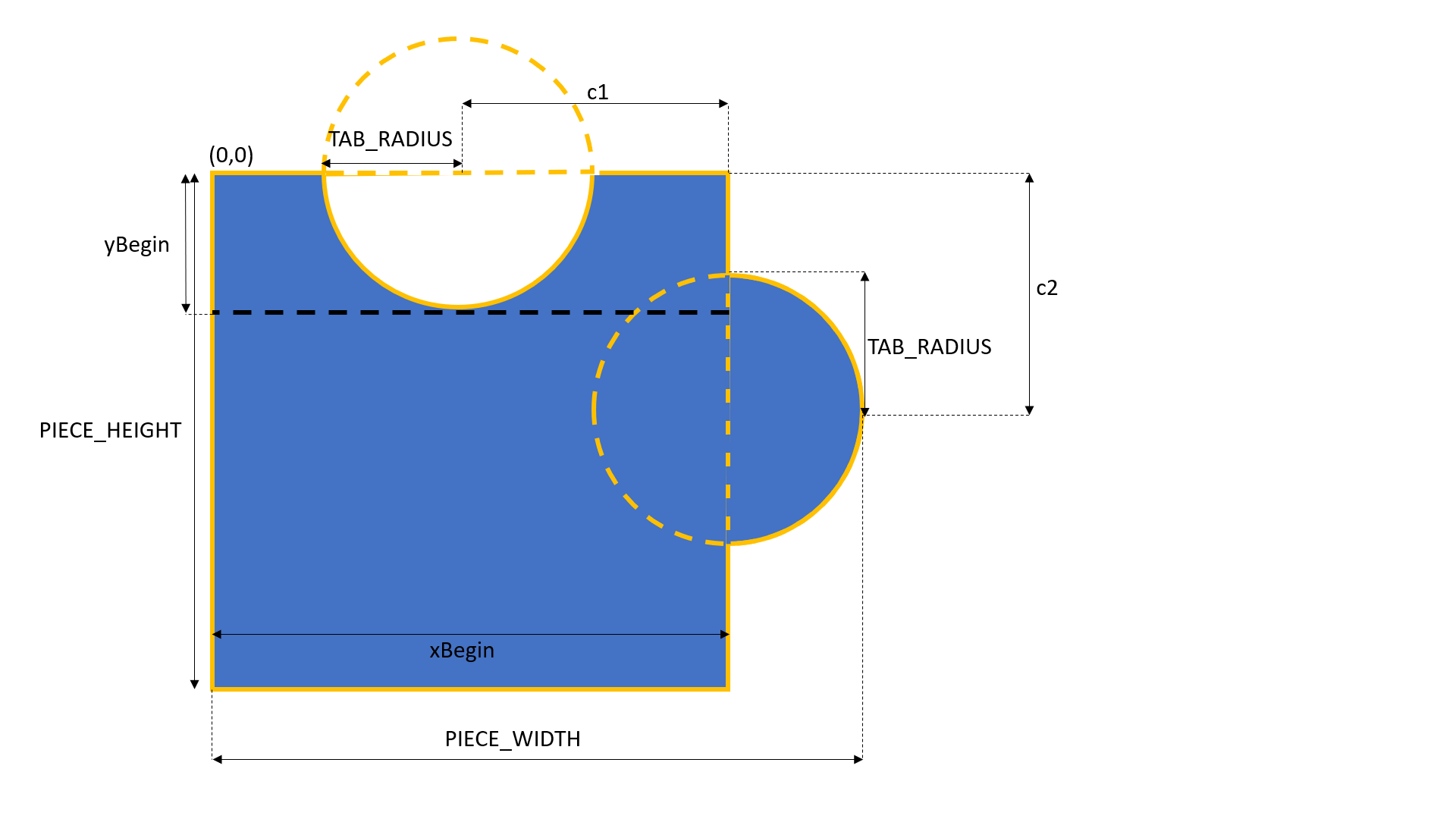
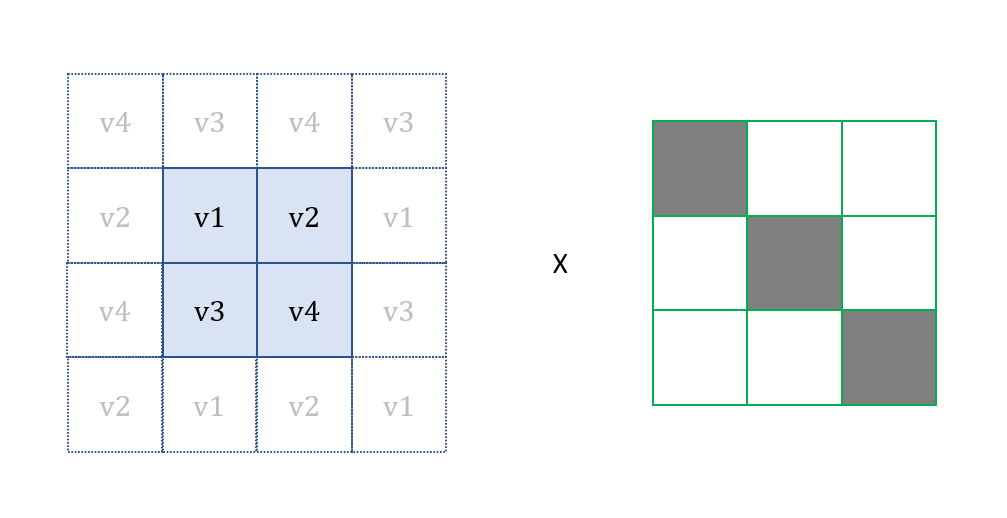
To increase the difficulty of the puzzle, we can have jigsaw pieces with different patterns, such as having tabs appearing on different sides of the pieces. In this demo, I will stick to just one pattern of missing piece, which has tabs on the top and right sides, as shown below.
The missing piece template.
The tabs are basically two circles with the same radius. Their centers are positioned at the middle point of the rectangle side. Hence, we can now build a 2D matrix for the pixels indicating the missing piece template with 1 means inside of the the piece and 0 means outside of the piece.
In addition, we know the general equation of a circle of radius r at origin (h,k) is as follows.
Hence, if there is a point (i,j) inside the circle above, then the following must be true.
If the point (i,j) is outside of the circle, then the following must be true.
With these information, we can build our missing piece 2D matrix as follows.
After that, we can determine the border of the missing piece easily too from just the template data above. We then can draw the border of the missing piece for better user experience when we display it on screen.
Next, we need to tell the user where the missing piece should be dragged to. We will use the template data above and apply it to the original image we get from the Azure Blob Storage.
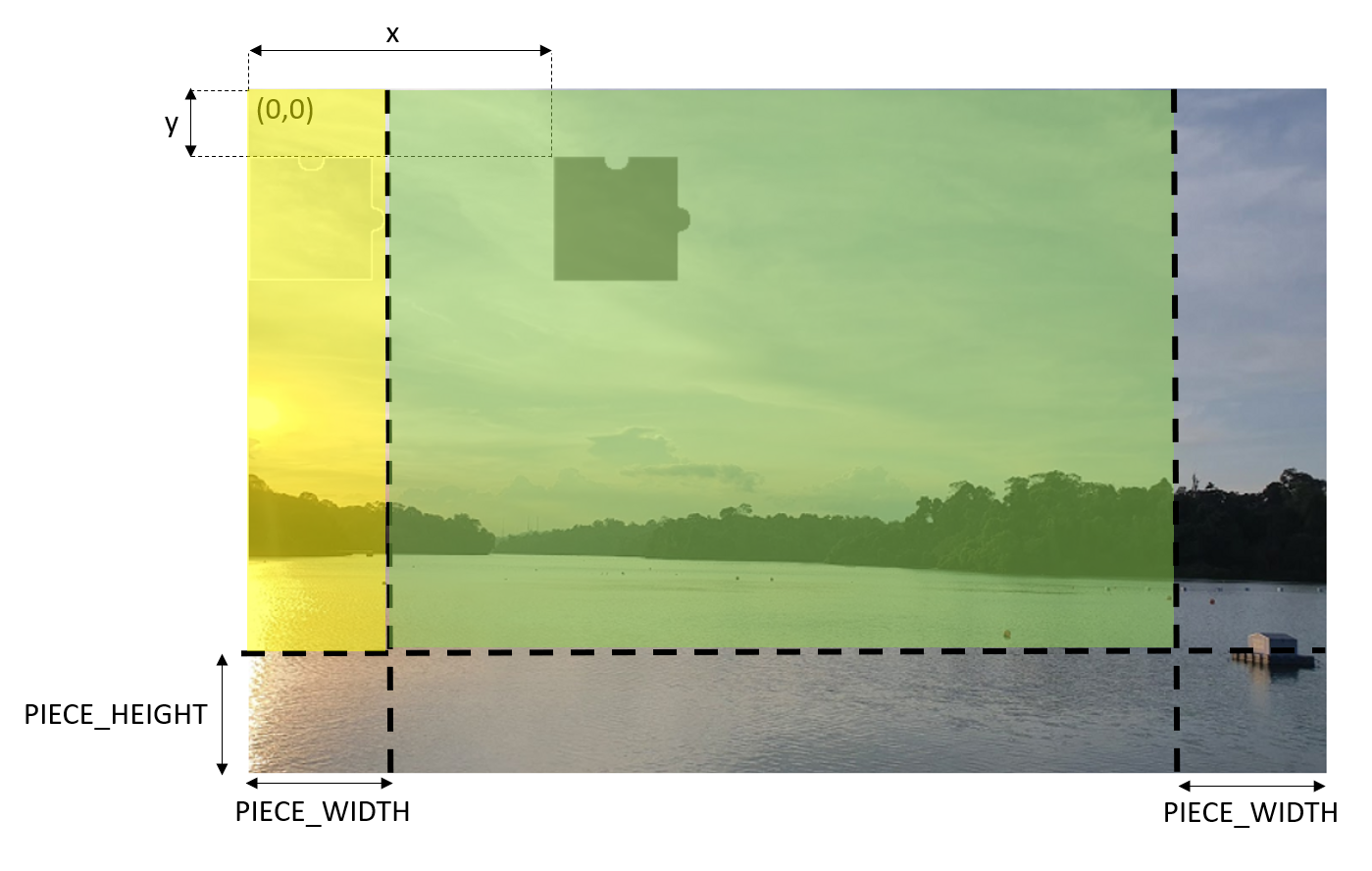
Due to the shape of the missing piece, the proper area to have the shaded area needs to be in the region highlighted in green colour below. Otherwise, the shaded area will not be shown completely and thus give users a bad user experience. The yellow area is okay too but we don’t allow the shaded area to be there to avoid cases where the missing piece covers the shaded area when the images first load and thus confuses the users.
Random random = new Random();
int x = random.Next(originalImage.Width - 2 * PIECE_WIDTH) + PIECE_WIDTH;
int y = random.Next(originalImage.Height - PIECE_HEIGHT);
Green area is where the top left of the shaded area should be positioned at.
Let’s assume the shaded area is at the point (x,y) of the original image, then given the original image in a Bitmap variable called originalImage, we can then have the following code to traverse the area and process the pixels in that area.
...
int[,] missingPiecePattern = GetMissingPieceData();
for (int i = 0; i < PIECE_WIDTH; i++)
{
for (int j = 0; j < PIECE_HEIGHT; j++)
{
int templatePattern = missingPiecePattern[i, j];
int originalArgb = originalImage.GetPixel(x + i, y + j).ToArgb();
if (templatePattern == 1)
{
...
originalImage.SetPixel(x + i, y + j, FilterPixel(originalImage, x + i, y + j));
}
else
{
missingPiece.SetPixel(i, j, Color.Transparent);
}
}
}
...
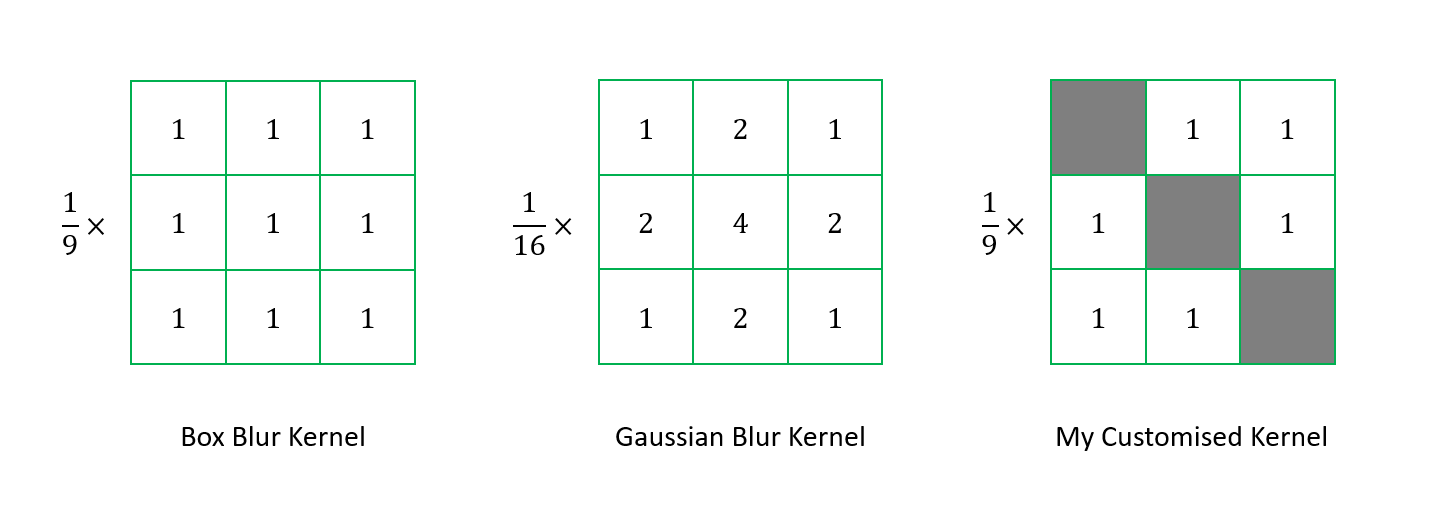
Kernels used in different types of image processing.
For the kernel, I don’t really follow the official Box Blur kernel or Gaussian Blur kernel. Instead, I dim the generated colour by forcing three pixel to be always black (when i = j). This is to make sure the shaded area is not only blurred but darkened.
private Color FilterPixel(Bitmap img, int x, int y)
{
const int KERNEL_SIZE = 3;
int[,] kernel = new int[KERNEL_SIZE, KERNEL_SIZE];
...
int r = 0;
int g = 0;
int b = 0;
int count = KERNEL_SIZE * KERNEL_SIZE;
for (int i = 0; i < kernel.GetLength(0); i++)
{
for (int j = 0; j < kernel.GetLength(1); j++)
{
Color c = (i == j) ? Color.Black : Color.FromArgb(kernel[i, j]);
r += c.R;
g += c.G;
b += c.B;
}
}
return Color.FromArgb(r / count, g / count, b / count);
What will happen when we are processing pixel without all 8 neighbouring pixels? To handle this, we will take the value of the pixel at the opposite position which is describe in the following diagram.
Applying kernel on edge pixels.
Since we have two images ready, i.e. an image for the missing piece and another image which shows where the missing piece needs to be, we can convert them into base 64 string and send the string values to the web page.
Now, the next step will be displaying these two images on the Blazor web app.
The purpose of API in this project is to retrieve the jigsaw puzzle images and verify user submissions. We don’t need a full server for our API because Azure Static Web Apps hosts our API in Azure Functions. So we need to implement our API as Azure Functions here.
We will have two API methods here. The first one is to retrieve the jigsaw puzzle images, as shown below.
[FunctionName("JigsawPuzzleGet")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "jigsaw-puzzle")] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
var availablePuzzleImageUrls = await _puzzleImageService.GetAllImageUrlsAsync();
var random = new Random();
string selectedPuzzleImageUrl = availablePuzzleImageUrls[random.Next(availablePuzzleImageUrls.Count)];
var jigsawPuzzle = _puzzleService.CreateJigsawPuzzle(selectedPuzzleImageUrl);
_captchaStorageService.Save(jigsawPuzzle);
return new OkObjectResult(jigsawPuzzle);
}
The Azure Function first retrieve all the images from the Azure Blob Storage and then randomly pick one to use in the jigsaw puzzle generation.
Before it returns the puzzle images back in a jigsawPuzzle object, it also saves it into Azure Table Storage so that later when users submit their answer back, we can have another Azure Function to verify whether the users solve the puzzle correctly.
In the Azure Table Storage, we generate a GUID and then store it together with the location of the shaded area, which is randomly generated, as well as an expiry date and time so that users must solve the puzzle within a limited time.
...
var tableClient = new TableClient(...);
...
var entity = new JigsawPuzzleEntity
{
PartitionKey = ...,
RowKey = id,
Id = id,
X = x,
Y = y,
CreatedAt = createdAt,
ExpiredAt = expiredAt
};
tableClient.AddEntity(entity);
...
Here, GUID is used as the RowKey of the Table Storage. Hence, later when user submits his/her answer, the GUID will be sent back to the Azure Function to help locate back the corresponding record in the Table Storage.
[FunctionName("JigsawPuzzlePost")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "jigsaw-puzzle")] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
var body = await new StreamReader(req.Body).ReadToEndAsync();
var puzzleSubmission = JsonSerializer.Deserialize<PuzzleSubmissionViewModel>(body, new JsonSerializerOptions { PropertyNamingPolicy = JsonNamingPolicy.CamelCase });
var correspondingRecord = await _captchaStorageService.LoadAsync(puzzleSubmission.Id);
...
bool isPuzzleSolved = _puzzleService.IsPuzzleSolved(...);
var response = new Response
{
IsSuccessful = isPuzzleSolved,
Message = isPuzzleSolved ? "The puzzle is solved" : "Sorry, time runs out or you didn't solve the puzzle"
};
return new OkObjectResult(response);
}
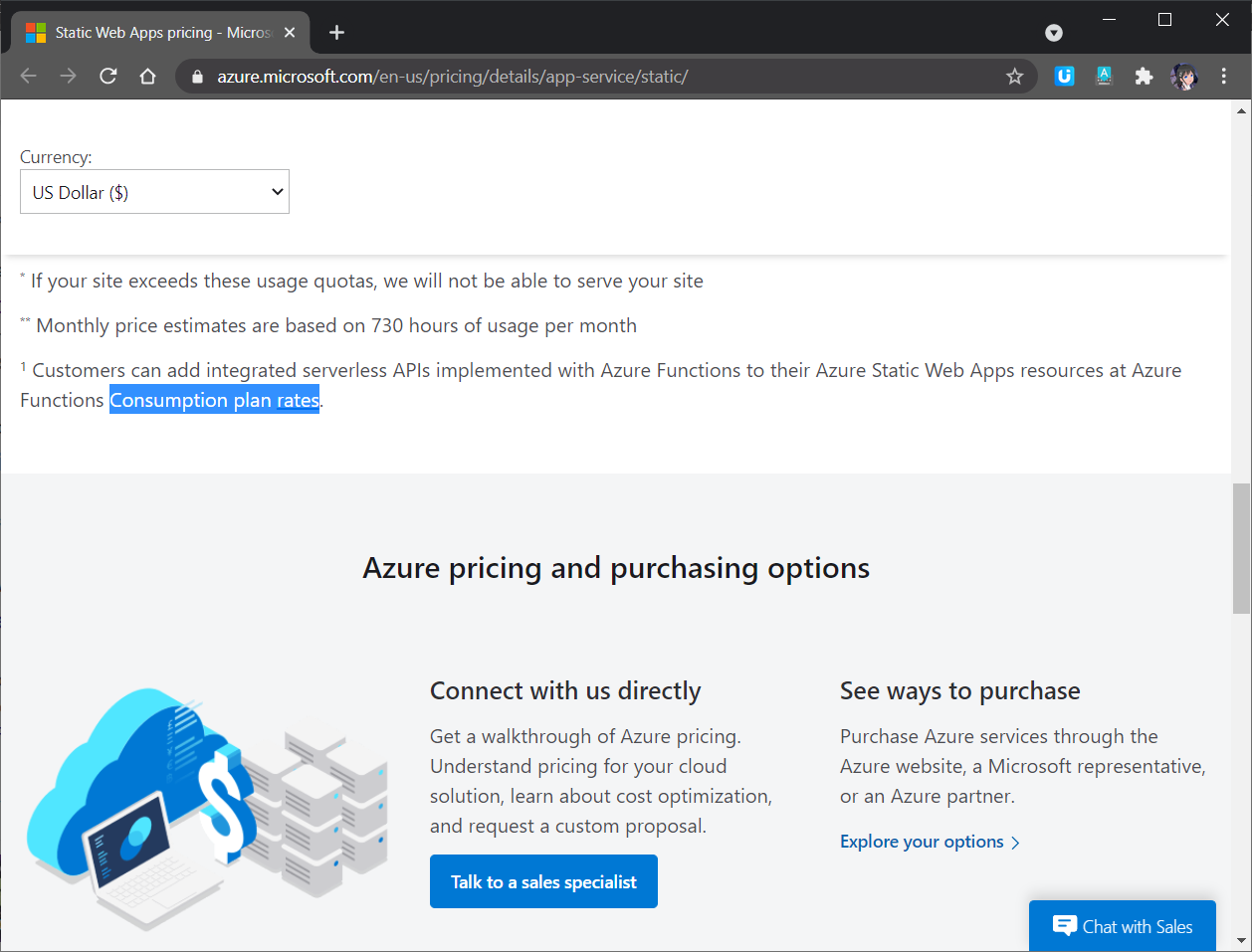
Since our API is hosted as Azure Function in Consumption Plan, as shown in the screenshot below, we need to note that our code in the Function will be in the serverless mode, i.e. it effectively scales out to meet whatever load it is seeing and scales down when code isn’t running.
The Azure Function managed by the Static Web App will be in Consumption Plan.
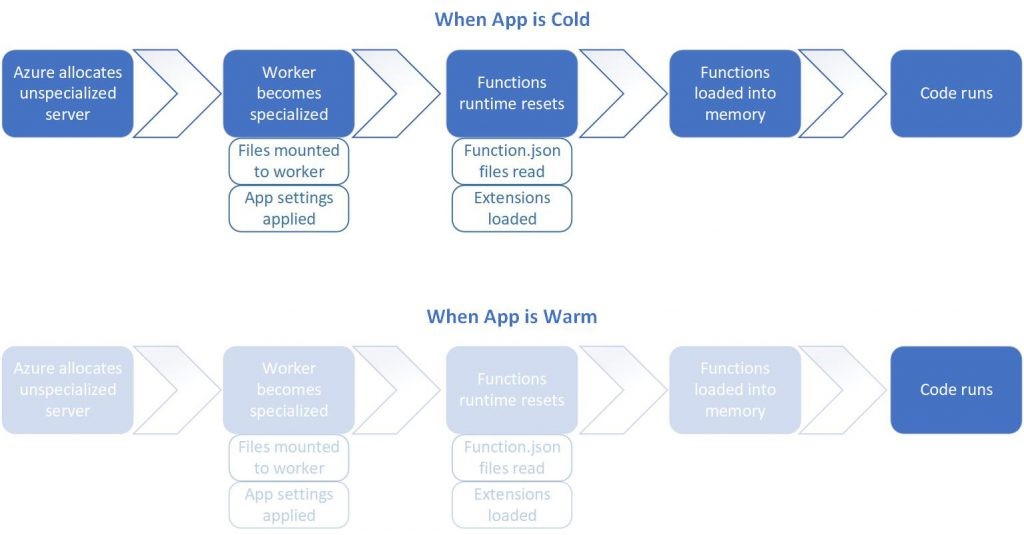
Latency will be there when Function is cold. (Image Source: Microsoft Azure Blog)
In this project, my friend feedbacked to me that he had encountered at least 15 seconds of latency to have the jigsaw puzzle loaded.
Blazor Frontend
Now we can move on to the frontend.
To show the jigsaw puzzle images when the page is loaded, we have the following code.
protected override async Task OnInitializedAsync()
{
var jigsawPuzzle = await http.GetFromJsonAsync("api/jigsaw-puzzle");
id = jigsawPuzzle.Id;
backgroundImage = "data:image/png;base64, " + jigsawPuzzle.BackgroundImage;
missingPieceImage = jigsawPuzzle.MissingPieceImage;
y = jigsawPuzzle.Y;
}
Take note that we don’t only get the two images but also the GUID of the jigsaw puzzle record in the Azure Table Storage so that later we can send back this information to the Azure Function for submission verification.
Here, we only return the y-axis value of the shaded area location because users are only allowed to drag the missing puzzle horizontally as discussed earlier. If you would like to increase the difficulty of the CAPTCHA by allowing users to drag the missing piece vertically as well, you can choose not to return the y-axis value.
We then have the following HTML to display the two images.
The Submit method is as follows which will feedback to users whether they solve the jigsaw puzzle correctly or not. Here I use a toast library for Blazor done by Chris Sainty, a Microsoft MVP.
private async Task Submit()
{
var submission = new PuzzleSubmissionViewModel
{
Id = id,
X = x
};
var response = await http.PostAsJsonAsync("api/jigsaw-puzzle", submission);
var responseMessage = await response.Content.ReadFromJsonAsync<Response>();
if (responseMessage.IsSuccessful)
{
toastService.ShowSuccess(responseMessage.Message);
}
else
{
toastService.ShowError(responseMessage.Message);
}
}
Now we can test how our app works!
Testing Locally
Before we can test locally, we need to provide the secrets and relevant settings to access Azure Blob Storage and Table Storage.
In addition, please remember to exclude local.settings.json from the source control.
In the Client project, since we are going to run our Api at port 7071, we shall let the Client know too. To do so, we first need to specify the base address for local in the Program.cs of the Client project.
builder.Services.AddScoped(sp => new HttpClient { BaseAddress = new Uri(builder.Configuration["API_Prefix"] ?? builder.HostEnvironment.BaseAddress) });
Then we can specify the value for API_Prefix in the appsettings.Development.json in the wwwroot folder.
{
"API_Prefix": "http://localhost:7071"
}
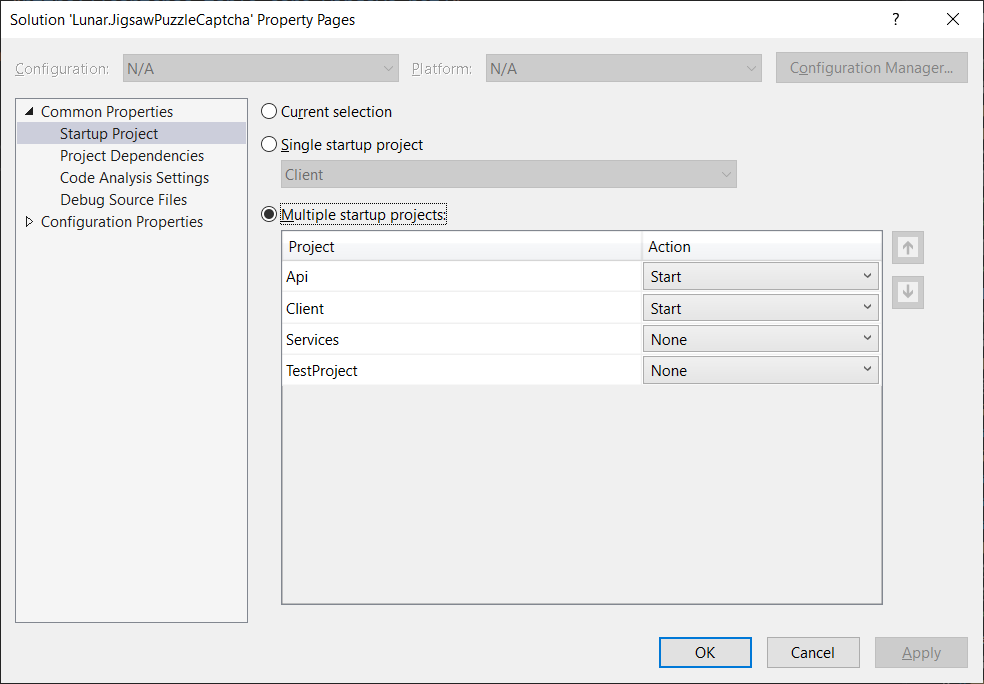
Finally, please also set both Api and Client projects as the Startup Project in the Visual Studio.
Setting multiple startup projects in Visual Studio.
Deploy to Azure Static Web App
After we have created an Azure Static Web Apps resource and bound it with a GitHub Actions which monitors our GitHub repository, the workflow will automatically build and deploy our app and its API to Azure every time we commit or create pull requests into the watched branch. The steps have been described in my previous blog post about Blazor on Azure Static Web App, so I won’t repeat it here.
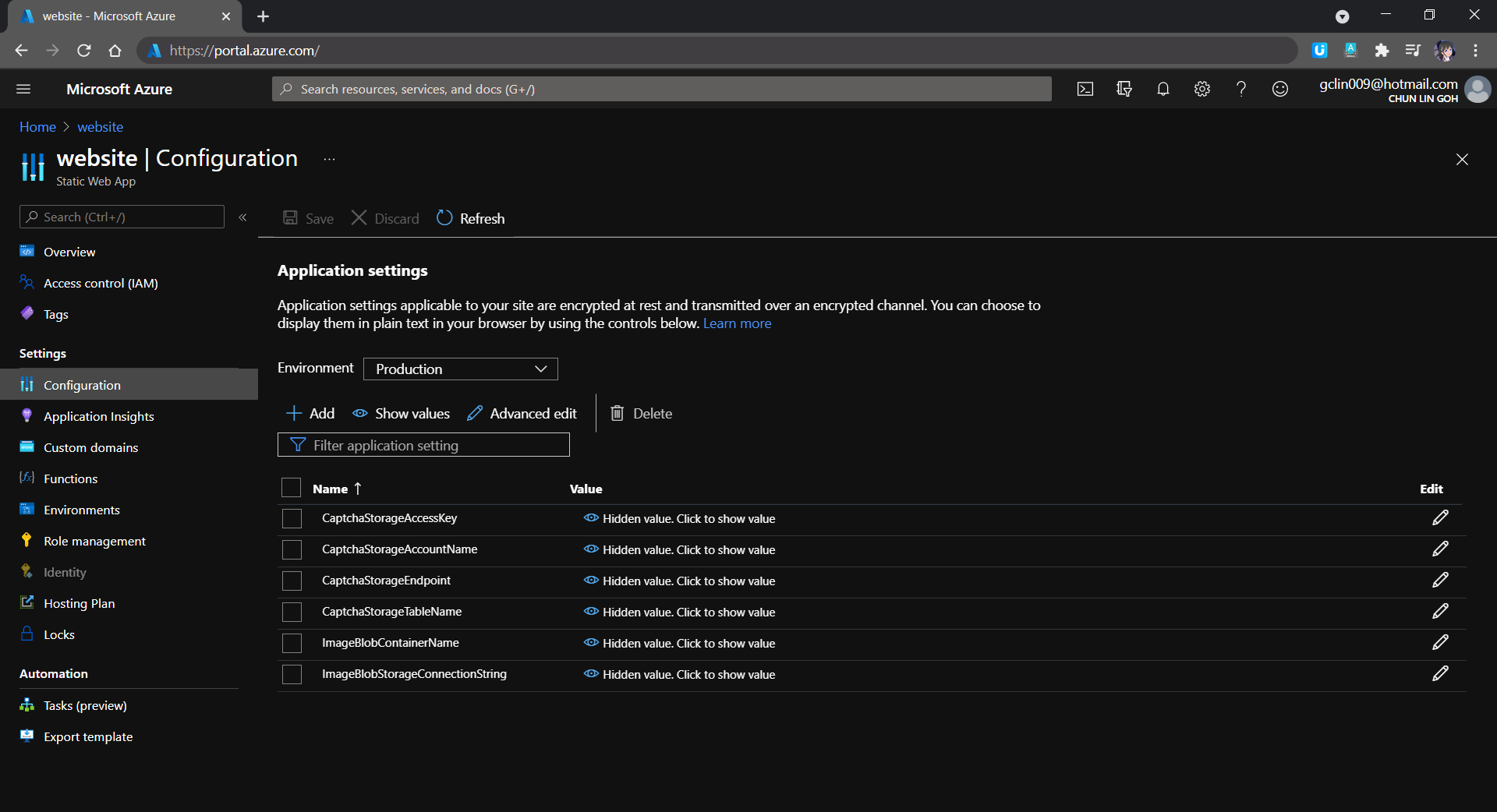
Since our API needs to have the information of secrets and connection settings to the Azure Storage, we need to specify them under Application Settings of the Azure Static Web App as well. The values will be accessible by API methods in the Azure Functions.
Managing the secrets in Application Settings.
Yup, that’s all for implementing a jigsaw puzzle CAPTCHA in .NET. Feel free to try it out on my Azure Static Web App and let me know your thoughts about it. Thank you!
Jigsaw puzzle CAPTCHA implementation on Blazor. (Try it here)
In this article, I will share how the website for Singapore .NET Developers Community and Azure Community is re-built as a Blazor web app and deployed to Azure.
The community website is very simple. It is merely a single-page website with some descriptions and photos about the community. Then it also has a section showing list of meetup videos from the community YouTube channels.
We will build the website as Blazor WebAssembly App.
Secondly, if we hope to have a similar UI template across all the web pages in the website, then we can define the HTML template under, for example, MainLayout.razor, as shown below. This template means that the header and footer sections can be shared across different web pages.
Finally, we simply need to define the @Body of each web page in their own Razor file, for example the Index.razor for the homepage.
In the Index.razor, we will fetch the data from a JSON file hosted on Azure Storage. The JSON file is periodically updated by Azure Function to fetch the latest video list from the YouTube channel of the community. Instead of using JavaScript, here we can simply write a C# code to do that directly on the Razor file of the homepage.
@code {
private List<VideoFeed> videoFeeds = new List<VideoFeed>();
protected override async Task OnInitializedAsync()
{
var allVideoFeeds = await Http.GetFromJsonAsync<VideoFeed[]>("...");
videoFeeds = allVideoFeeds.ToList();
}
public class VideoFeed
{
public string VideoId { get; set; }
public Channel Channel { get; set; }
public string Title { get; set; }
public string Description { get; set; }
public DateTimeOffset PublishedAt { get; set; }
}
public class Channel
{
public string Name { get; set; }
}
}
Publish to Azure Static Web App from GitHub
We will have our codes ready in a GitHub repo with the following structure.
.github/workflows
DotNetCommunity.Singapore
Client
(Blazor client project here)
Next, we can proceed to create a new Azure Static Web App where we will host our website at. In the first step, we can easily link it up with our GitHub account.
We need to specify the deployment details for the Azure Static Web App.
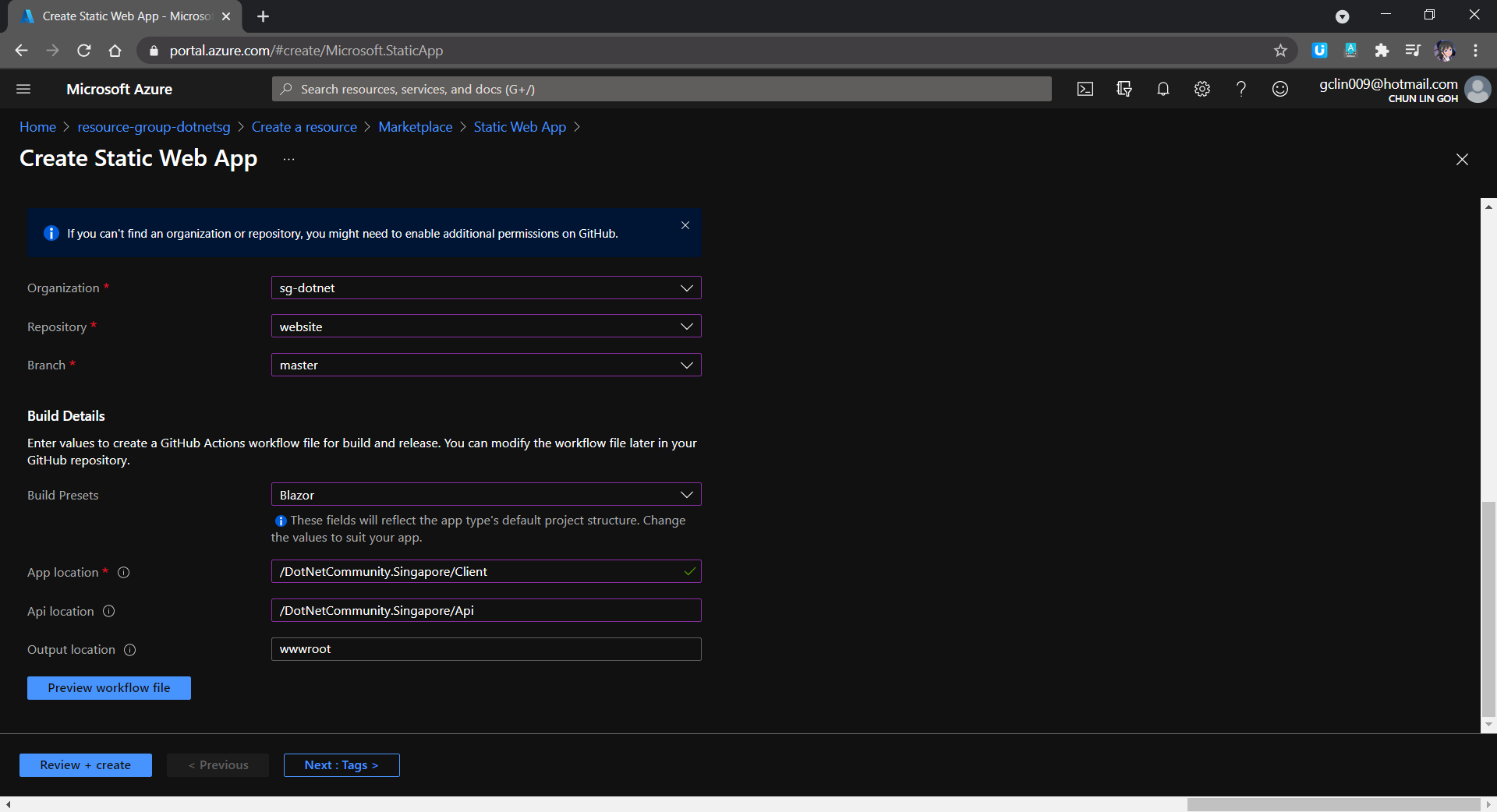
After that, we will need to provide the Build details so that a GitHub workflow will be automatically generated. That is a GitHub Actions workflow that builds and publishes our Blazor web app. Hence, we must specify the corresponding folder paths within our GitHub repo, as shown in the screenshot below.
In the Build Details, we must setup the folder path correctly.
The “App location” is to point to the location of the source code for our Blazor web app. For the “Api location”, although we are not using it in our Blazor project now, we can still set it as follows so that in the future when we can easily setup the Api folder.
With this setup ready, whenever we update the codes in our GitHub repo via commits or pull requests, our Blazor web app will be built and deployed.
Our Blazor web app is being built in GitHub Actions.
For root domain, which is “dotnet.sg” in our case, by right we can do it in Azure Static Web App by using TXT record validation and an ALIAS record.
Take note that we can only create an ALIAS record if our domain provider supports it.
However, since there is currently no support of ALIAS or ANAME records in the domain provider that I am using, I have no choice but to have another Azure Function for binding “dotnet.sg”. This is because currently there is no IP address given in Azure Static Web App but there are IP address and Custom Domain Verification ID available in Azure Function. With these two information, we can easily map an A Record to our root domain, i.e. “dotnet.sg”.
Please take note that A Records are not supported for Consumption-based Function Apps. We must pay for the “App Service Plan” instead.
IP address and Custom Domain Verification ID on Azure Function. The root domain here is also SSL enabled.
With all these ready, we can finally get our community website up and running at dotnet.sg.
Welcome to the Singapore .NET/Azure Developer Community at dotnet.sg.
Export SSL Certificate For Azure Function
This step is optional. I need to go through this step because I have a Azure App Service managed certificate in one subscription but Azure Function in another subscription. Hence, I need to export the SSL certificate out and then import it back to another subscription.
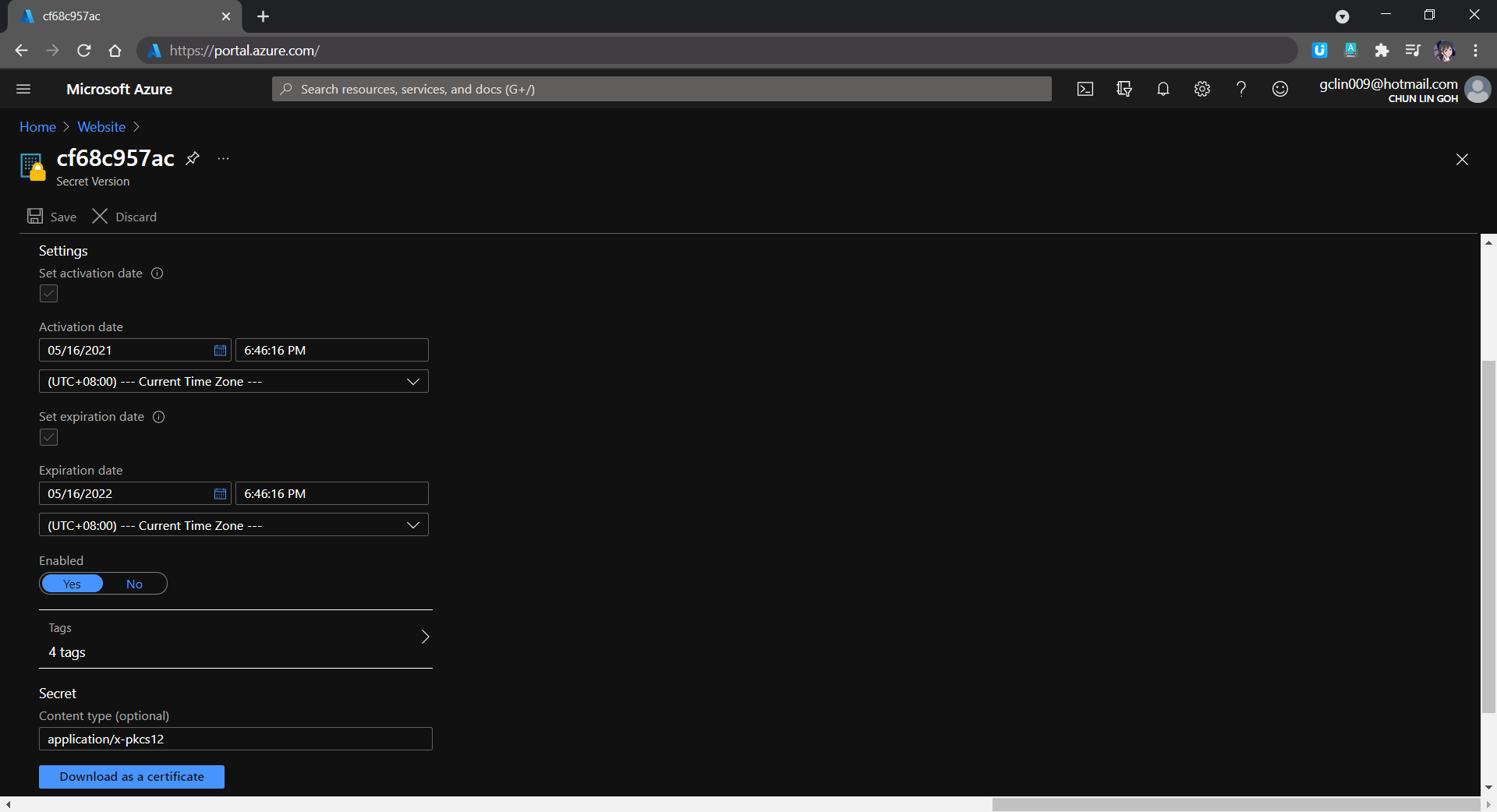
We can export certificate from the Key Vault Secret.
In the Key Vault Secret screen, we then need to choose the correct secret version and download the certificate, as shown in the following screenshot.
We will be prompted for a password after executing the first command. We simply press enter to proceed because the certificate, as mentioned above, has no password.
OpenSSL command prompt.
With this step done, I finally can import the cert to the Azure Function in another subscription.
Yup, that’s all for hosting our community website as a Blazor web app on Azure Static Web App!