KOSD, or Kopi-O Siew Dai, is a type of Singapore coffee that I enjoy. It is basically a cup of coffee with a little bit of sugar. This series is meant to blog about technical knowledge that I gained while having a small cup of Kopi-O Siew Dai.
During a late dinner with my friend on 12 January last month, he commented that he encountered a very serious performance problem in retrieving data from Cosmos DB (pka DocumentDB). It’s quite strange because, in our IoT project which also stores millions of data in Cosmos DB, we never had this problem.
Two weeks later, on 27 January, he happily showed me his improved version of the code which could query the data in about one to two seconds.
Yesterday, after having a discussion, we further improved the code. Hence, I’d like to write down this learning experience here.
Due to the fact that we couldn’t demonstrate using the real project code, I thus created a sample project getting data from database and collection on my personal Azure Cosmos DB account. The database contains one collection which has 23,967 records of Student data.
The Student class and the BaseEntity class that it inherits from are as follows.
public class Student : BaseEntity
{
public string Name { get; set; }
public int Age { get; set; }
public string Description { get; set; }
}
public abstract class BaseEntity
{
[JsonProperty(PropertyName = "id")]
public string Id { get; set; }
public string Type { get; set; }
public DateTime CreatedAt { get; set; } = DateTime.Now;
}
You may wonder why I have Type defined.
Type and Cost Saving
The reason of having Type is that, before DocumentDB was rebranded as Cosmos DB in May 2017, the DocumentDB pricing is based on collections. Hence, the more collection we have in the database, the more we need to pay.
DocumentDB was billed per collection in the past. (Source: Stack Overflow)
To overcome that, we squeeze the different types of entities in the same collection. So, in the example above, let’s say we have three classes — Students, Classroom, Teacher that inherit from BaseEntity, then we will put the data of the three classes in the same collection.
Then here comes a problem: How do we know which document in the collection is Student, Classroom or Teacher? There is where the property Type will help us. So in our example above, the possible value for Type will be Student, Classroom, and Teacher.
Hence, when we add a new document through repository design pattern, we have the following method.
We used the following code to retrieve data of a class from the collection.
public async Task<IEnumerable<T>> GetAllAsync(Expression<Func<T, bool>> predicate = null)
{
var query = _documentDbClient.CreateDocumentQuery<T>(UriFactory.CreateDocumentCollectionUri(_databaseId, _collectionId));
var documentQuery = (predicate != null) ?
(query.Where(predicate)).AsDocumentQuery():
query.AsDocumentQuery();
var results = new List<T>();
while (documentQuery.HasMoreResults)
{
results.AddRange(await documentQuery.ExecuteNextAsync<T>());
}
return results.Where(x => x.Type == typeof(T).Name).ToList();
}
This query will run very slow because the line where it filters the class is after querying data from the collection. Hence, in the documentQuery, it may already contain data of three classes (Student, Classroom, and Teacher).
Improved Version of Query
So one obvious way is to move the line of filtering by Type above. The improved version of code now looks as such.
public async Task<IEnumerable<T>> GetAllAsync(Expression<Func<T, bool>> predicate = null)
{
var query = _documentDbClient
.CreateDocumentQuery<T>(UriFactory.CreateDocumentCollectionUri(_databaseId, _collectionId))
.Where(x => x.Type == typeof(T).Name);
var documentQuery = (predicate != null) ?
(query.Where(predicate)).AsDocumentQuery():
query.AsDocumentQuery();
var results = new List<T>();
while (documentQuery.HasMoreResults)
{
results.AddRange(await documentQuery.ExecuteNextAsync<T>());
}
return results;
}
By doing so, we managed to reduce the query time significantly because all the actual filtering will be done at Cosmos DB side. For example, there was one query I managed to reduce the query time of it from 1.38 minutes to 3.42 seconds using the 23,967 records of Student data.
Multiple Predicates
The code above however has a disadvantage. It cannot accept multiple predicates.
I thus changed it to be as follows so that it returns IQueryable.
This has another inconvenience is there whenever I call GetAll, I need to remember to load the data with HasMoreResults as shown in the code below.
var studentDocuments = _repoDocumentDb.GetAll()
.Where(s => s.Age == 8)
.Where(s => s.Name.Contains("Ahmad"))
.AsDocumentQuery();
var results = new List<T>();
while (studentDocuments.HasMoreResults)
{
results.AddRange(await studentDocuments.ExecuteNextAsync<T>());
}
Conclusion
This is just an after-dinner discussion about Cosmos DB between my friend and me. If you have any better idea of designing repository for Cosmos DB (pka DocumentDB), please let us know. =)
During my first job after finishing my undergraduate degree in NUS, I worked in a local startup which was then the largest bus ticketing portal in Southeast Asia. In 2014, I worked with a senior to successfully migrate the whole system from on-premise to Microsoft Azure Virtual Machines, which is the IaaS option. Maintaining the virtual machines is a painful experience because we need to setup the load balancing with Traffic Manager, database mirroring, database failover, availability set, etc.
In 2015, when I first worked in Singapore Changi Airport, with the support of the team, we made use of PaaS technologies such as Azure Cloud Services, Azure Web Apps, and Azure SQL, we successfully expanded our online businesses to 7 countries in a short time. With the help of PaaS option in Microsoft Azure, we can finally have a more enjoyable working life.
Azure Functions
Now, in 2017, I decided to explore Azure Functions.
Azure Functions allows developers to focus on the code for only the problem they want to solve without worrying about the infrastructure like we do in Azure Virtual Machines or even the entire applications as we do in Azure Cloud Services.
There are two important benefits that I like in this new option. Firstly, our development can be more productive. Secondly, Azure Functions has two pricing models: Consumption Plan and App Service Plan, as shown in the screenshot below. The Consumption Plan lets us pay per execution and the first 1,000,000 executions are free!
Two hosting plans in Azure Functions: Consumption Plan vs. App Service Plan
After setting up the Function App, we can choose “Quick Start” to have a simpler user interface to get started with Azure Function.
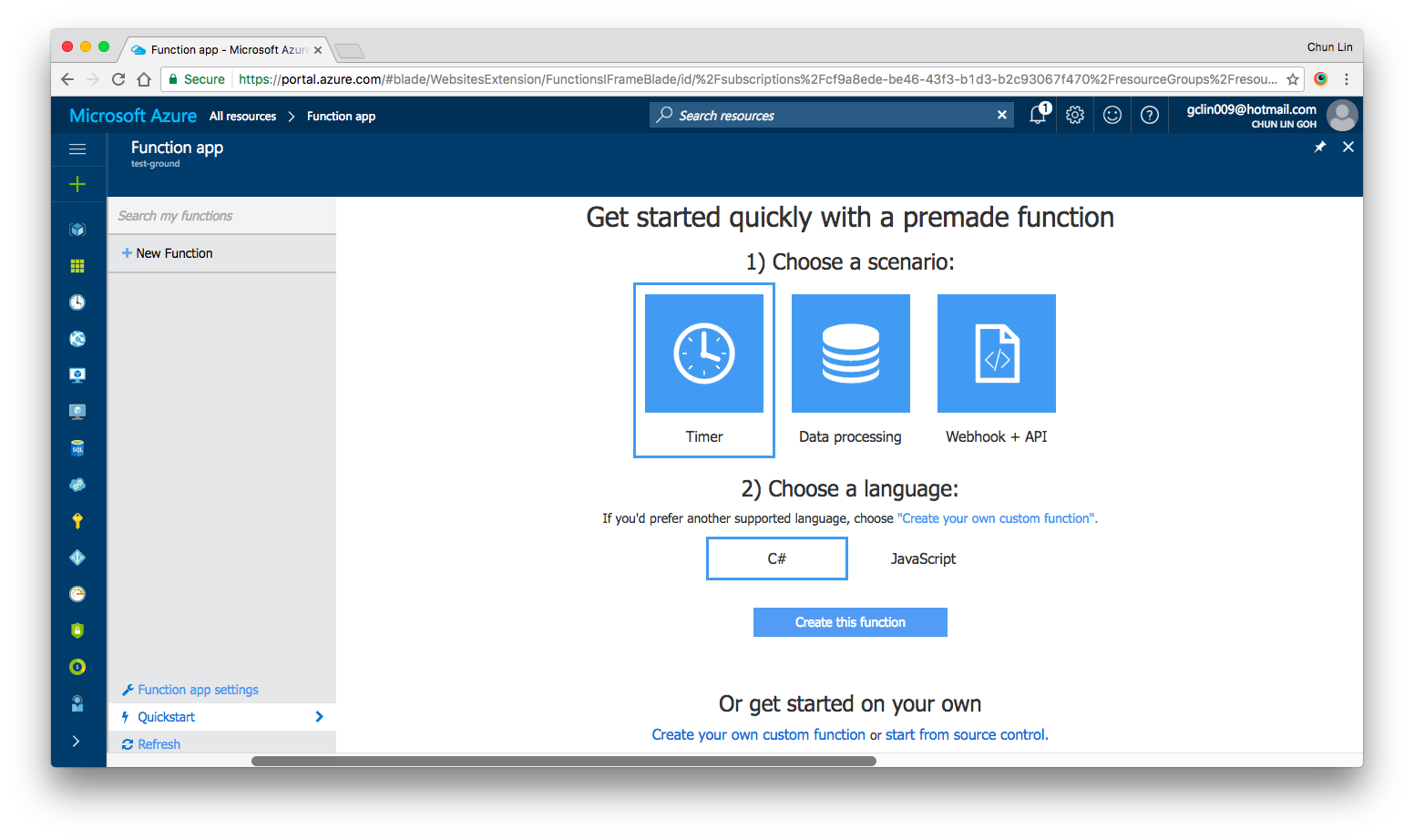
Under “Quick Start” section, there are three triggers available for us to choose, i.e. Timer, Data Processing, and Webhook + API. Today, I’ll only talk about Timer. We will see how we can achieve the scheduler functionality on Microsoft Azure.
Quick Start page in Azure Function.
Timer Trigger
Timer Trigger will execute the function according to a schedule. The schedule is defined using CRON expression. Let’s say if we want our function to be executed every four hours, we can write the schedule as follows.
Similar to the usual Azure Web App, the default time zone used in Azure Functions is also UTC. Hence, if we would like to change it to use another timezone, what we need to do is just add the WEBSITE_TIME_ZONE application setting in the Function App.
Companion File: function.json
So, where do we set the schedule? The answer is in a special file called function.json.
The name attribute is to specify the name of the parameter used in the C# function later. It is used for the bound data in the function.
The type attribute specifies the binding time. Our case here will be timerTrigger.
The direction attribute indicates whether the binding is for receiving data into the function (in) or sending data from the function (out). For scheduler, the direction will be “in” because later in our C# function, we can actually retrieve info from the myTimer parameter.
Finally, the schedule attribute will be where we put our schedule CRON expression at.
#r "Newtonsoft.Json"
using System;
using Newtonsoft.Json;
...
public static async Task Run(TimerInfo myTimer, TraceWriter log)
{
...
}
Assemblies in .csx File
Same as how we always did in C# project, when we need to import the namespaces, we just need to use the using clause. For example, in our case, we need to process the Json file, so we need to make use of the library Newtonsoft.Json.
using Newtonsoft.Json;
To reference external assemblies, for example in our case, Newtonsoft.Json, we just need to use the #r directive as follows.
For other assemblies, we need to upload the assembly file, for example MyAssembly.dll, into a bin folder relative to the function first. Only then we can reference is as follows.
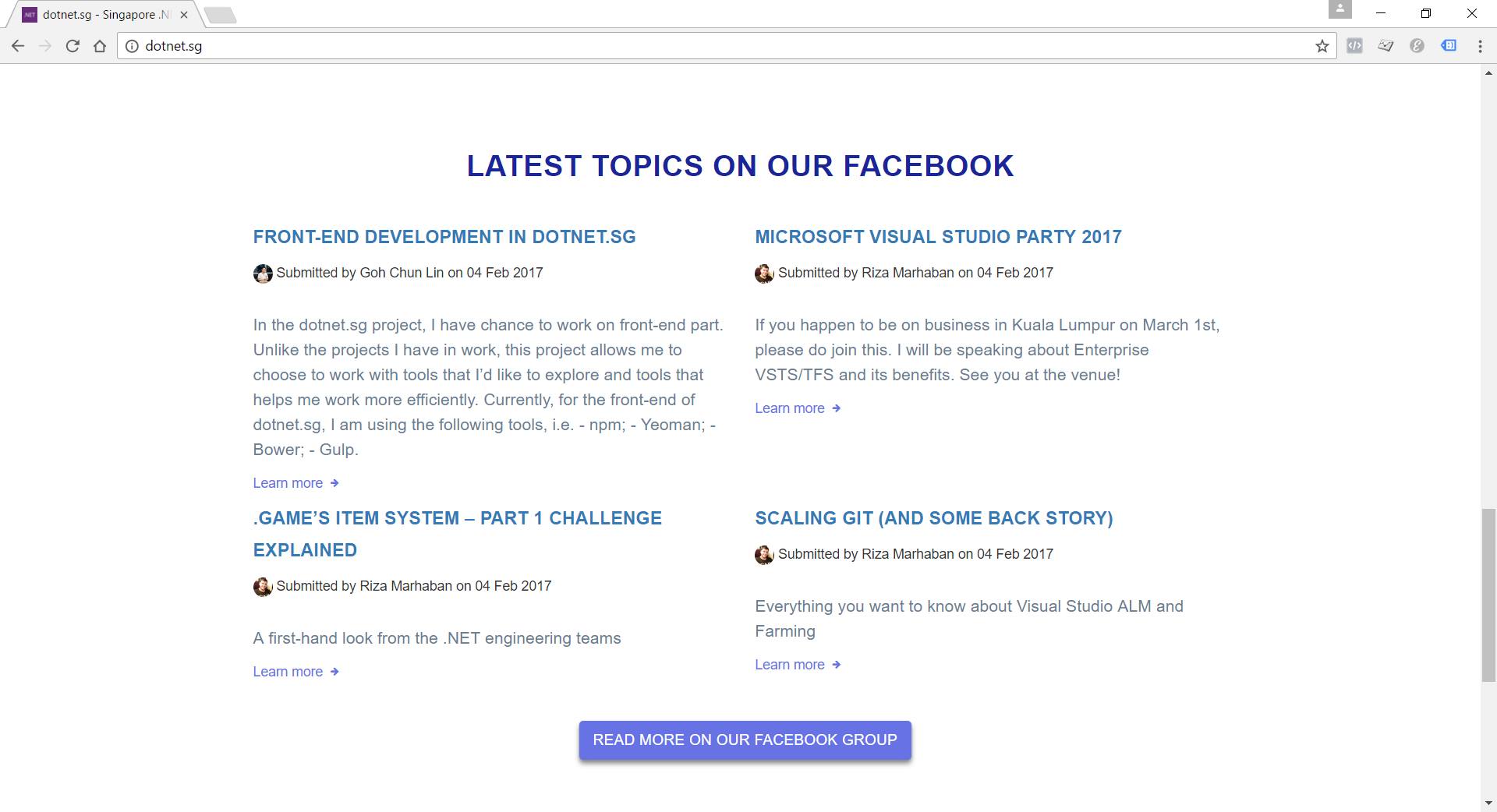
This section will display the top four latest Facebook posts pulled by Azure Function.
For our case, the purpose of Azure Function is to process the Facebook Group feeds and then store the feeds somewhere for later use. The “somewhere” here is DocumentDB.
To gets the inputs from DocumentDB, we first need to have 2nd binding specified in the functions.json as follows.
In the DocumentDB input binding above, the name attribute is, same as previous example, used to specify the name of the parameter in the C# function.
The databaseName and collectionName attributes correspond to the names of the database and collection in our DocumentDB, respectively. The id attribute is the Document Id of the document that we want to retrieve. In our case, we store all the Facebook feeds in one document, so we specify the Document Id in the binding directly.
The connection attribute is the name of the Azure Function Application Setting storing the connection string of the DocumentDB account endpoint. Yes, Azure Function also has Application Settings available. =)
Finally, the direction attribute must be “in”.
We can then now enhance our Run method to include inputs from DocumentDB as follows. What it does is basically just reading existing feeds from the document and then update it with new feeds found in the Singapore .NET Facebook Group
#r "Newtonsoft.Json"
using System;
using Newtonsoft.Json;
...
private const string SG_DOT_NET_COMMUNITY_FB_GROUP_ID = "1504549153159226";
public static async Task Run(TimerInfo myTimer, dynamic inputDocument, TraceWriter log)
{
string sgDotNetCommunityFacebookGroupFeedsJson =
await GetFacebookGroupFeedsAsJsonAsync(SG_DOT_NET_COMMUNITY_FB_GROUP_ID);
...
var existingFeeds = JsonConvert.DeserializeObject(inputDocument.ToString());
// Processing the Facebook Group feeds here...
// Updating existingFeeds here...
inputDocument.data = existingFeeds.Feeds;
}
Besides getting input from DocumentDB, we can also have DocumentDB output binding as follows to, for example, write a new document to DocumentDB database.
We don’t really use this in our dotnet.sg case. However, as we can see, there are only two major differences between DocumentDB input and output bindings.
Firstly, we have a new createIfNotExists attribute which specify whether to create the DocumentDB database and collection if they don’t exist or not.
Secondly, we will have to set the direction attribute to be “out”.
Then in our function code, we just need to have a new parameter with “out object outputDocument” instead of “in dynamic inputDocument”.
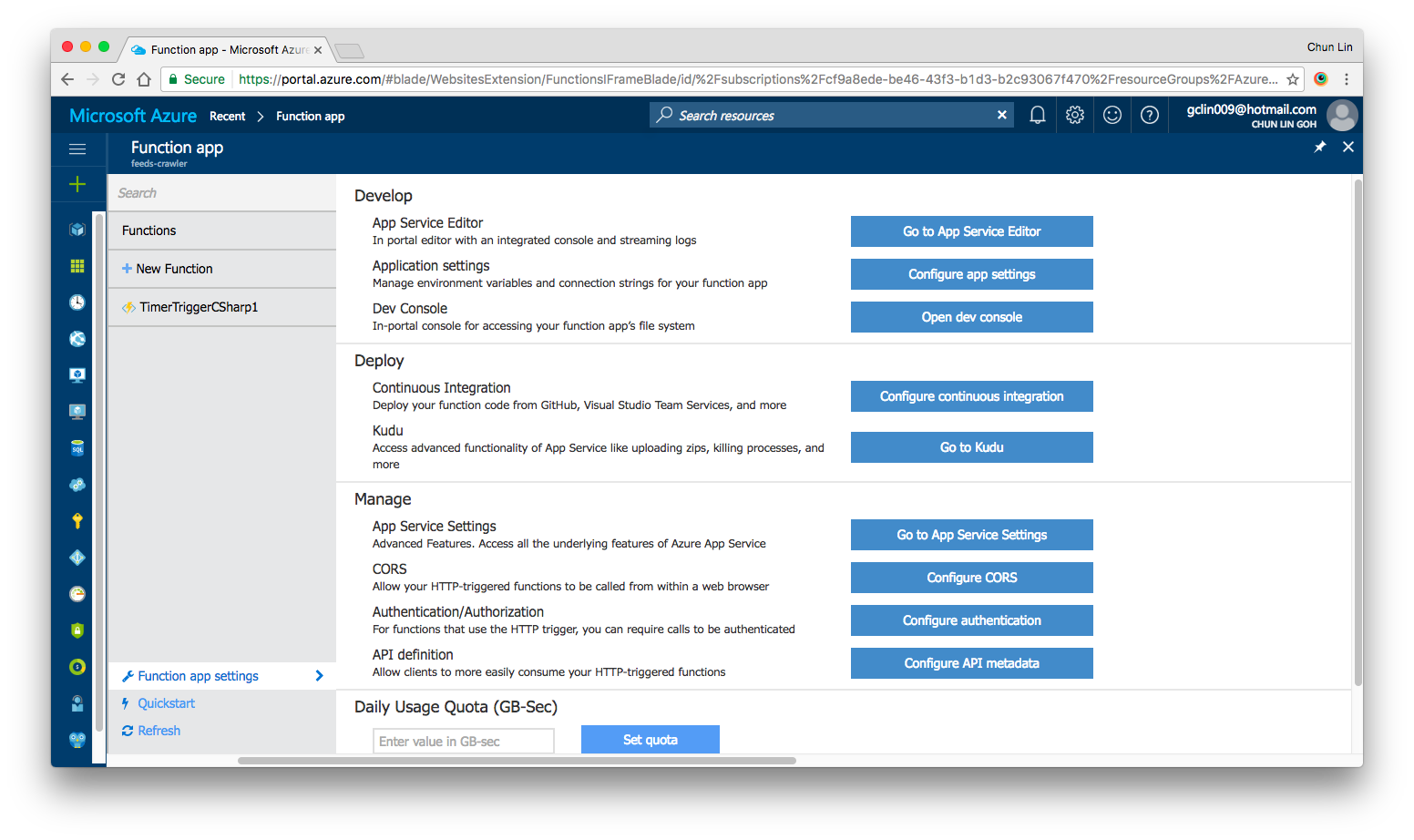
Yes, there are our familiar features such as Application Settings, Continuous Integration, Kudu, etc. in Azure Functions as well. All of them can be found under “Function App Settings” section.
Azure Function App Settings
As what we have been doing in Azure Web Apps, we can also set the timezone, store the App Secrets in the Function App Settings.
Deployment of Azure Functions with Github
We are allowed to link the Azure Function with variety of Deployment Options, such as Github, to enable the continuous deployment option too.
There is one thing that I’d like to highlight here is that if you are also starting from setting up your new Azure Function via Azure Portal, then when in the future you setup the continuous deployment for the function, please make sure that you first create a folder having the same name as the name of your Azure Function. Then all the files related to the function needs to be put in the folder.
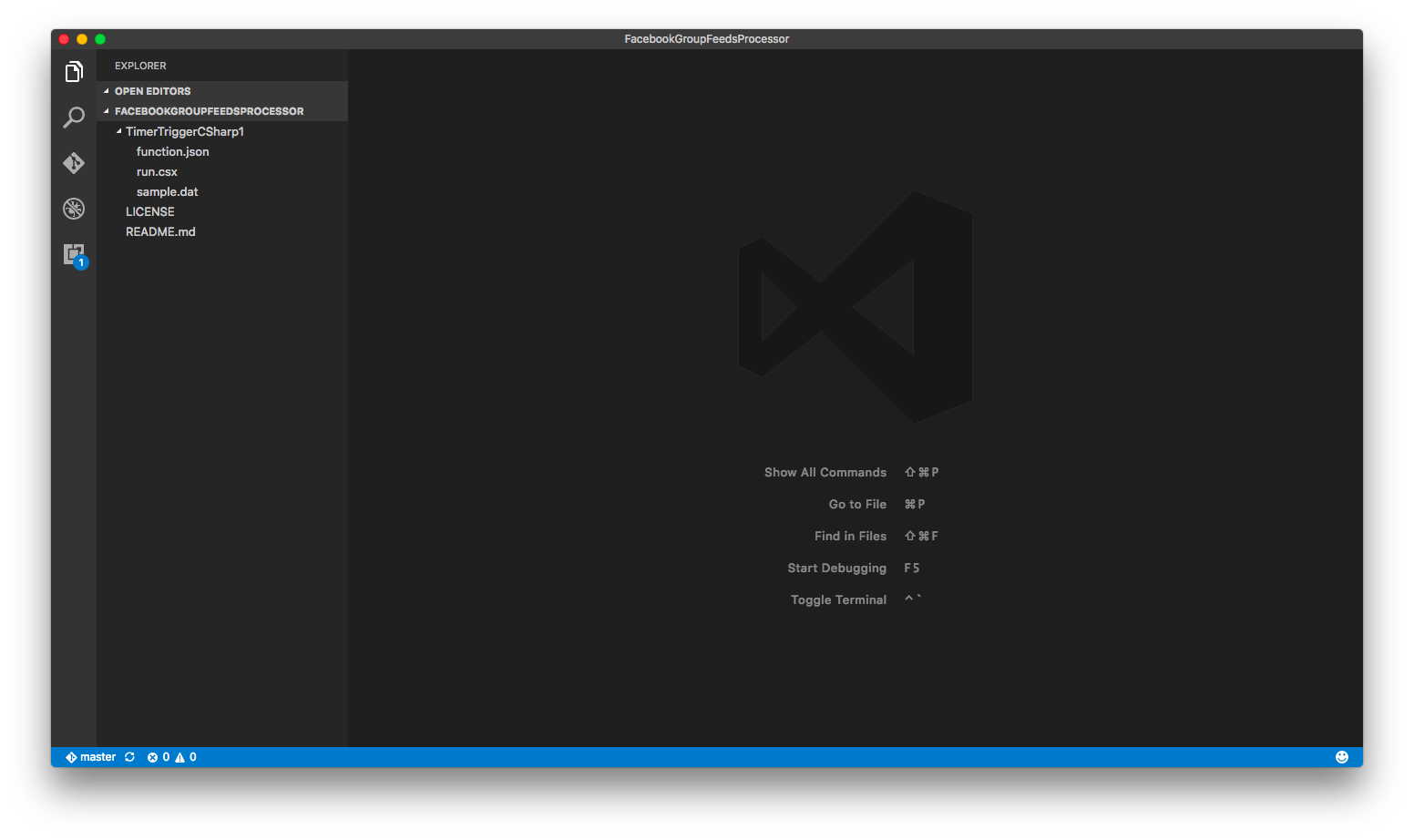
For example, in dotnet.sg case, we have the Azure Function called “TimerTriggerCSharp1”. we will have the following folder structure.
Folder structure of the TimerTriggerCsharp1.
When I first started, I made a mistake when I linked Github with Azure Function. I didn’t create the folder with the name “TimerTriggerCSharp1”, which is the name of my Azure Function. So, when I deploy the code via Github, the code in the Azure Function on the Azure Portal is not updated at all.
In fact, once the Continuous Deployment is setup, we are no longer able to edit the code directly on the Azure Portal. Hence, setting up the correct folder structure is important.
Read only once we setup the Continuous Deployment in Azure Function.
If you would like to add in more functions, simply create new folders at the same level.
Conclusion
Azure Function and the whole concept of Serverless Architecture are still very new to me. However, what I like about it is the fact that Azure Function allows us to care about the codes to solve a problem without worrying about the whole application and infrastructure.
In addition, we are also allowed to solve the different problems using the programming language that best suits the problem.
Finally, Azure Function is cost-saving because we can choose to pay only for the time our code is being executed.
If you would like to learn more about Azure Functions, here is the list of references I use in this learning journey.